Variance-Adaptive Muon: Accelerating LLM Pretraining with NSR-Modulated and Variance-Scaled Momentum
作者: Jingru Li, Yibo Fan, Huan Li
分类: cs.LG
发布日期: 2026-01-21
💡 一句话要点
提出方差自适应Muon优化器,加速LLM预训练并降低验证损失。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练 优化器 Muon 方差自适应
📋 核心要点
- LLM预训练计算成本高昂,优化器效率至关重要,现有优化器在收敛速度和最终性能上存在提升空间。
- 论文提出方差自适应Muon优化器,通过噪声-信号比调制(Muon-NSR)和方差缩放(Muon-VS)来改进动量更新。
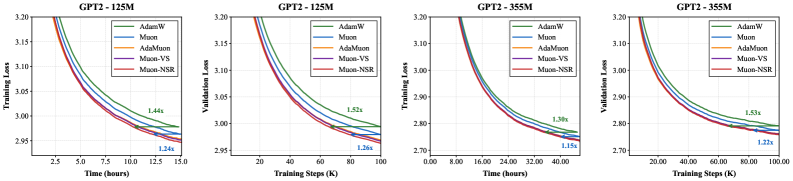
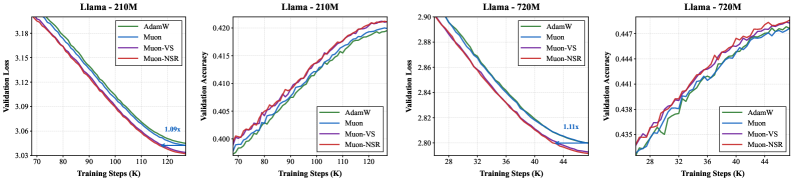
- 实验表明,Muon-NSR和Muon-VS在GPT-2和LLaMA预训练中,相较于AdamW和Muon,均能加速收敛并降低验证损失。
📝 摘要(中文)
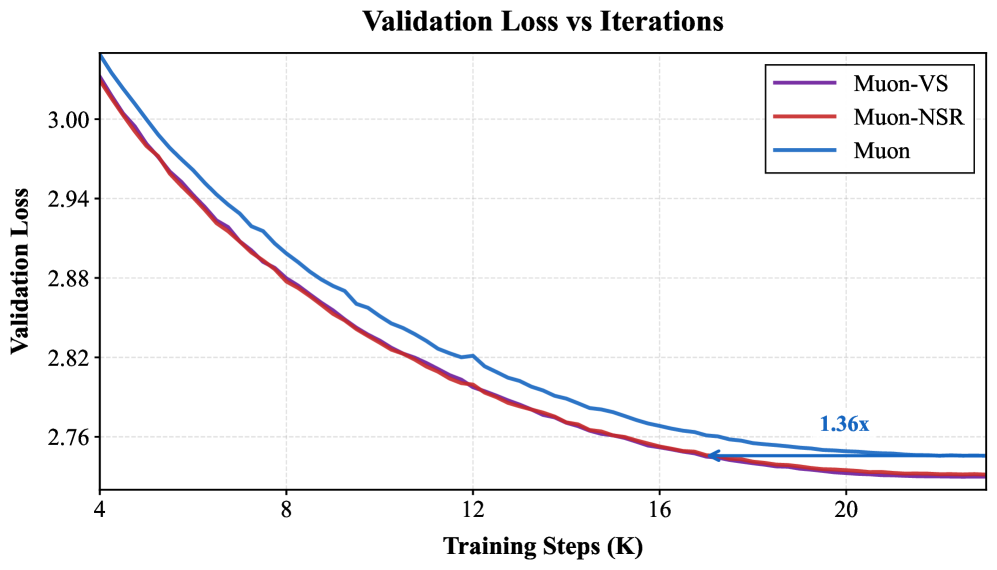
大型语言模型(LLMs)在各种自然语言处理(NLP)任务中表现出色,但预训练的计算需求很高,因此优化器的效率是一个重要的实际考虑因素。Muon通过正交动量更新加速LLM预训练,正交动量更新充当逐元素符号算子的矩阵模拟。受Adam是一种方差自适应符号更新算法的最新观点的启发,我们提出了Muon的两个变体,Muon-NSR和Muon-VS,它们在正交化之前将方差自适应归一化应用于动量。Muon-NSR应用噪声-信号比(NSR)调制,而Muon-VS执行基于方差的缩放,而无需引入额外的超参数。在GPT-2和LLaMA预训练上的实验表明,我们提出的方法加速了收敛,并且始终比有竞争力的、经过良好调整的AdamW和Muon基线实现了更低的验证损失。例如,在LLaMA-1.2B模型上,根据最新的基准测试,相对于经过良好调整的Muon,Muon-NSR和Muon-VS将达到目标验证损失所需的迭代次数减少了1.36倍。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)预训练过程中计算资源消耗大、训练效率低下的问题。现有的优化器,如AdamW和Muon,在收敛速度和最终模型性能上仍有提升空间,尤其是在处理大规模数据集和模型时,优化器的效率直接影响训练时间和成本。
核心思路:论文的核心思路是借鉴Adam优化器中方差自适应的思想,并将其融入到Muon优化器的动量更新过程中。Muon通过正交动量更新来加速训练,而论文提出的Muon-NSR和Muon-VS则进一步利用数据的方差信息来调整动量,从而更有效地引导模型参数更新。这样设计的目的是使优化器能够更好地适应不同参数的更新幅度,提高收敛速度和最终性能。
技术框架:整体框架基于Muon优化器,主要改进在于动量更新阶段。首先计算梯度,然后计算动量的正交分量。关键在于,在正交化之前,对动量进行方差自适应的归一化处理。Muon-NSR使用噪声-信号比(NSR)来调制动量,而Muon-VS则直接基于方差进行缩放。最后,使用调整后的动量更新模型参数。
关键创新:最重要的技术创新点在于将方差自适应的思想引入到Muon优化器中,提出了Muon-NSR和Muon-VS两种变体。与原始Muon相比,这两种方法能够更好地利用数据的统计信息来调整动量,从而提高优化效率。与AdamW相比,Muon系列优化器利用正交动量更新,在理论上具有更好的收敛性质。
关键设计:Muon-NSR的关键设计在于噪声-信号比(NSR)的计算和应用。NSR被用来调制动量,从而减小噪声的影响,提高更新的稳定性。Muon-VS的关键设计在于直接基于方差进行缩放,避免了引入额外的超参数,简化了调参过程。这两种方法都在正交化之前对动量进行处理,保证了Muon优化器的正交性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在LLaMA-1.2B模型上,Muon-NSR和Muon-VS相较于经过良好调整的Muon,将达到目标验证损失所需的迭代次数减少了1.36倍。此外,在GPT-2和LLaMA的预训练任务中,Muon-NSR和Muon-VS均取得了比AdamW和原始Muon更低的验证损失,证明了其优越的性能。
🎯 应用场景
该研究成果可广泛应用于各种大型语言模型的预训练任务中,尤其是在计算资源有限的情况下,能够显著加速模型训练,降低训练成本。此外,该方法还可以应用于其他深度学习模型的训练,具有一定的通用性。未来,可以进一步探索方差自适应方法在优化器设计中的应用,以提高模型训练的效率和性能。
📄 摘要(原文)
Large Language Models (LLMs) achieve competitive performance across diverse natural language processing (NLP) tasks, yet pretraining is computationally demanding, making optimizer efficiency an important practical consideration. Muon accelerates LLM pretraining via orthogonal momentum updates that serve as a matrix analogue of the element-wise sign operator. Motivated by the recent perspective that Adam is a variance-adaptive sign update algorithm, we propose two variants of Muon, Muon-NSR and Muon-VS, which apply variance-adaptive normalization to momentum before orthogonalization. Muon-NSR applies noise-to-signal ratio (NSR) modulation, while Muon-VS performs variance-based scaling without introducing additional hyperparameters. Experiments on GPT-2 and LLaMA pretraining demonstrate that our proposed methods accelerate convergence and consistently achieve lower validation loss than both competitive, well-tuned AdamW and Muon baselines. For example, on the LLaMA-1.2B model, Muon-NSR and Muon-VS reduce the iterations required to reach the target validation loss by $1.36\times$ relative to the well-tuned Muon following the recent benchmark.