InT: Self-Proposed Interventions Enable Credit Assignment in LLM Reasoning
作者: Matthew Y. R. Yang, Hao Bai, Ian Wu, Gene Yang, Amrith Setlur, Aviral Kumar
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-20
💡 一句话要点
InT:通过自提议干预实现LLM推理中的信用分配
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 信用分配 干预训练 数学推理
📋 核心要点
- 现有基于结果奖励的强化学习在LLM推理中存在信用分配问题,无法区分正确和错误的中间步骤。
- InT通过让模型自我提出干预措施,纠正推理过程中的错误,从而实现细粒度的信用分配。
- 实验表明,InT显著提高了LLM在数学推理任务上的准确率,优于更大的开源模型。
📝 摘要(中文)
结果-奖励强化学习(RL)已被证明可以有效提高大型语言模型(LLM)的推理能力。然而,标准的RL仅在最终答案层面分配信用,当结果不正确时惩罚整个推理过程,而当结果正确时则统一强化所有步骤。因此,正确的中间步骤可能会在失败的轨迹中受到抑制,而虚假的步骤可能会在成功的轨迹中得到强化。我们将这种失效模式称为信用分配问题。一个自然的补救方法是训练一个过程奖励模型,但准确地优化此类模型以识别纠正性推理步骤仍然具有挑战性。我们引入了干预训练(InT),这是一种训练范式,其中模型通过提出短小、有针对性的修正来引导轨迹朝着更高的奖励方向发展,从而对其自身的推理轨迹进行细粒度的信用分配。利用数学推理数据集中常见的参考解决方案,并利用验证模型生成的解决方案比从头开始生成正确解决方案更容易这一事实,模型识别其推理中的第一个错误,并提出一个单步干预来将轨迹重定向到正确的解决方案。然后,我们将监督微调(SFT)应用于直到错误点的on-policy rollout,并将其与干预连接起来,从而将错误定位到导致失败的特定步骤。我们表明,由此产生的模型是RL训练的更好的初始化。在运行InT并随后使用RL进行微调后,我们在IMO-AnswerBench上的准确率比4B参数的基础模型提高了近14%,优于更大的开源模型,如gpt-oss-20b。
🔬 方法详解
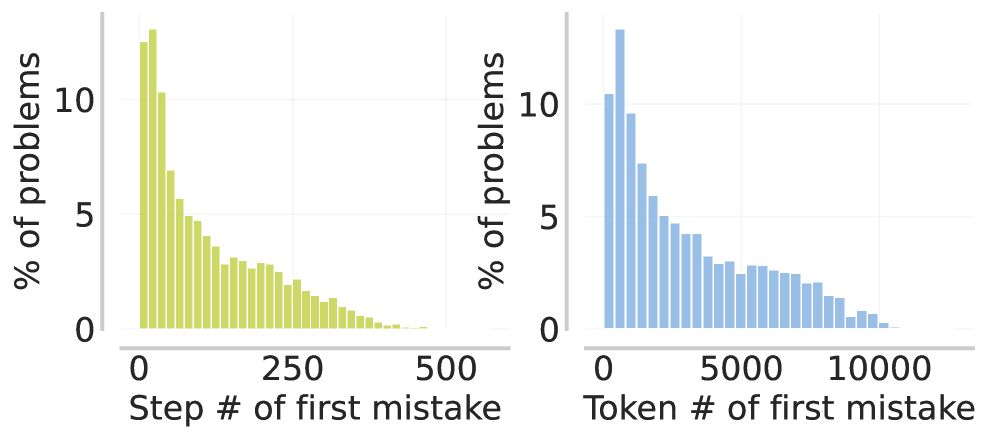
问题定义:现有基于结果的强化学习方法在训练LLM进行推理时,面临信用分配难题。当最终答案错误时,整个推理过程都会受到惩罚,即使其中包含正确的步骤;反之,当答案正确时,所有步骤都会得到奖励,即使其中包含错误的步骤。这种粗粒度的信用分配方式阻碍了模型学习正确的推理路径。
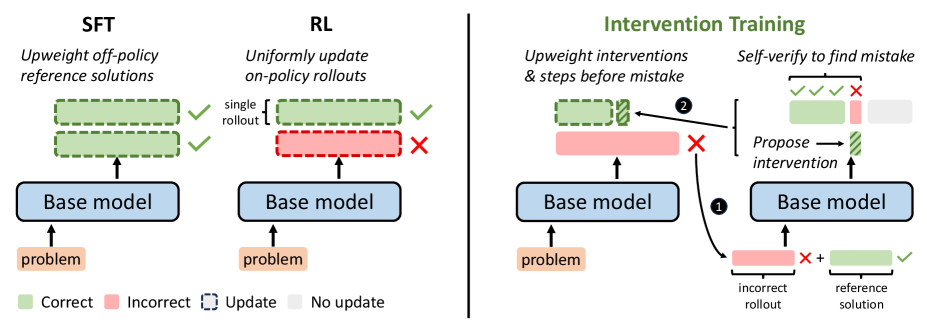
核心思路:InT的核心思想是让模型主动识别并纠正自身推理过程中的错误。通过引入“干预”机制,模型可以在推理过程中发现错误后,提出一个修正步骤,将轨迹引导到正确的方向。这种自我纠正的方式能够更精确地分配信用,从而提高模型的学习效率。
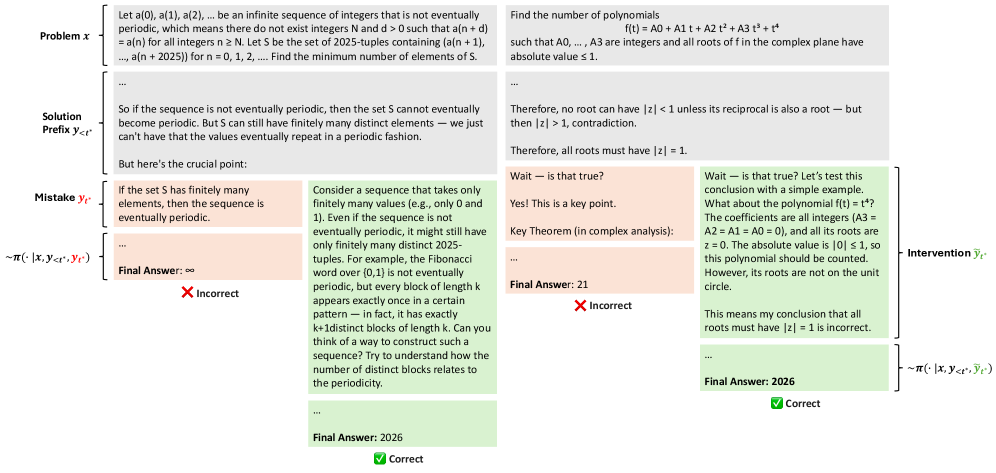
技术框架:InT的训练流程主要包含以下几个阶段:1) 模型生成推理轨迹;2) 模型利用参考答案识别轨迹中的第一个错误步骤;3) 模型提出一个单步干预来修正该错误;4) 使用监督微调(SFT)训练模型,目标是使模型在错误发生点能够生成正确的干预步骤。这个过程专注于错误定位和修正,从而实现更有效的学习。
关键创新:InT的关键创新在于其“自提议干预”的机制。与传统的依赖人工标注或奖励模型的方法不同,InT让模型自主地发现和纠正错误,从而实现了更细粒度、更高效的信用分配。这种方法充分利用了验证答案比生成答案更容易的特性,降低了训练难度。
关键设计:InT的关键设计包括:1) 使用参考答案来自动识别推理轨迹中的错误;2) 限制干预为单步修正,以简化学习任务;3) 使用监督微调(SFT)来训练模型生成正确的干预步骤。损失函数主要关注干预步骤的正确性,鼓励模型学习到有效的修正策略。
🖼️ 关键图片
📊 实验亮点
InT在IMO-AnswerBench数据集上取得了显著的性能提升,相较于4B参数的基础模型,准确率提高了近14%,并且超越了更大的开源模型,如gpt-oss-20b。这一结果表明InT是一种有效的LLM推理能力提升方法。
🎯 应用场景
InT方法可以应用于各种需要复杂推理能力的LLM应用场景,例如数学问题求解、代码生成、知识图谱推理等。通过提高LLM的推理准确性和可靠性,InT可以提升这些应用的性能和用户体验,并有望在教育、科研、金融等领域发挥重要作用。
📄 摘要(原文)
Outcome-reward reinforcement learning (RL) has proven effective at improving the reasoning capabilities of large language models (LLMs). However, standard RL assigns credit only at the level of the final answer, penalizing entire reasoning traces when the outcome is incorrect and uniformly reinforcing all steps when it is correct. As a result, correct intermediate steps may be discouraged in failed traces, while spurious steps may be reinforced in successful ones. We refer to this failure mode as the problem of credit assignment. While a natural remedy is to train a process reward model, accurately optimizing such models to identify corrective reasoning steps remains challenging. We introduce Intervention Training (InT), a training paradigm in which the model performs fine-grained credit assignment on its own reasoning traces by proposing short, targeted corrections that steer trajectories toward higher reward. Using reference solutions commonly available in mathematical reasoning datasets and exploiting the fact that verifying a model-generated solution is easier than generating a correct one from scratch, the model identifies the first error in its reasoning and proposes a single-step intervention to redirect the trajectory toward the correct solution. We then apply supervised fine-tuning (SFT) to the on-policy rollout up to the point of error concatenated with the intervention, localizing error to the specific step that caused failure. We show that the resulting model serves as a far better initialization for RL training. After running InT and subsequent fine-tuning with RL, we improve accuracy by nearly 14% over a 4B-parameter base model on IMO-AnswerBench, outperforming larger open-source models such as gpt-oss-20b.