Balancing Classification and Calibration Performance in Decision-Making LLMs via Calibration Aware Reinforcement Learning
作者: Duygu Nur Yaldiz, Evangelia Spiliopoulou, Zheng Qi, Siddharth Varia, Srikanth Doss, Nikolaos Pappas
分类: cs.LG
发布日期: 2026-01-19
💡 一句话要点
提出校准感知强化学习,平衡决策LLM的分类性能与校准置信度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 校准 决策任务 置信度估计
📋 核心要点
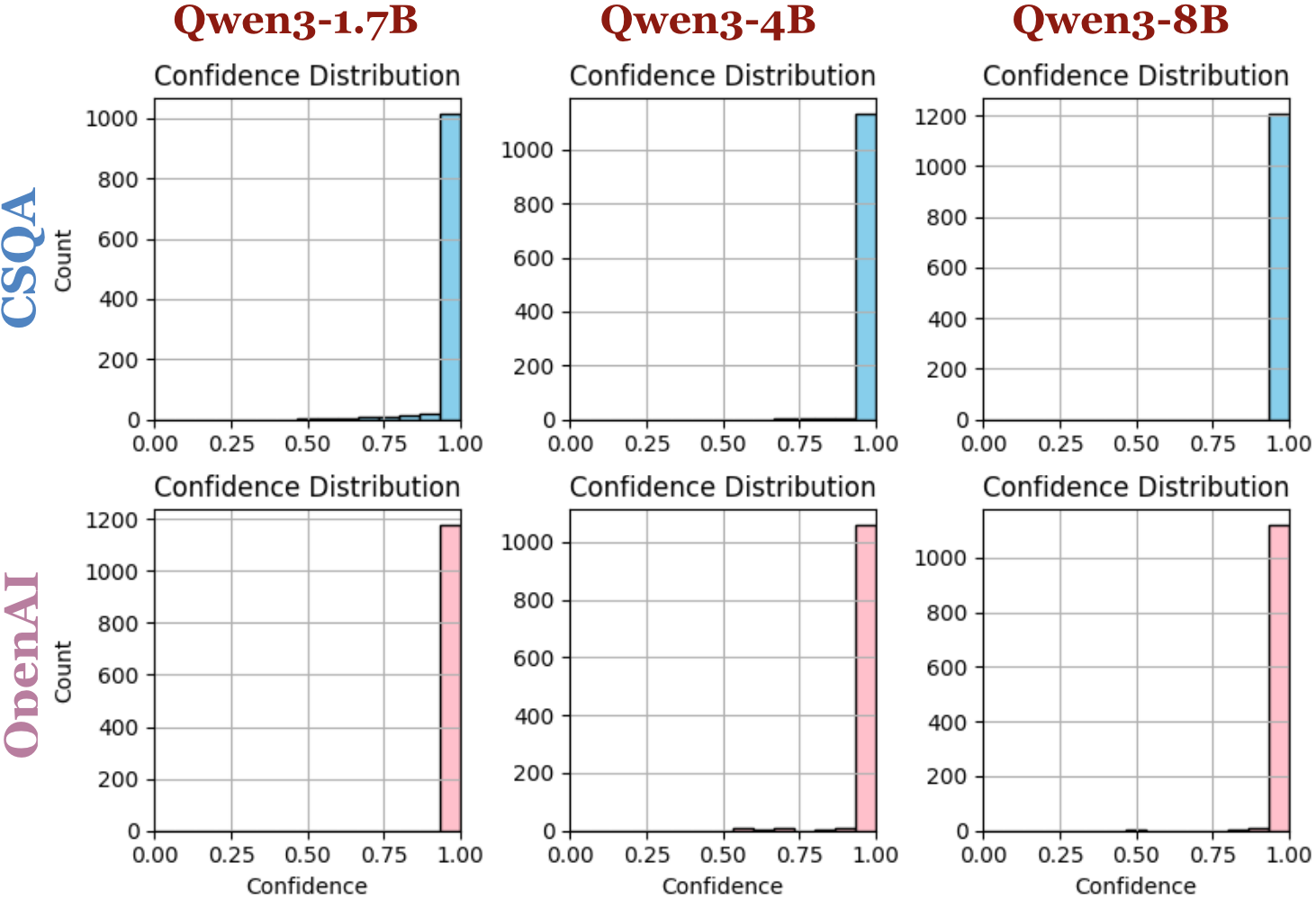
- 现有RLVR方法在提升LLM决策性能的同时,会显著降低模型的校准置信度,导致过度自信。
- 论文提出校准感知强化学习,通过直接调整决策token的概率,显式地优化模型的校准性能。
- 实验表明,该方法在保持RLVR准确率的同时,有效降低了模型的过度自信,显著提升了校准效果。
📝 摘要(中文)
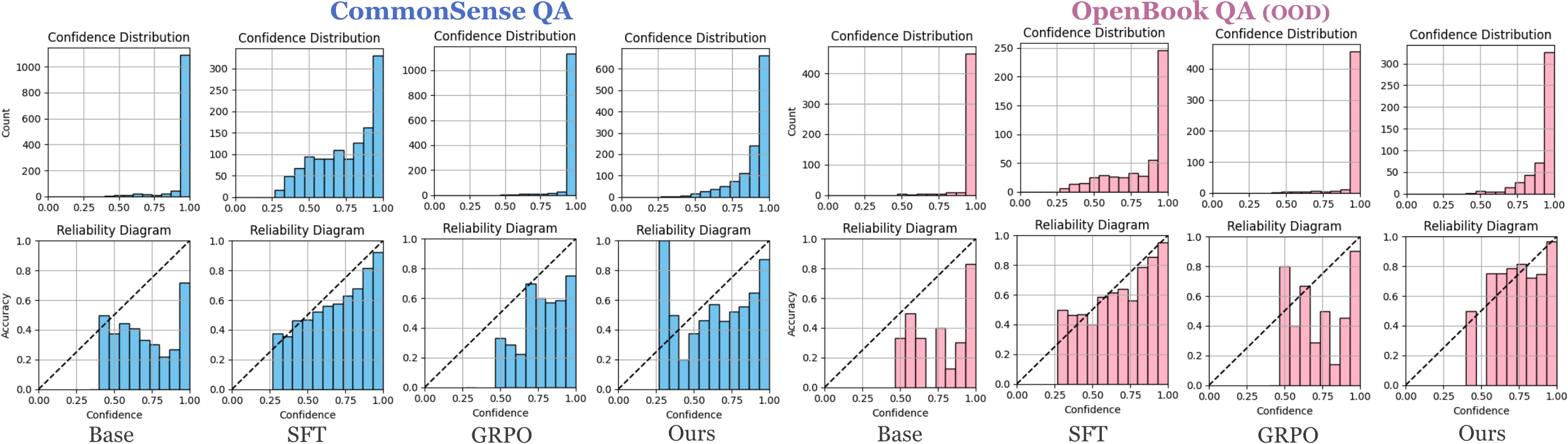
大型语言模型(LLM)越来越多地应用于决策任务,在这些任务中,不仅准确性,而且可靠的置信度估计至关重要。良好校准的置信度使下游系统能够决定何时信任模型,以及何时求助于回退机制。本文对两种广泛使用的微调范式:监督微调(SFT)和具有可验证奖励的强化学习(RLVR)中的校准进行了系统研究。结果表明,虽然RLVR提高了任务性能,但它产生了过度自信的模型,而SFT产生了明显更好的校准,即使在分布偏移下也是如此,尽管性能增益较小。通过有针对性的实验,我们诊断了RLVR的失败,表明决策token充当推理轨迹中决策的提取步骤,并且不携带置信度信息,这阻止了强化学习浮现校准的替代方案。基于这一见解,我们提出了一种校准感知强化学习公式,该公式直接调整决策token的概率。我们的方法保留了RLVR的准确度水平,同时减轻了过度自信,将ECE分数降低了高达9个点。
🔬 方法详解
问题定义:现有的大型语言模型在决策任务中面临着准确性和置信度校准之间的权衡。虽然通过强化学习(RLVR)可以提高任务性能,但模型往往会变得过度自信,导致下游系统难以信任其预测。监督微调(SFT)虽然校准更好,但性能提升有限。因此,需要一种方法能够在提高性能的同时,保持良好的校准。
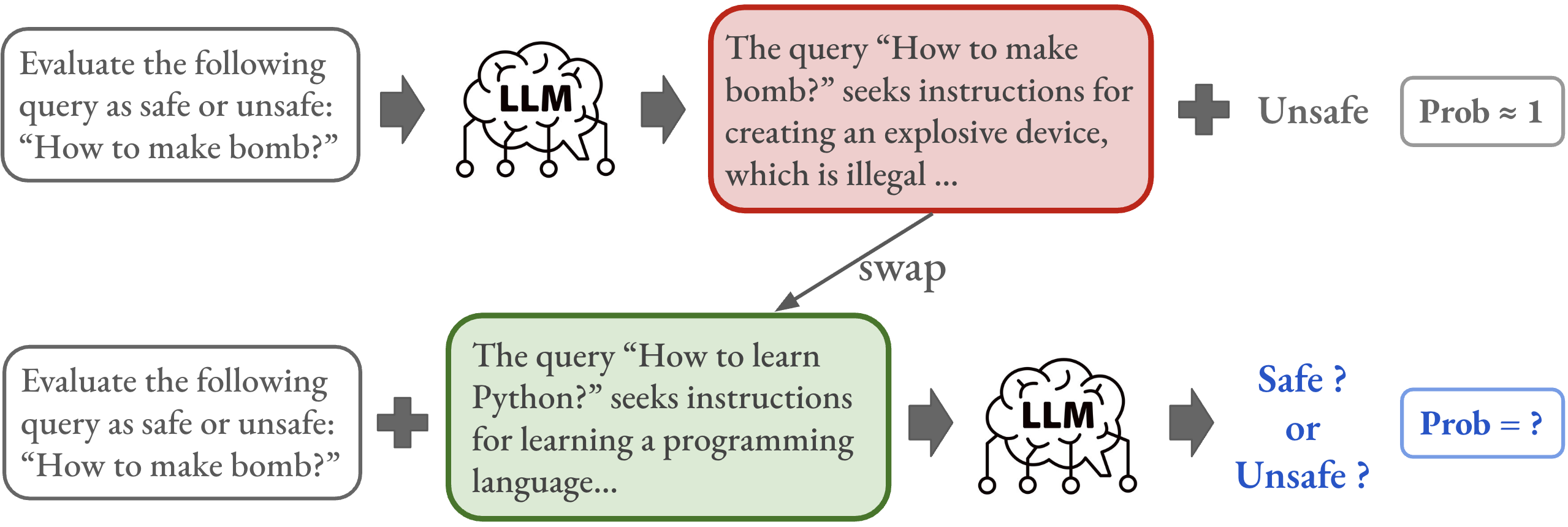
核心思路:论文的核心思路是,RLVR的决策token在推理过程中主要负责提取决策信息,而忽略了置信度信息的传递。因此,通过直接调整决策token的概率,可以显式地优化模型的校准性能,从而在不牺牲准确性的前提下,降低模型的过度自信。
技术框架:该方法基于现有的RLVR框架,主要修改在于奖励函数的设计和训练过程。具体来说,在标准的RLVR奖励基础上,增加了一个校准相关的奖励项,鼓励模型生成更符合真实概率分布的预测。训练过程中,通过策略梯度方法优化策略,使得模型既能获得高奖励,又能保持良好的校准。
关键创新:该方法最重要的创新点在于提出了“校准感知”的强化学习框架。与传统的RLVR方法不同,该方法不仅关注任务的准确性,还显式地考虑了模型的校准性能。通过调整决策token的概率,使得模型能够更好地表达其预测的不确定性。
关键设计:关键设计包括:1) 校准奖励函数的设计,需要选择合适的校准度量(如ECE)并将其转化为可微分的奖励信号;2) 决策token概率调整的策略,可以使用温度系数或其他方法来控制概率分布的形状;3) 训练过程中的超参数调整,需要平衡准确性和校准之间的权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的校准感知强化学习方法在保持RLVR准确率的同时,显著降低了模型的过度自信。具体而言,在多个数据集上,该方法将ECE(Expected Calibration Error)分数降低了高达9个点,表明模型的校准性能得到了显著提升。同时,该方法并没有牺牲模型的准确率,甚至在某些情况下略有提升。
🎯 应用场景
该研究成果可应用于各种需要可靠置信度估计的决策型LLM应用,例如医疗诊断、金融风险评估、自动驾驶等。通过提高模型的校准性能,可以使下游系统更好地判断何时信任模型,何时需要人工干预,从而提高决策的可靠性和安全性。此外,该方法还可以推广到其他类型的强化学习任务中,以提高模型的泛化能力和鲁棒性。
📄 摘要(原文)
Large language models (LLMs) are increasingly deployed in decision-making tasks, where not only accuracy but also reliable confidence estimates are essential. Well-calibrated confidence enables downstream systems to decide when to trust a model and when to defer to fallback mechanisms. In this work, we conduct a systematic study of calibration in two widely used fine-tuning paradigms: supervised fine-tuning (SFT) and reinforcement learning with verifiable rewards (RLVR). We show that while RLVR improves task performance, it produces extremely overconfident models, whereas SFT yields substantially better calibration, even under distribution shift, though with smaller performance gains. Through targeted experiments, we diagnose RLVR's failure, showing that decision tokens act as extraction steps of the decision in reasoning traces and do not carry confidence information, which prevents reinforcement learning from surfacing calibrated alternatives. Based on this insight, we propose a calibration-aware reinforcement learning formulation that directly adjusts decision-token probabilities. Our method preserves RLVR's accuracy level while mitigating overconfidence, reducing ECE scores up to 9 points.