LLMOrbit: A Circular Taxonomy of Large Language Models -From Scaling Walls to Agentic AI Systems
作者: Badri N. Patro, Vijay S. Agneeswaran
分类: cs.LG, cs.AI, cs.CV, cs.MA, eess.IV
发布日期: 2026-01-20
💡 一句话要点
LLMOrbit:大型语言模型循环分类法,应对扩展壁垒并迈向Agentic AI系统
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型效率 扩展壁垒 循环分类法 后训练技术
📋 核心要点
- 现有大型语言模型面临数据稀缺、训练成本高昂和能源消耗过大的挑战,限制了其进一步扩展。
- LLMOrbit通过循环分类法,分析了大型语言模型的架构、训练方法和效率模式,旨在打破扩展壁垒。
- 研究揭示了测试时计算、量化等六种打破扩展壁垒的范式,以及后训练增益、效率革命和民主化三大范式转变。
📝 摘要(中文)
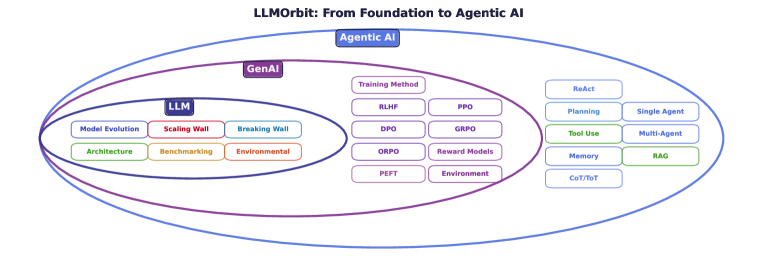
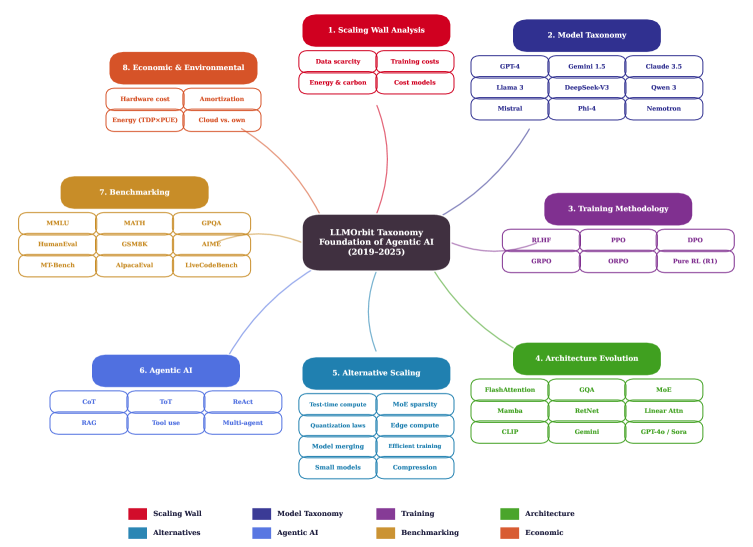
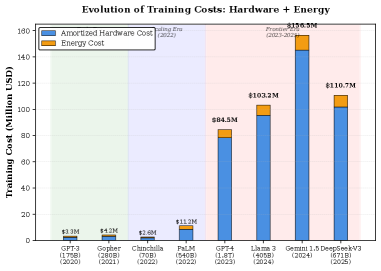
本文提出了LLMOrbit,一个全面的循环分类法,旨在导航2019年至2025年间大型语言模型的发展格局。该研究考察了15个组织超过50个模型,通过八个相互关联的维度,记录了现代LLM、生成式AI和Agentic系统中的架构创新、训练方法和效率模式。研究识别了三个关键危机:数据稀缺(到2026-2028年将耗尽9-27T tokens)、指数级成本增长(5年内从300万美元增长到3亿美元以上)以及不可持续的能源消耗(增加22倍),这些构成了限制暴力扩展方法的“扩展壁垒”。分析揭示了六种打破壁垒的范式:测试时计算、量化、分布式边缘计算、模型合并、高效训练和小而专的模型。此外,还发现了三个范式转变:后训练增益、效率革命和民主化。本文深入探讨了RLHF、PPO、DPO、GRPO、ORPO等技术,追溯了从被动生成到工具使用代理(ReAct、RAG、多代理系统)的演变,并分析了后训练创新。
🔬 方法详解
问题定义:当前大型语言模型的发展面临三大挑战:一是数据稀缺,高质量的训练数据日益枯竭;二是训练成本呈指数级增长,使得只有少数机构能够负担得起;三是能源消耗巨大,对环境造成了严重影响。这些问题共同构成了限制LLM进一步扩展的“扩展壁垒”。
核心思路:论文的核心思路是通过对现有LLM进行系统性的分类和分析,识别出打破“扩展壁垒”的有效策略和范式转变。通过深入研究不同模型的架构、训练方法和后训练技术,寻找提高效率、降低成本和减少资源消耗的途径。
技术框架:LLMOrbit采用了一种循环分类法,从八个相互关联的维度对LLM进行分析。这些维度包括架构创新、训练方法、效率模式等。通过对超过50个模型进行考察,识别出六种打破扩展壁垒的范式,包括测试时计算、量化、分布式边缘计算、模型合并、高效训练和小而专的模型。同时,还分析了后训练增益、效率革命和民主化三大范式转变。
关键创新:论文的关键创新在于提出了LLMOrbit循环分类法,并基于此识别出打破扩展壁垒的六种范式和三大范式转变。这些发现为未来LLM的发展方向提供了重要的指导,有助于推动LLM朝着更高效、更经济、更可持续的方向发展。
关键设计:论文的关键设计在于其循环分类法的构建,该分类法能够全面地覆盖LLM的各个方面,并揭示不同因素之间的相互关系。此外,论文还深入分析了各种后训练技术(如RLHF、PPO、DPO、GRPO、ORPO)的优缺点,为模型优化提供了参考。
🖼️ 关键图片
📊 实验亮点
研究表明,通过测试时计算优化,DeepSeek-R1在10倍推理计算量下达到了GPT-4的性能。量化技术能够实现4-8倍的压缩。Llama 3在MMLU基准测试中达到了88.6%的准确率,超过了GPT-4的86.4%,体现了开源模型的强大潜力。
🎯 应用场景
该研究成果可应用于指导新型高效大型语言模型的研发,降低训练和推理成本,并促进LLM在资源受限环境中的部署。此外,该研究还有助于推动AI技术的民主化,使更多机构和个人能够参与到LLM的研究和应用中。
📄 摘要(原文)
The field of artificial intelligence has undergone a revolution from foundational Transformer architectures to reasoning-capable systems approaching human-level performance. We present LLMOrbit, a comprehensive circular taxonomy navigating the landscape of large language models spanning 2019-2025. This survey examines over 50 models across 15 organizations through eight interconnected orbital dimensions, documenting architectural innovations, training methodologies, and efficiency patterns defining modern LLMs, generative AI, and agentic systems. We identify three critical crises: (1) data scarcity (9-27T tokens depleted by 2026-2028), (2) exponential cost growth ($3M to $300M+ in 5 years), and (3) unsustainable energy consumption (22x increase), establishing the scaling wall limiting brute-force approaches. Our analysis reveals six paradigms breaking this wall: (1) test-time compute (o1, DeepSeek-R1 achieve GPT-4 performance with 10x inference compute), (2) quantization (4-8x compression), (3) distributed edge computing (10x cost reduction), (4) model merging, (5) efficient training (ORPO reduces memory 50%), and (6) small specialized models (Phi-4 14B matches larger models). Three paradigm shifts emerge: (1) post-training gains (RLHF, GRPO, pure RL contribute substantially, DeepSeek-R1 achieving 79.8% MATH), (2) efficiency revolution (MoE routing 18x efficiency, Multi-head Latent Attention 8x KV cache compression enables GPT-4-level performance at <$0.30/M tokens), and (3) democratization (open-source Llama 3 88.6% MMLU surpasses GPT-4 86.4%). We provide insights into techniques (RLHF, PPO, DPO, GRPO, ORPO), trace evolution from passive generation to tool-using agents (ReAct, RAG, multi-agent systems), and analyze post-training innovations.