Counterfactual Modeling with Fine-Tuned LLMs for Health Intervention Design and Sensor Data Augmentation
作者: Shovito Barua Soumma, Asiful Arefeen, Stephanie M. Carpenter, Melanie Hingle, Hassan Ghasemzadeh
分类: cs.LG
发布日期: 2026-01-21
💡 一句话要点
利用微调LLM进行健康干预设计和传感器数据增强的反事实建模
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 反事实解释 大型语言模型 健康干预设计 数据增强 数字健康 模型微调 可解释性
📋 核心要点
- 现有反事实生成方法缺乏灵活性,难以产生临床可操作且语义连贯的干预建议。
- 通过微调大型语言模型,生成高质量的反事实解释,用于健康干预设计和数据增强。
- 实验表明,微调的LLaMA-3.1-8B生成反事实的合理性和有效性高,且数据增强能显著恢复分类器性能。
📝 摘要(中文)
反事实解释(CFEs)通过识别改变机器学习模型预测所需的最小、可操作的改变,提供了以人为中心的解释性。因此,CFEs可以被用作(i)异常预防的干预措施和(ii)训练鲁棒模型的增强数据。我们使用大型语言模型(LLMs)对CF生成进行了全面的评估,包括GPT-4(零样本和少样本)和两个开源模型——BioMistral-7B和LLaMA-3.1-8B,包括预训练和微调配置。使用多模态AI-READI临床数据集,我们从三个维度评估CFEs:干预质量、特征多样性和增强有效性。微调的LLM,特别是LLaMA-3.1-8B,生成具有高合理性(高达99%)、强有效性(高达0.99)和现实的、行为可修改的特征调整的CFEs。当在受控的标签稀缺设置下用于数据增强时,LLM生成的CFEs显著恢复了分类器的性能,在三种稀缺场景中平均恢复了20%的F1分数。与基于优化的基线(如DiCE、CFNOW和NICE)相比,LLM提供了一种灵活的、模型无关的方法,可以生成更具临床可操作性和语义连贯性的反事实。总的来说,这项工作展示了LLM驱动的反事实在基于传感器的数字健康中用于可解释的干预设计和数据高效的模型训练的潜力。
🔬 方法详解
问题定义:论文旨在解决在数字健康领域,如何利用反事实解释(CFEs)进行有效的健康干预设计和数据增强的问题。现有的反事实生成方法,例如基于优化的方法(DiCE, CFNOW, NICE),通常缺乏灵活性,难以生成临床上可操作且语义连贯的反事实解释,并且在数据稀缺的情况下,模型训练效果不佳。
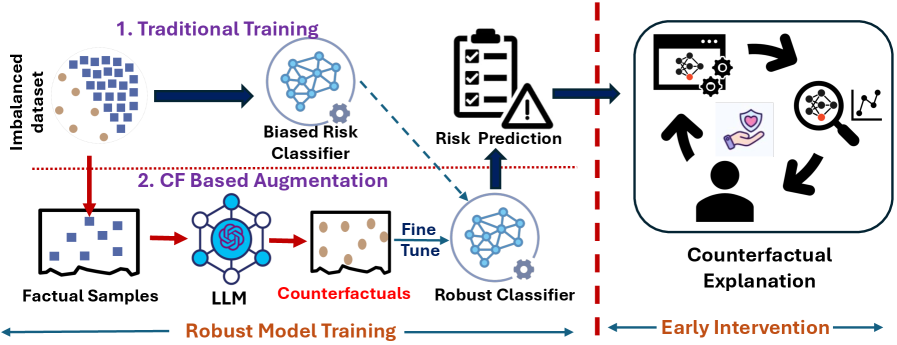
核心思路:论文的核心思路是利用大型语言模型(LLMs)的强大生成能力和语义理解能力,通过微调LLM,使其能够生成高质量的反事实解释。这些反事实解释不仅要具有合理性和有效性,还要能够提供可操作的干预建议,并且能够用于数据增强,从而提高模型在数据稀缺情况下的性能。
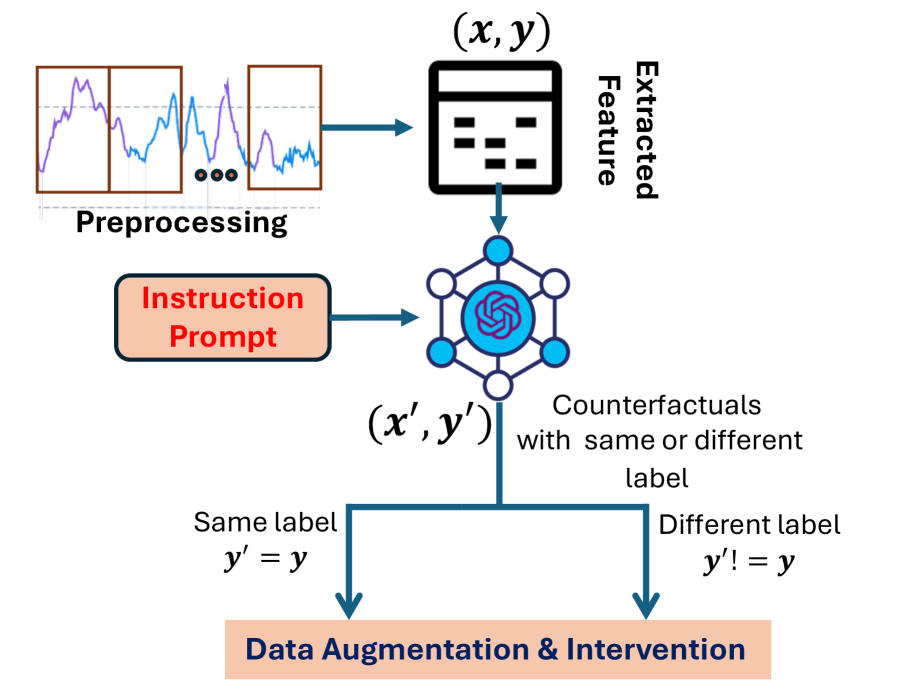
技术框架:整体框架包括以下几个主要步骤:1) 数据准备:使用AI-READI临床数据集,该数据集包含多模态数据。2) 模型选择与微调:选择GPT-4、BioMistral-7B和LLaMA-3.1-8B等LLM,并在AI-READI数据集上进行微调。3) 反事实生成:使用微调后的LLM生成反事实解释。4) 评估:从干预质量、特征多样性和增强有效性三个维度评估生成的反事实解释。5) 数据增强:使用生成的反事实解释进行数据增强,并评估模型性能。
关键创新:最重要的技术创新点在于利用微调的LLM生成反事实解释,这与传统的基于优化的方法不同。LLM能够更好地理解数据的语义信息,从而生成更具临床可操作性和语义连贯性的反事实解释。此外,该方法是模型无关的,可以应用于不同的机器学习模型。
关键设计:在微调过程中,使用了AI-READI数据集,并针对不同的LLM进行了参数调整。评估指标包括合理性(Plausibility)、有效性(Validity)和F1分数。在数据增强方面,采用了控制标签稀缺性的策略,以评估LLM生成反事实解释在不同数据稀缺情况下的性能。
🖼️ 关键图片
📊 实验亮点
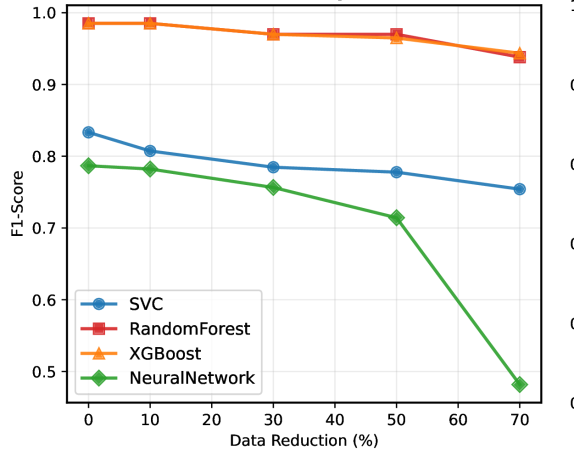
实验结果表明,微调的LLaMA-3.1-8B模型生成的反事实解释具有高达99%的合理性和0.99的有效性。在数据增强方面,LLM生成的反事实解释能够显著恢复分类器性能,在三种稀缺场景中平均恢复了20%的F1分数。与DiCE、CFNOW和NICE等基线方法相比,LLM方法生成了更具临床可操作性和语义连贯性的反事实。
🎯 应用场景
该研究成果可应用于个性化健康干预设计,例如针对特定患者生成定制化的饮食或运动建议。此外,通过数据增强,可以提高数字健康领域机器学习模型的鲁棒性和泛化能力,尤其是在数据稀缺的情况下。未来,该方法有望应用于疾病预测、健康风险评估等领域,促进精准医疗的发展。
📄 摘要(原文)
Counterfactual explanations (CFEs) provide human-centric interpretability by identifying the minimal, actionable changes required to alter a machine learning model's prediction. Therefore, CFs can be used as (i) interventions for abnormality prevention and (ii) augmented data for training robust models. We conduct a comprehensive evaluation of CF generation using large language models (LLMs), including GPT-4 (zero-shot and few-shot) and two open-source models-BioMistral-7B and LLaMA-3.1-8B, in both pretrained and fine-tuned configurations. Using the multimodal AI-READI clinical dataset, we assess CFs across three dimensions: intervention quality, feature diversity, and augmentation effectiveness. Fine-tuned LLMs, particularly LLaMA-3.1-8B, produce CFs with high plausibility (up to 99%), strong validity (up to 0.99), and realistic, behaviorally modifiable feature adjustments. When used for data augmentation under controlled label-scarcity settings, LLM-generated CFs substantially restore classifier performance, yielding an average 20% F1 recovery across three scarcity scenarios. Compared with optimization-based baselines such as DiCE, CFNOW, and NICE, LLMs offer a flexible, model-agnostic approach that generates more clinically actionable and semantically coherent counterfactuals. Overall, this work demonstrates the promise of LLM-driven counterfactuals for both interpretable intervention design and data-efficient model training in sensor-based digital health. Impact: SenseCF fine-tunes an LLM to generate valid, representative counterfactual explanations and supplement minority class in an imbalanced dataset for improving model training and boosting model robustness and predictive performance