Jet-RL: Enabling On-Policy FP8 Reinforcement Learning with Unified Training and Rollout Precision Flow
作者: Haocheng Xi, Charlie Ruan, Peiyuan Liao, Yujun Lin, Han Cai, Yilong Zhao, Shuo Yang, Kurt Keutzer, Song Han, Ligeng Zhu
分类: cs.LG, cs.CL
发布日期: 2026-01-20
备注: 11 pages, 6 figures, 4 tables
💡 一句话要点
Jet-RL:通过统一训练和Rollout精度流实现On-Policy FP8强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 FP8量化 模型加速 On-Policy训练 统一精度 Rollout优化 训练稳定性
📋 核心要点
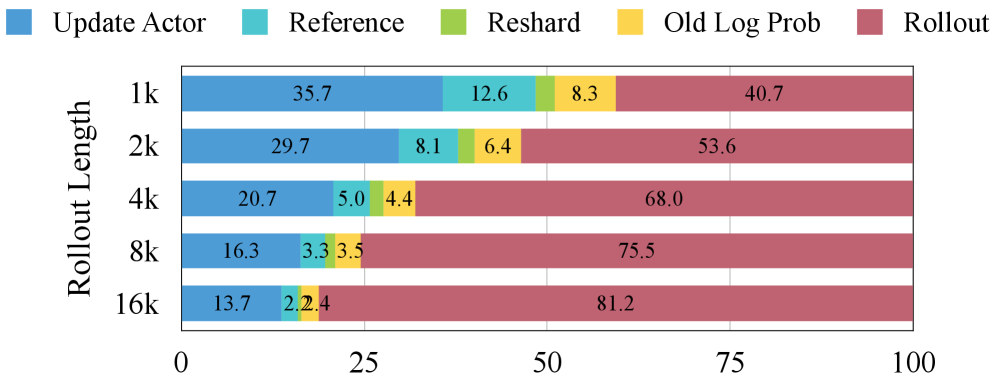
- 现有强化学习训练流程计算成本高昂,Rollout阶段耗时巨大,成为性能瓶颈。
- Jet-RL采用统一的FP8精度流进行训练和Rollout,减少数值差异,提升训练稳定性。
- 实验表明,Jet-RL在加速训练和Rollout的同时,保持了精度,实现了端到端性能提升。
📝 摘要(中文)
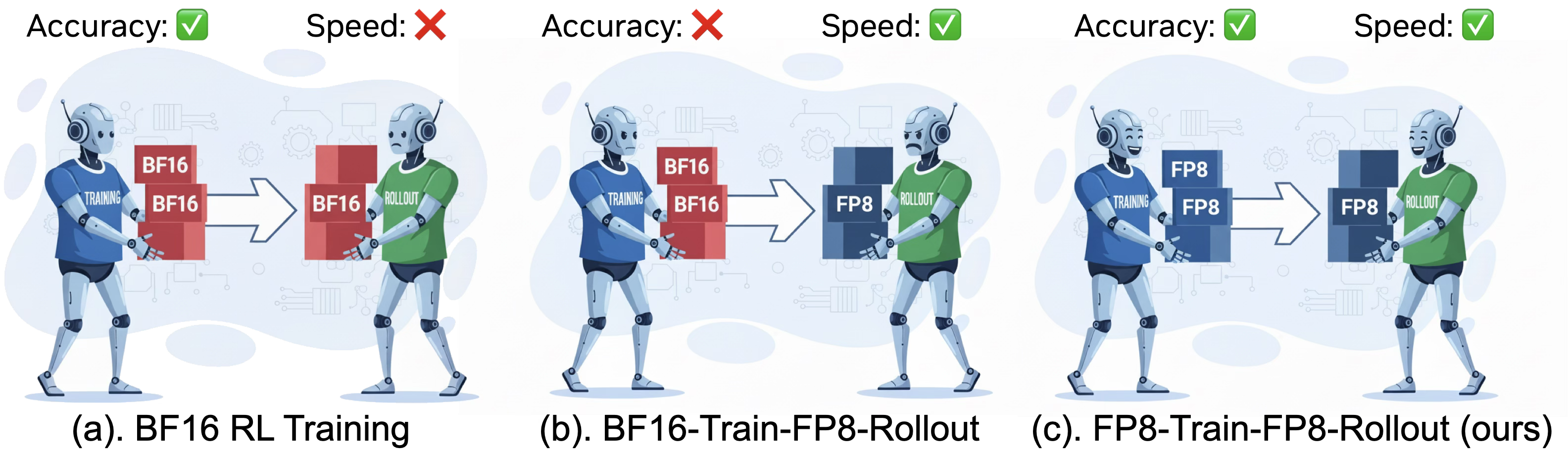
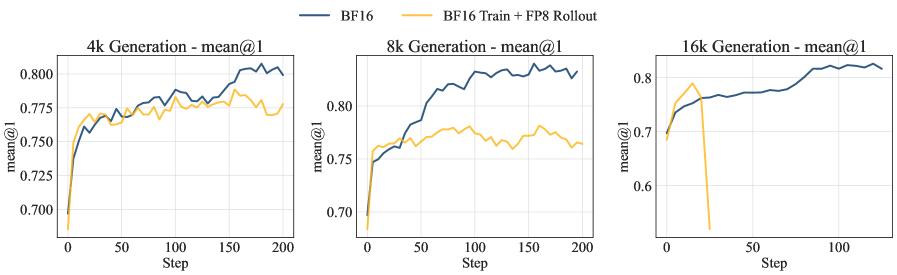
强化学习(RL)对于增强大型语言模型(LLM)的复杂推理能力至关重要。然而,现有的RL训练流程计算效率低下且资源密集,其中rollout阶段占总训练时间的70%以上。量化RL训练,特别是使用FP8精度,为缓解这一瓶颈提供了一种有希望的方法。一种常用的策略是在rollout期间应用FP8精度,同时保持BF16精度用于训练。本文首次全面研究了FP8 RL训练,并证明了广泛使用的BF16训练+FP8 rollout策略在长时程rollout和具有挑战性的任务下,存在严重的训练不稳定性和灾难性的精度崩溃。我们的分析表明,这些失败源于该方法的off-policy性质,这在训练和推理之间引入了显著的数值不匹配。基于这些观察,我们提出了Jet-RL,一个FP8 RL训练框架,可以实现鲁棒和稳定的RL优化。关键思想是为训练和rollout采用统一的FP8精度流,从而最大限度地减少数值差异,并消除对低效的步间校准的需求。大量的实验验证了Jet-RL的有效性:我们的方法在rollout阶段实现了高达33%的加速,在训练阶段实现了高达41%的加速,并且与BF16训练相比,实现了16%的端到端加速,同时在所有设置中保持了稳定的收敛,并且精度下降可以忽略不计。
🔬 方法详解
问题定义:现有强化学习训练中,Rollout阶段占据大量时间,而使用BF16训练+FP8 Rollout的混合精度策略,在长时程和复杂任务中会导致训练不稳定和精度崩溃。这是因为训练和推理精度不一致,导致数值不匹配,本质上是一种Off-Policy行为。
核心思路:Jet-RL的核心思路是采用统一的FP8精度流进行训练和Rollout。通过在训练和Rollout阶段使用相同的FP8精度,可以最大限度地减少数值差异,避免因精度不匹配导致的训练不稳定问题。这种统一精度的方法消除了对步间校准的需求,进一步提高了效率。
技术框架:Jet-RL框架主要包含以下几个阶段:首先,将环境状态输入到策略网络中,策略网络输出动作。然后,环境根据动作给出奖励和下一个状态。在训练阶段,使用FP8精度计算损失函数,并更新策略网络的参数。在Rollout阶段,同样使用FP8精度进行动作选择和环境交互。整个过程采用统一的FP8精度流,保证了训练和Rollout的一致性。
关键创新:Jet-RL最重要的创新点在于统一了训练和Rollout的精度,避免了混合精度训练带来的数值不匹配问题。与传统的BF16训练+FP8 Rollout方法相比,Jet-RL通过On-Policy的方式,保证了训练的稳定性,尤其是在长时程和复杂任务中。此外,Jet-RL还消除了对步间校准的需求,进一步提高了效率。
关键设计:Jet-RL的关键设计包括:使用FP8数据类型进行所有计算,包括前向传播、反向传播和参数更新。为了保证训练的稳定性,可能需要调整学习率和优化器参数。此外,策略网络的结构也需要进行优化,以适应FP8精度的限制。具体的损失函数和网络结构的选择取决于具体的任务。
🖼️ 关键图片
📊 实验亮点
Jet-RL在多个强化学习任务上进行了验证,实验结果表明,与BF16训练相比,Jet-RL在Rollout阶段实现了高达33%的加速,在训练阶段实现了高达41%的加速,并且实现了16%的端到端加速,同时保持了稳定的收敛和可忽略的精度损失。这些结果表明,Jet-RL是一种高效且稳定的FP8强化学习训练框架。
🎯 应用场景
Jet-RL可应用于各种需要强化学习的场景,尤其是在资源受限的边缘设备上部署大型语言模型时。通过降低计算复杂度和内存占用,Jet-RL能够加速模型训练和推理,提高能源效率,并促进强化学习在机器人控制、游戏AI、自动驾驶等领域的应用。
📄 摘要(原文)
Reinforcement learning (RL) is essential for enhancing the complex reasoning capabilities of large language models (LLMs). However, existing RL training pipelines are computationally inefficient and resource-intensive, with the rollout phase accounting for over 70% of total training time. Quantized RL training, particularly using FP8 precision, offers a promising approach to mitigating this bottleneck. A commonly adopted strategy applies FP8 precision during rollout while retaining BF16 precision for training. In this work, we present the first comprehensive study of FP8 RL training and demonstrate that the widely used BF16-training + FP8-rollout strategy suffers from severe training instability and catastrophic accuracy collapse under long-horizon rollouts and challenging tasks. Our analysis shows that these failures stem from the off-policy nature of the approach, which introduces substantial numerical mismatch between training and inference. Motivated by these observations, we propose Jet-RL, an FP8 RL training framework that enables robust and stable RL optimization. The key idea is to adopt a unified FP8 precision flow for both training and rollout, thereby minimizing numerical discrepancies and eliminating the need for inefficient inter-step calibration. Extensive experiments validate the effectiveness of Jet-RL: our method achieves up to 33% speedup in the rollout phase, up to 41% speedup in the training phase, and a 16% end-to-end speedup over BF16 training, while maintaining stable convergence across all settings and incurring negligible accuracy degradation.