A Comprehensive Evaluation of LLM Reasoning: From Single-Model to Multi-Agent Paradigms
作者: Yapeng Li, Jiakuo Yu, Zhixin Liu, Xinnan Liu, Jing Yu, Songze Li, Tonghua Su
分类: cs.LG
发布日期: 2026-01-19
💡 一句话要点
全面评估LLM推理范式:从单模型到多智能体系统,揭示其性能与成本权衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理范式 思维链 多智能体系统 成本效益分析 语义理解 基准测试 MIMeBench
📋 核心要点
- 现有LLM推理范式(如CoT和MAS)的有效性和成本效益缺乏系统性评估和对比分析。
- 通过统一的评估框架,对比单模型、CoT增强和多智能体系统在推理任务上的性能表现。
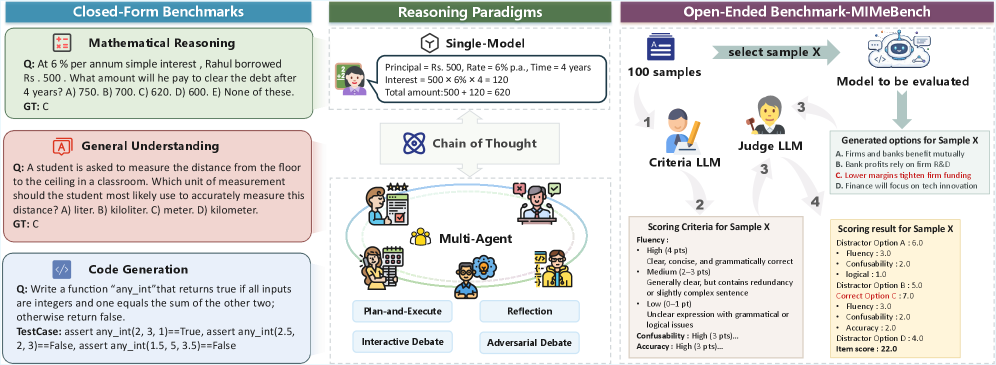
- 引入MIMeBench基准,评估LLM在语义抽象和对比辨别等方面的能力,弥补现有基准的不足。
📝 摘要(中文)
大型语言模型(LLM)越来越多地被部署为推理系统,其中推理范式(如思维链CoT和多智能体系统MAS)发挥着关键作用,但它们相对的有效性和成本-准确性权衡仍然知之甚少。本文对推理范式进行了全面和统一的评估,涵盖直接单模型生成、CoT增强的单模型推理和代表性的MAS工作流程,描述了它们在各种封闭式基准测试中的推理性能。除了整体性能外,我们还使用有针对性的角色隔离分析来探究MAS中特定角色的能力需求,并分析成本-准确性权衡,以确定哪些MAS工作流程在成本和准确性之间提供了良好的平衡,以及哪些工作流程因边际收益而产生过高的开销。我们进一步引入了MIMeBench,这是一个新的开放式基准测试,针对两个基础但未被充分探索的语义能力——语义抽象和对比辨别——从而提供了封闭式准确性之外的另一种评估维度,并能够对现有基准测试难以捕捉的语义能力进行细粒度评估。结果表明,增加结构复杂性并不一定会提高推理性能,其益处高度依赖于推理范式本身的属性和适用性。
🔬 方法详解
问题定义:现有的大型语言模型推理方法,特别是思维链(CoT)和多智能体系统(MAS),虽然在某些任务上表现出色,但缺乏对其性能、成本和适用性的全面评估。现有研究难以确定哪种推理范式在特定场景下能提供最佳的成本-效益平衡,并且缺乏对LLM语义理解能力的细粒度评估。
核心思路:本文的核心思路是通过构建一个统一的评估框架,对不同的LLM推理范式进行系统性的对比分析。该框架不仅关注封闭式基准测试中的准确率,还考虑了推理过程的成本,并引入新的基准测试(MIMeBench)来评估LLM的语义理解能力。通过这种多维度的评估,旨在揭示不同推理范式的优势和局限性,为实际应用提供指导。
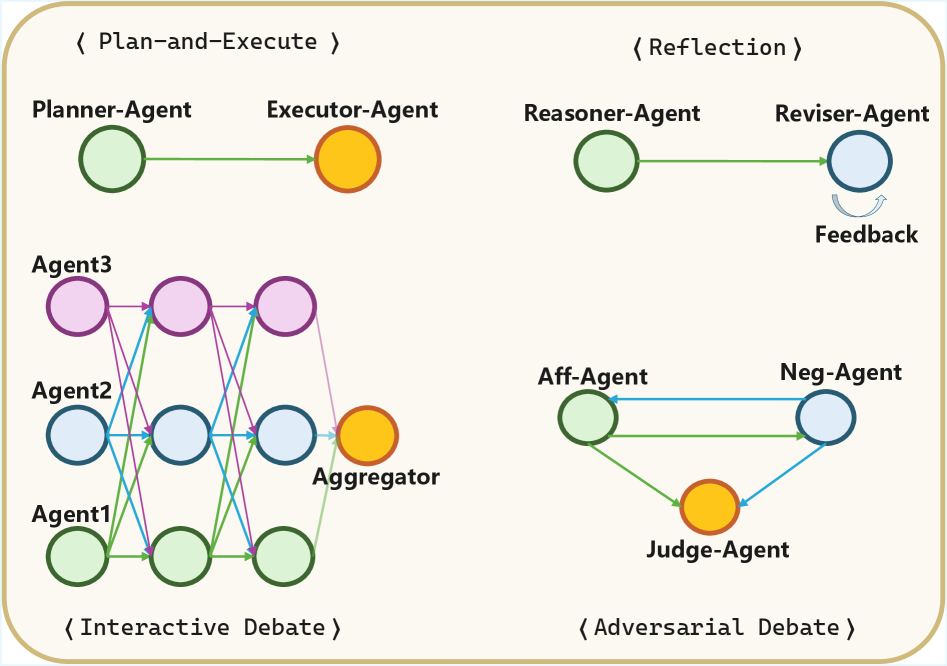
技术框架:该研究的技术框架主要包含以下几个部分:1) 选择具有代表性的LLM推理范式,包括直接单模型生成、CoT增强的单模型推理和多种MAS工作流程。2) 在一系列封闭式基准测试上评估这些范式的推理性能。3) 使用角色隔离分析来探究MAS中特定角色的能力需求。4) 分析成本-准确性权衡,以确定哪些MAS工作流程具有良好的成本效益。5) 引入MIMeBench基准测试,评估LLM的语义抽象和对比辨别能力。
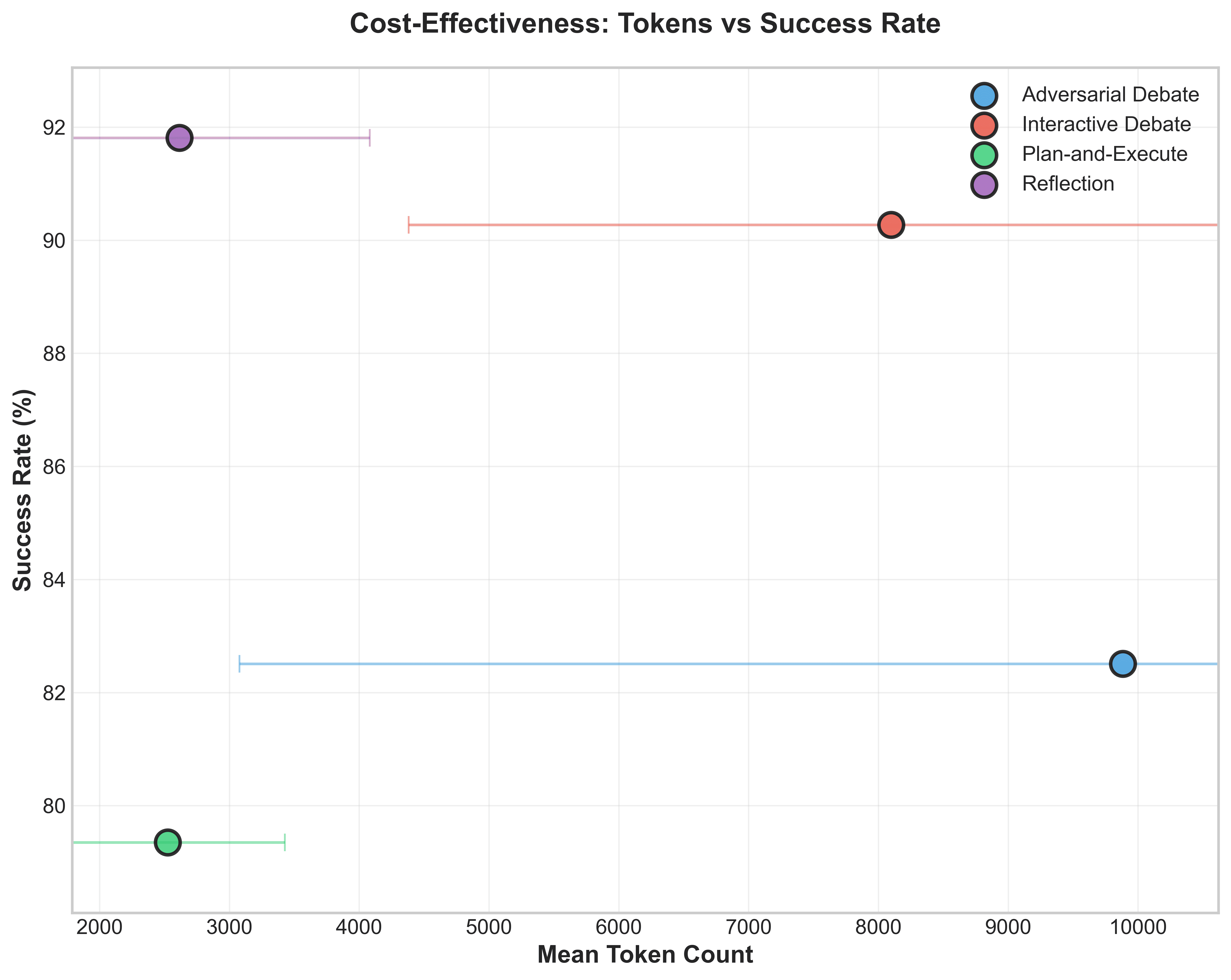
关键创新:该研究的关键创新在于:1) 对LLM推理范式进行了全面和统一的评估,涵盖了单模型和多智能体系统。2) 引入了MIMeBench基准测试,用于评估LLM的语义理解能力,弥补了现有基准测试的不足。3) 通过成本-准确性分析,揭示了不同推理范式的成本效益,为实际应用提供了指导。
关键设计:MIMeBench基准测试的设计重点在于评估LLM的语义抽象和对比辨别能力。具体来说,该基准测试包含一系列开放式问题,要求LLM能够理解问题的语义,并生成相应的答案。此外,该研究还使用了角色隔离分析来探究MAS中特定角色的能力需求。在成本-准确性分析中,研究人员考虑了推理过程的时间、计算资源等因素。
🖼️ 关键图片
📊 实验亮点
研究结果表明,增加结构复杂性并不一定会提高推理性能,其益处高度依赖于推理范式本身的属性和适用性。通过MIMeBench的评估,揭示了现有LLM在语义抽象和对比辨别方面存在的不足,为未来的研究提供了方向。成本-准确性分析表明,某些MAS工作流程可能因边际收益而产生过高的开销。
🎯 应用场景
该研究成果可应用于各种需要LLM进行推理的场景,例如智能客服、知识问答、决策支持等。通过选择合适的推理范式,可以提高LLM的推理性能和效率,降低成本。此外,MIMeBench基准测试可以用于评估和改进LLM的语义理解能力,从而提高LLM在复杂任务中的表现。该研究有助于推动LLM在实际应用中的广泛应用。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed as reasoning systems, where reasoning paradigms - such as Chain-of-Thought (CoT) and multi-agent systems (MAS) - play a critical role, yet their relative effectiveness and cost-accuracy trade-offs remain poorly understood. In this work, we conduct a comprehensive and unified evaluation of reasoning paradigms, spanning direct single-model generation, CoT-augmented single-model reasoning, and representative MAS workflows, characterizing their reasoning performance across a diverse suite of closed-form benchmarks. Beyond overall performance, we probe role-specific capability demands in MAS using targeted role isolation analyses, and analyze cost-accuracy trade-offs to identify which MAS workflows offer a favorable balance between cost and accuracy, and which incur prohibitive overhead for marginal gains. We further introduce MIMeBench, a new open-ended benchmark that targets two foundational yet underexplored semantic capabilities - semantic abstraction and contrastive discrimination - thereby providing an alternative evaluation axis beyond closed-form accuracy and enabling fine-grained assessment of semantic competence that is difficult to capture with existing benchmarks. Our results show that increased structural complexity does not consistently lead to improved reasoning performance, with its benefits being highly dependent on the properties and suitability of the reasoning paradigm itself. The codes are released at https://gitcode.com/HIT1920/OpenLLMBench.