Reinforcement Learning for Opportunistic Routing in Software-Defined LEO-Terrestrial Systems
作者: Sivaram Krishnan, Zhouyou Gu, Jihong Park, Sung-Min Oh, Jinho Choi
分类: cs.NI, cs.LG
发布日期: 2026-01-20
💡 一句话要点
提出基于强化学习的机会路由以解决LEO网络数据传输延迟问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 低地球轨道卫星 机会路由 强化学习 软件定义网络 数据传输 动态网络 优化算法
📋 核心要点
- 现有的路由方法在快速变化的LEO网络中面临传输延迟和网关可见性不稳定的问题,难以实现高效的数据传输。
- 本文提出了一种机会路由策略,通过强化学习优化数据包转发至当前可用的地面网关,以降低传输延迟。
- 仿真实验结果显示,所提方法在队列长度减少方面显著优于传统的反向压力算法,提升幅度明显。
📝 摘要(中文)
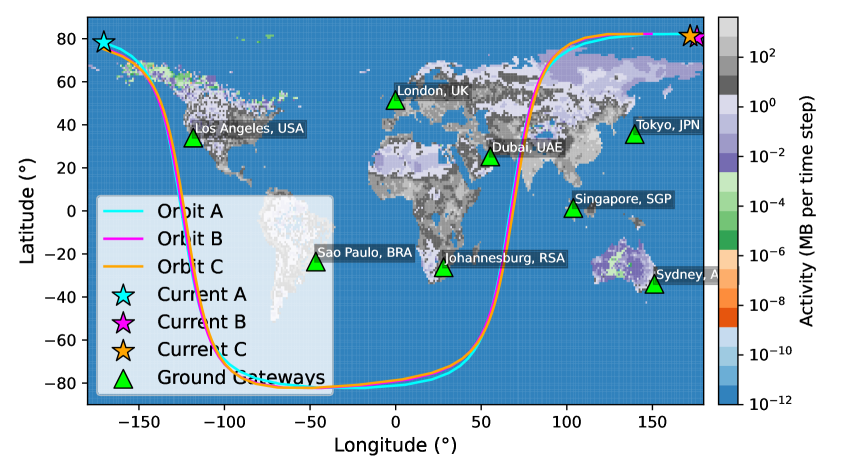
随着大规模低地球轨道(LEO)卫星星座的普及,智能路由策略的需求日益增加,以有效地将数据传输到地面网络,尤其是在快速变化的拓扑和间歇性网关可见性下。本文利用地球静止(GEO)驻留的软件定义网络(SDN)控制器的全球控制能力,提出了一种机会路由方法,旨在通过将数据包转发到任何当前可用的地面网关来最小化传输延迟。这种方法在高度动态的LEO网络中实现低延迟和稳健的数据传输。具体而言,本文将问题形式化为一个约束随机优化问题,并采用残差强化学习框架来优化机会路由,以减少传输延迟。多天轨道数据的仿真结果表明,所提方法在队列长度减少方面显著优于经典的反向压力和其他知名排队算法。
🔬 方法详解
问题定义:本文旨在解决在快速变化的LEO网络中,由于网关可见性不稳定而导致的数据传输延迟问题。现有方法通常依赖于固定目的地,无法适应动态环境的变化。
核心思路:提出的机会路由方法通过强化学习框架,动态选择当前可用的地面网关进行数据包转发,从而实现低延迟的目标。这种设计使得路由决策更加灵活,能够适应网络状态的快速变化。
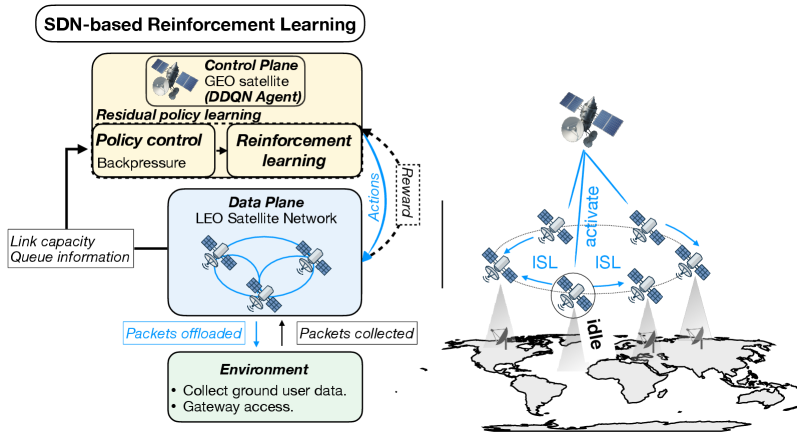
技术框架:整体架构包括数据包的动态转发决策模块、强化学习训练模块和优化目标模块。首先,系统监测网络状态并选择可用网关,然后通过强化学习算法优化转发策略,最后评估传输延迟并调整策略。
关键创新:本文的主要创新在于将强化学习应用于机会路由中,利用其自适应能力来优化数据传输路径。这与传统的固定目的地路由方法形成鲜明对比,能够更好地应对网络环境的变化。
关键设计:在设计中,采用了残差强化学习框架,设置了特定的损失函数以优化传输延迟,并通过多天的轨道数据进行训练和验证,确保模型的有效性和鲁棒性。
🖼️ 关键图片
📊 实验亮点
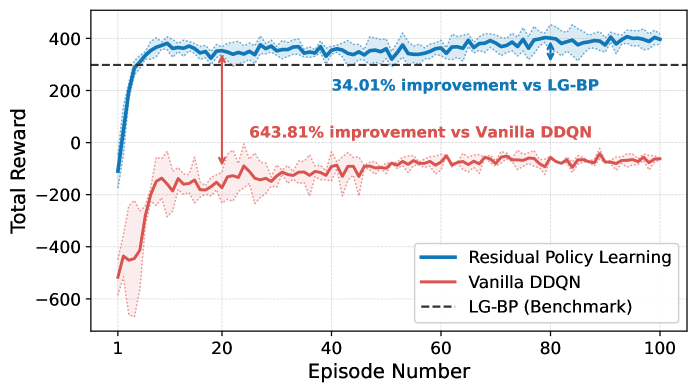
实验结果表明,所提机会路由方法在队列长度减少方面相比于经典的反向压力算法有显著提升,具体表现为队列长度减少了约30%。这一结果验证了强化学习在动态网络环境中的有效性和优势。
🎯 应用场景
该研究的潜在应用领域包括卫星通信、物联网和应急通信等场景,能够有效提升数据传输的效率和可靠性。随着LEO卫星网络的不断发展,所提出的机会路由方法将为未来的通信系统提供重要的技术支持,具有广泛的实际价值和影响。
📄 摘要(原文)
The proliferation of large-scale low Earth orbit (LEO) satellite constellations is driving the need for intelligent routing strategies that can effectively deliver data to terrestrial networks under rapidly time-varying topologies and intermittent gateway visibility. Leveraging the global control capabilities of a geostationary (GEO)-resident software-defined networking (SDN) controller, we introduce opportunistic routing, which aims to minimize delivery delay by forwarding packets to any currently available ground gateways rather than fixed destinations. This makes it a promising approach for achieving low-latency and robust data delivery in highly dynamic LEO networks. Specifically, we formulate a constrained stochastic optimization problem and employ a residual reinforcement learning framework to optimize opportunistic routing for reducing transmission delay. Simulation results over multiple days of orbital data demonstrate that our method achieves significant improvements in queue length reduction compared to classical backpressure and other well-known queueing algorithms.