Preconditioning Benefits of Spectral Orthogonalization in Muon
作者: Jianhao Ma, Yu Huang, Yuejie Chi, Yuxin Chen
分类: cs.LG, cs.AI, math.OC, stat.ML
发布日期: 2026-01-20
💡 一句话要点
通过谱正交化,Muon优化器在矩阵分解和上下文学习中实现与条件数无关的线性收敛。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Muon优化器 谱正交化 矩阵分解 上下文学习 线性收敛 预处理 条件数
📋 核心要点
- 现有方法对Muon优化器中梯度正交化的作用理解不足,缺乏严谨的端到端分析。
- 论文通过谱正交化简化Muon,并证明其在矩阵分解和上下文学习中的优越性。
- 理论分析表明,简化Muon的收敛速度与问题条件数无关,优于梯度下降和Adam。
📝 摘要(中文)
Muon优化器是一种矩阵结构的算法,它利用梯度的谱正交化,是大型语言模型预训练的一个里程碑。然而,Muon的底层机制——特别是梯度正交化的作用——仍然知之甚少,极少有工作提供端到端的分析来严格解释其在具体应用中的优势。本文通过两个案例研究,即矩阵分解和线性Transformer的上下文学习,研究了Muon简化变体的有效性。对于这两个问题,我们证明了简化的Muon以线性方式收敛,其迭代复杂度与相关的条件数无关,明显优于梯度下降和Adam。我们的分析表明,Muon动力学在谱域中解耦为一系列独立的标量序列,每个序列都表现出相似的收敛行为。我们的理论形式化了谱正交化引起的预处理效果,为Muon在这些矩阵优化问题中的有效性以及潜在的更广泛应用提供了见解。
🔬 方法详解
问题定义:Muon优化器在大型语言模型预训练中表现出色,但其内在机制,特别是梯度正交化的作用,尚不明确。现有方法缺乏对其优势的充分理论分析,尤其是在具体应用场景中。论文旨在通过理论分析,揭示Muon优化器中谱正交化的预处理作用,并解释其优于传统优化算法的原因。
核心思路:论文的核心思路是通过简化Muon优化器,并针对矩阵分解和线性Transformer的上下文学习这两个具体问题进行分析。通过将Muon动力学在谱域中解耦为独立的标量序列,从而简化分析过程。这种方法能够更清晰地揭示谱正交化对收敛速度的影响,并证明其与问题条件数无关。
技术框架:论文的技术框架主要包括以下几个步骤:1) 简化Muon优化器;2) 选择矩阵分解和线性Transformer的上下文学习作为案例研究;3) 在谱域中分析简化Muon的动力学行为;4) 证明其线性收敛性,并与梯度下降和Adam进行比较。整个框架旨在通过理论分析,揭示Muon优化器的优势。
关键创新:论文的关键创新在于通过谱分析,揭示了Muon优化器中谱正交化的预处理作用。证明了简化Muon的收敛速度与问题条件数无关,这与传统的梯度下降和Adam等优化算法形成了鲜明对比。这种与条件数无关的收敛性是Muon在大型语言模型预训练中表现出色的关键原因之一。
关键设计:论文的关键设计包括:1) 对Muon优化器进行简化,使其更易于分析;2) 选择矩阵分解和线性Transformer的上下文学习作为具有代表性的案例研究;3) 在谱域中进行分析,将复杂的矩阵优化问题转化为一系列独立的标量优化问题;4) 采用严格的数学证明,确保结论的可靠性。
🖼️ 关键图片
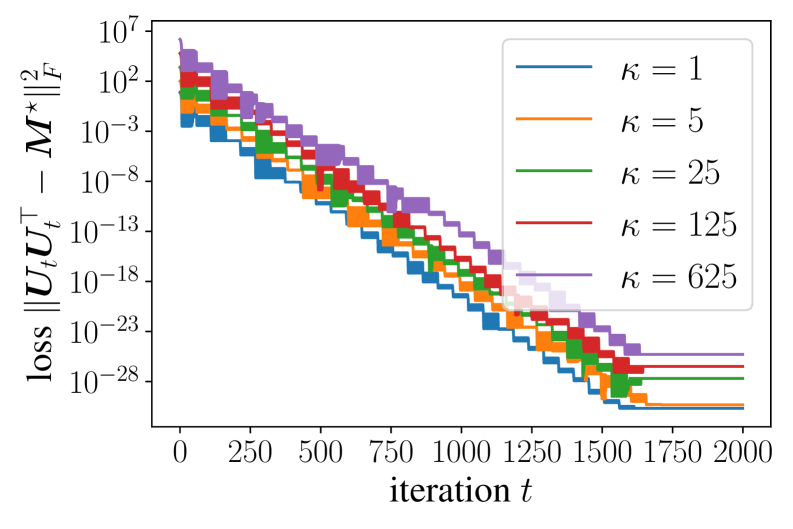
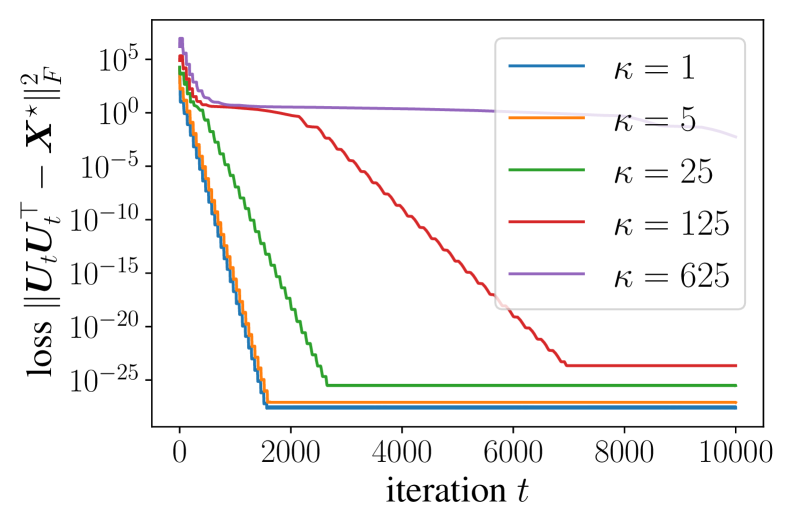
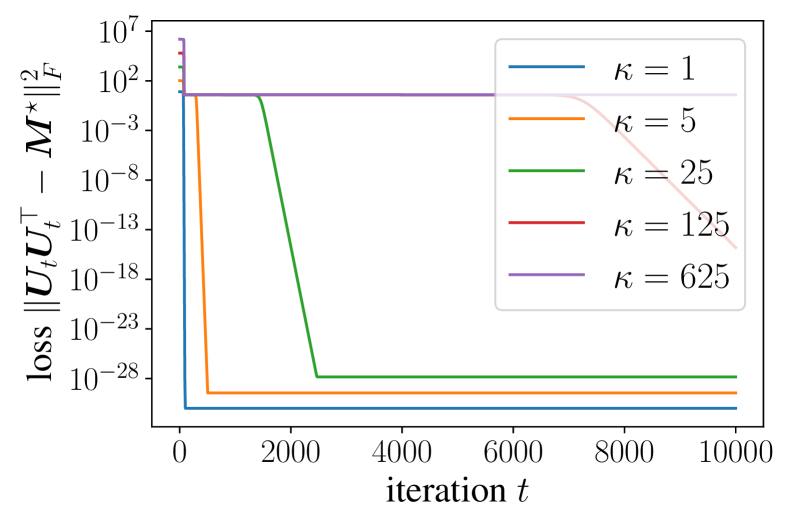
📊 实验亮点
论文证明了简化Muon在矩阵分解和线性Transformer的上下文学习中,能够以线性方式收敛,且迭代复杂度与问题条件数无关。这显著优于梯度下降和Adam等传统优化算法,表明Muon在解决病态优化问题方面具有巨大潜力。
🎯 应用场景
该研究成果可应用于大规模机器学习模型的训练,尤其是在矩阵优化问题中。通过利用谱正交化的预处理效果,可以加速模型训练过程,提高模型性能。潜在的应用领域包括自然语言处理、推荐系统、图像识别等。
📄 摘要(原文)
The Muon optimizer, a matrix-structured algorithm that leverages spectral orthogonalization of gradients, is a milestone in the pretraining of large language models. However, the underlying mechanisms of Muon -- particularly the role of gradient orthogonalization -- remain poorly understood, with very few works providing end-to-end analyses that rigorously explain its advantages in concrete applications. We take a step by studying the effectiveness of a simplified variant of Muon through two case studies: matrix factorization, and in-context learning of linear transformers. For both problems, we prove that simplified Muon converges linearly with iteration complexities independent of the relevant condition number, provably outperforming gradient descent and Adam. Our analysis reveals that the Muon dynamics decouple into a collection of independent scalar sequences in the spectral domain, each exhibiting similar convergence behavior. Our theory formalizes the preconditioning effect induced by spectral orthogonalization, offering insight into Muon's effectiveness in these matrix optimization problems and potentially beyond.