RL-BioAug: Label-Efficient Reinforcement Learning for Self-Supervised EEG Representation Learning
作者: Cheol-Hui Lee, Hwa-Yeon Lee, Dong-Joo Kim
分类: cs.LG, cs.AI
发布日期: 2026-01-20 (更新: 2026-01-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出RL-BioAug,利用强化学习进行脑电信号自监督表征学习,提升数据增强效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 脑电信号 自监督学习 强化学习 数据增强 表征学习
📋 核心要点
- 脑电信号的非平稳性使得传统静态或随机数据增强方法难以有效保留信号的内在信息,限制了自监督学习的性能。
- RL-BioAug利用强化学习智能体自动学习最优的数据增强策略,仅需少量标签数据即可指导智能体学习。
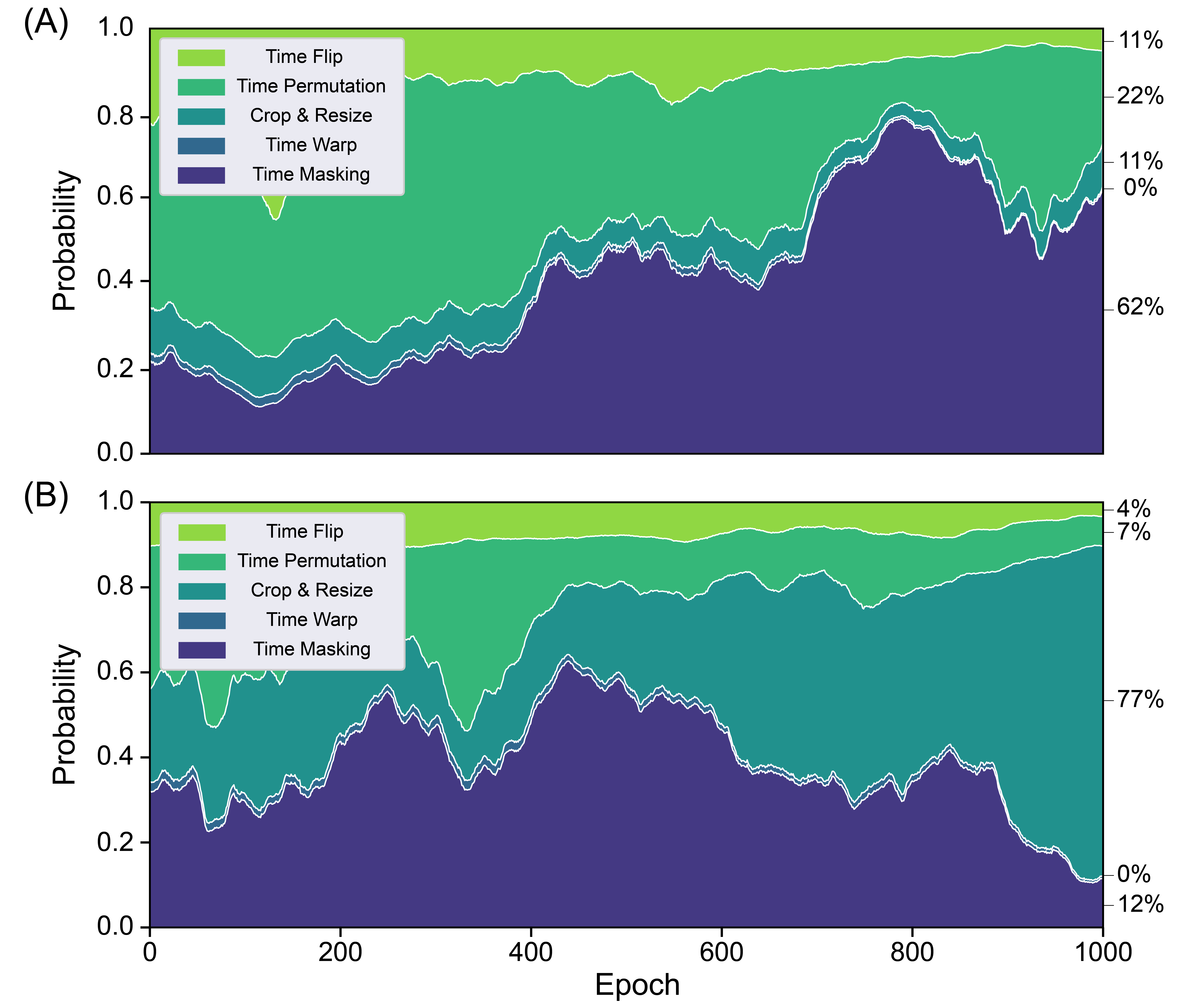
- 实验表明,RL-BioAug在睡眠分期和癫痫检测任务上显著优于随机增强策略,Macro-F1分别提升9.69%和8.80%。
📝 摘要(中文)
脑电信号(EEG)任务中,数据增强的质量是对比学习性能的关键决定因素。尽管对比学习在利用无标签数据方面很有前景,但由于脑电信号的非平稳性(统计特性随时间变化),静态或随机增强策略通常无法保留内在信息。为了解决这个问题,我们提出了RL-BioAug,该框架利用标签高效的强化学习(RL)智能体来自动确定最佳增强策略。我们的方法仅利用一小部分(10%)的标记数据来指导智能体的策略,从而使编码器能够以严格的自监督方式学习鲁棒的表示。实验结果表明,RL-BioAug显著优于随机选择策略,在Sleep-EDFX和CHB-MIT数据集上分别实现了9.69%和8.80%的Macro-F1评分的显著提升。值得注意的是,该智能体主要为每个任务选择了最佳策略——例如,睡眠阶段分类中62%概率的时间掩码和癫痫检测中77%概率的裁剪和调整大小。我们的框架表明其有潜力取代传统的基于启发式的增强,并为数据增强建立一种新的自主范式。源代码可在https://github.com/dlcjfgmlnasa/RL-BioAug获得。
🔬 方法详解
问题定义:论文旨在解决脑电信号自监督表征学习中,由于脑电信号的非平稳性,传统数据增强方法效果不佳的问题。现有方法通常采用静态或随机的数据增强策略,无法根据脑电信号的特性进行自适应调整,导致学习到的表征鲁棒性较差。
核心思路:论文的核心思路是利用强化学习(RL)自动学习最优的数据增强策略。通过训练一个RL智能体,使其能够根据脑电信号的特性,动态地选择合适的数据增强方法,从而提高自监督学习的性能。这种方法能够克服传统静态增强策略的局限性,更好地保留脑电信号的内在信息。
技术框架:RL-BioAug框架主要包含三个模块:脑电信号编码器、强化学习智能体和对比学习目标。首先,脑电信号通过编码器提取特征表示。然后,RL智能体根据当前状态(例如,编码器的输出)选择数据增强策略。增强后的脑电信号再次通过编码器,并利用对比学习目标函数进行训练,使得相似的脑电信号在特征空间中更加接近。RL智能体的奖励函数基于对比学习的损失,从而引导智能体学习最优的增强策略。
关键创新:RL-BioAug的关键创新在于将强化学习引入到脑电信号的自监督学习中,实现数据增强策略的自动优化。与传统方法相比,RL-BioAug能够根据脑电信号的特性动态地选择增强策略,从而更好地保留信号的内在信息,提高学习到的表征的鲁棒性。此外,该方法仅需少量标签数据即可指导智能体的学习,降低了对标签数据的依赖。
关键设计:RL智能体采用策略梯度算法进行训练,状态空间为编码器的输出,动作空间为预定义的数据增强操作(例如,时间掩码、裁剪和调整大小等)。奖励函数基于对比学习的损失,鼓励智能体选择能够提高对比学习性能的增强策略。论文中使用了10%的标签数据来指导智能体的策略学习,通过监督学习的方式初始化智能体的策略网络。
🖼️ 关键图片
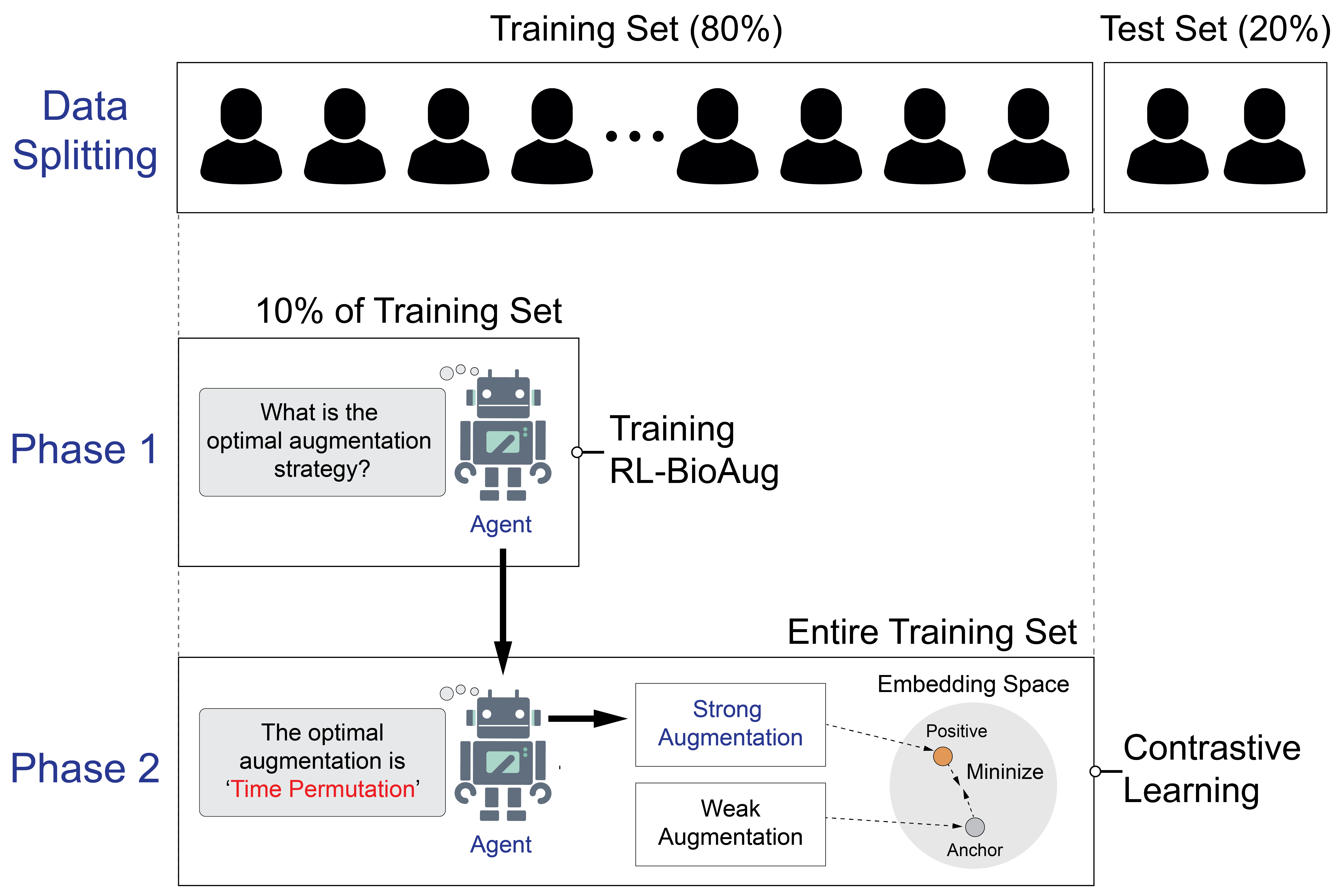
📊 实验亮点
实验结果表明,RL-BioAug在Sleep-EDFX和CHB-MIT数据集上分别实现了9.69%和8.80%的Macro-F1评分的显著提升,超过了随机选择策略。智能体学习到的最优策略具有任务相关性,例如,睡眠阶段分类中时间掩码策略占主导,而癫痫检测中裁剪和调整大小策略更有效。
🎯 应用场景
RL-BioAug可应用于各种基于脑电信号的分析任务,如睡眠分期、癫痫检测、运动想象等。该方法能够提高脑电信号表征学习的效率和鲁棒性,降低对大量标注数据的依赖,具有重要的实际应用价值。未来,该方法可以推广到其他类型的生理信号分析任务中。
📄 摘要(原文)
The quality of data augmentation serves as a critical determinant for the performance of contrastive learning in EEG tasks. Although this paradigm is promising for utilizing unlabeled data, static or random augmentation strategies often fail to preserve intrinsic information due to the non-stationarity of EEG signals where statistical properties change over time. To address this, we propose RL-BioAug, a framework that leverages a label-efficient reinforcement learning (RL) agent to autonomously determine optimal augmentation policies. While utilizing only a minimal fraction (10%) of labeled data to guide the agent's policy, our method enables the encoder to learn robust representations in a strictly self-supervised manner. Experimental results demonstrate that RL-BioAug significantly outperforms the random selection strategy, achieving substantial improvements of 9.69% and 8.80% in Macro-F1 score on the Sleep-EDFX and CHB-MIT datasets, respectively. Notably, this agent mainly chose optimal strategies for each task--for example, Time Masking with a 62% probability for sleep stage classification and Crop & Resize with a 77% probability for seizure detection. Our framework suggests its potential to replace conventional heuristic-based augmentations and establish a new autonomous paradigm for data augmentation. The source code is available at https://github.com/dlcjfgmlnasa/RL-BioAug.