Layer-adaptive Expert Pruning for Pre-Training of Mixture-of-Experts Large Language Models
作者: YuanLab. ai, Shawn Wu, Jiangang Luo, Tong Yu, Darcy Chen, Sean Wang, Xudong Zhao, Louie Li, Claire Wang, Hunter He, Carol Wang, Allen Wang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-20
💡 一句话要点
提出层自适应专家剪枝算法,提升MoE大语言模型预训练效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 大语言模型 预训练 专家剪枝 模型压缩
📋 核心要点
- MoE模型预训练计算量大,专家利用率不足,训练效率受限,成为性能瓶颈。
- 提出LAEP算法,通过层自适应专家剪枝和重组,提升专家利用率,加速预训练过程。
- 实验表明,LAEP在降低模型参数的同时,显著提升了预训练效率,并在多个领域表现出色。
📝 摘要(中文)
本文提出了一种层自适应专家剪枝(LAEP)算法,用于混合专家(MoE)大语言模型的预训练阶段。与以往主要在后训练阶段进行的专家剪枝方法不同,该算法通过选择性地剪枝利用率不足的专家,并根据token分布统计信息在计算设备之间重新组织专家,从而提高训练效率。综合实验表明,LAEP有效地减小了模型大小,并显著提高了预训练效率。特别是在从头开始预训练1010B Base模型时,LAEP在多个领域保持卓越性能的同时,实现了48.3%的训练效率提升和33.3%的参数减少。
🔬 方法详解
问题定义:MoE大语言模型虽然参数效率高,但其预训练阶段面临着计算瓶颈,主要原因是专家利用率不均衡,部分专家未被充分训练,导致整体训练效率低下。现有专家剪枝方法主要集中在后训练阶段,无法有效解决预训练阶段的效率问题。
核心思路:LAEP算法的核心思路是在预训练过程中,动态地识别并剪枝利用率低的专家,同时根据token的分布情况,对专家进行重新组织和分配,以优化计算资源的利用率。通过这种方式,LAEP旨在提高整体训练效率,减少计算资源的浪费。
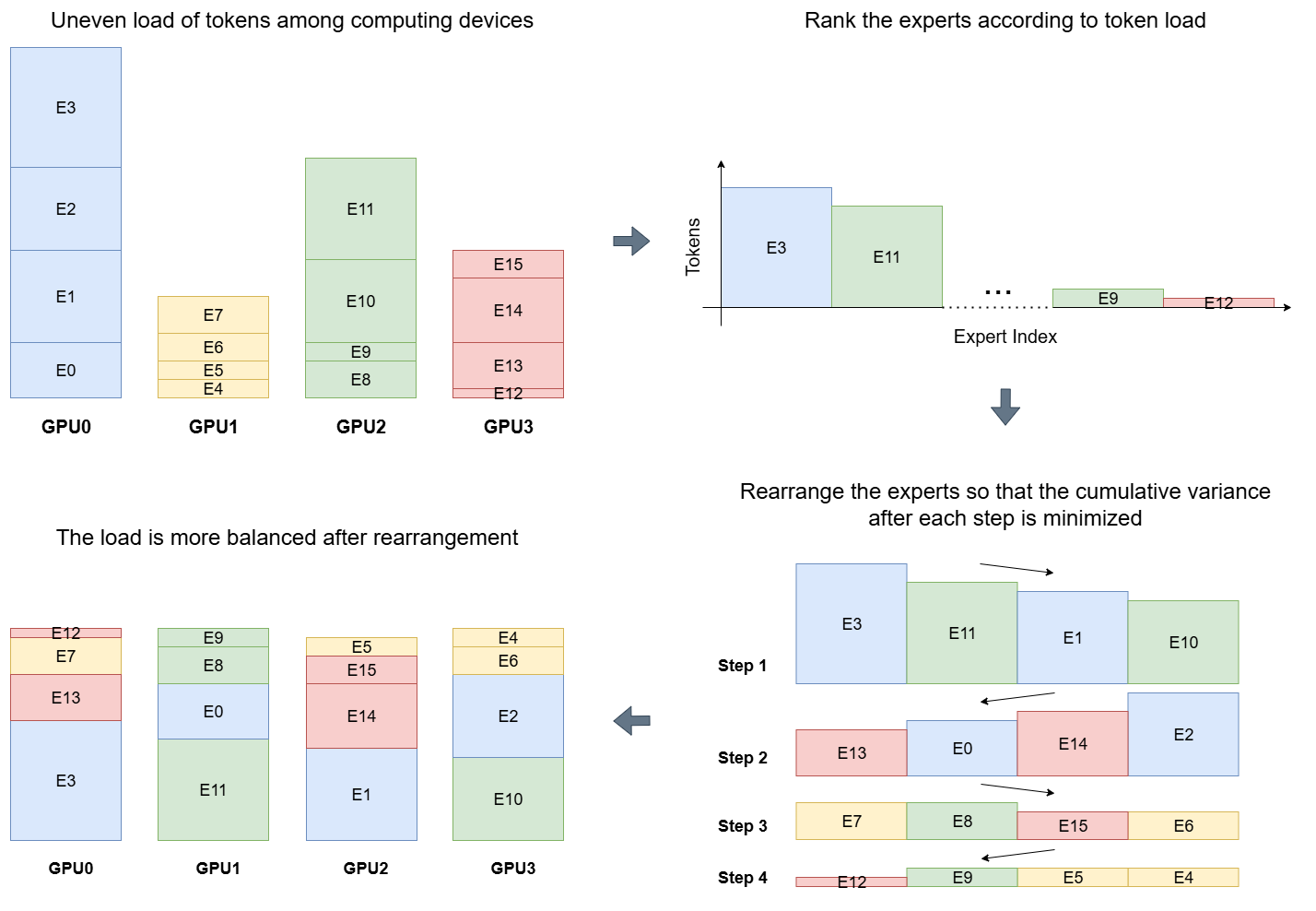
技术框架:LAEP算法主要包含两个阶段:专家利用率评估和专家剪枝与重组。首先,在每个训练迭代中,算法会收集每个专家的token分配统计信息,用于评估其利用率。然后,根据预设的阈值,算法会剪枝利用率低于阈值的专家。最后,算法会根据token分布统计信息,将剩余的专家重新分配到不同的计算设备上,以实现负载均衡。
关键创新:LAEP算法的关键创新在于其层自适应性。不同于以往的全局剪枝策略,LAEP允许在不同的层应用不同的剪枝策略,从而更好地适应不同层的专家利用率差异。此外,LAEP算法在预训练阶段进行专家剪枝,能够更早地释放计算资源,从而加速整体训练过程。
关键设计:LAEP算法的关键设计包括:1) 利用率评估指标的选择,论文可能采用了token分配数量、激活频率等指标来衡量专家的利用率;2) 剪枝阈值的设定,该阈值需要根据具体的模型和数据集进行调整,以平衡模型性能和训练效率;3) 专家重组策略,论文可能采用了基于token分布的贪心算法或其他优化算法,以实现计算资源的最佳分配。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LAEP算法在预训练1010B Base模型时,实现了48.3%的训练效率提升和33.3%的参数减少,同时保持了在多个领域上的卓越性能。这表明LAEP算法能够在显著降低计算成本的同时,保证模型的性能。
🎯 应用场景
该研究成果可广泛应用于各种基于MoE架构的大语言模型预训练场景,尤其适用于资源受限或对训练效率有较高要求的环境。通过LAEP算法,可以降低预训练成本,加速模型迭代,并推动MoE模型在自然语言处理、机器翻译、文本生成等领域的应用。
📄 摘要(原文)
Although Mixture-of-Experts (MoE) Large Language Models (LLMs) deliver superior accuracy with a reduced number of active parameters, their pre-training represents a significant computationally bottleneck due to underutilized experts and limited training efficiency. This work introduces a Layer-Adaptive Expert Pruning (LAEP) algorithm designed for the pre-training stage of MoE LLMs. In contrast to previous expert pruning approaches that operate primarily in the post-training phase, the proposed algorithm enhances training efficiency by selectively pruning underutilized experts and reorganizing experts across computing devices according to token distribution statistics. Comprehensive experiments demonstrate that LAEP effectively reduces model size and substantially improves pre-training efficiency. In particular, when pre-training the 1010B Base model from scratch, LAEP achieves a 48.3\% improvement in training efficiency alongside a 33.3% parameter reduction, while still delivering excellent performance across multiple domains.