FastAV: Efficient Token Pruning for Audio-Visual Large Language Model Inference
作者: Chaeyoung Jung, Youngjoon Jang, Seungwoo Lee, Joon Son Chung
分类: cs.LG
发布日期: 2026-01-19
💡 一句话要点
FastAV:面向音视频大语言模型推理的高效Token剪枝框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音视频大语言模型 Token剪枝 注意力机制 多模态融合 模型压缩
📋 核心要点
- 现有AV-LLM因多模态融合导致token需求显著增加,但缺乏针对性的token剪枝方法。
- FastAV利用注意力权重评估token重要性,并提出两阶段剪枝策略,兼顾全局效率和局部精度。
- 实验表明,FastAV能在显著降低FLOPs的同时,保持甚至提升AV-LLM的性能。
📝 摘要(中文)
本文提出了FastAV,这是首个专为音视频大语言模型(AV-LLM)设计的token剪枝框架。尽管token剪枝在标准大语言模型(LLM)和视觉-语言模型(LVLM)中已被广泛研究,但其在AV-LLM中的应用却鲜有关注,即使多模态融合显著增加了token需求。为了弥补这一空白,我们引入了一种剪枝策略,该策略利用注意力权重来识别不同阶段中被强调的token,并估计它们的重要性。在此分析的基础上,FastAV应用了一种两阶段剪枝策略:(1)中间层的全局剪枝,以移除广泛意义上不太重要的token;(2)后续层的精细剪枝,考虑对下一个token生成的影响。值得注意的是,我们的方法不依赖于完整的注意力图,这使其与诸如FlashAttention等高效注意力机制完全兼容。大量实验表明,FastAV在两个具有代表性的AV-LLM上减少了超过40%的FLOPs,同时保持甚至提高了模型性能。
🔬 方法详解
问题定义:现有的token剪枝方法主要集中在LLM和LVLM上,而忽略了AV-LLM。AV-LLM需要处理音频和视频等多模态信息,导致token数量大幅增加,计算成本高昂。因此,需要一种专门为AV-LLM设计的高效token剪枝方法,以降低推理成本,同时保持模型性能。
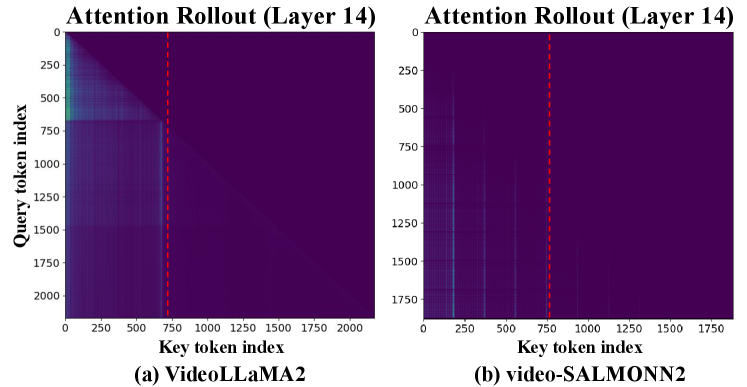
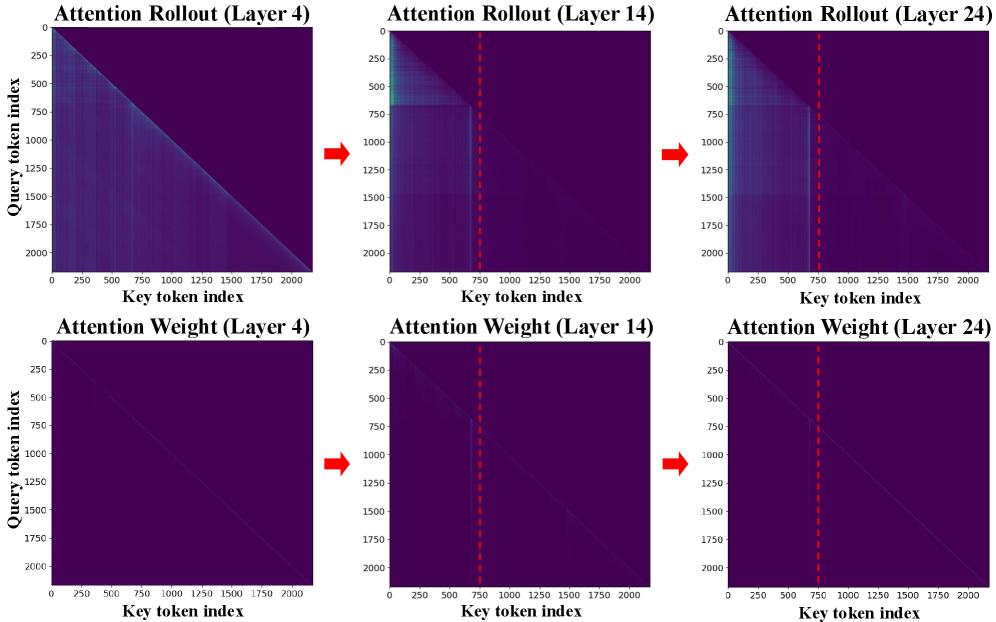
核心思路:FastAV的核心思路是利用注意力机制中的注意力权重来评估每个token的重要性。注意力权重反映了token在模型不同阶段对其他token的影响程度,因此可以作为token重要性的指标。通过分析注意力权重,可以识别出对模型性能影响较小的token,并将其剪枝掉。
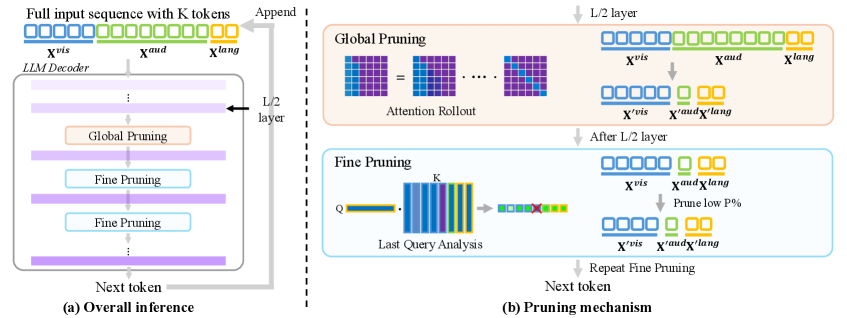
技术框架:FastAV采用两阶段剪枝策略。第一阶段是全局剪枝,在中间层移除那些在整体上不太重要的token,旨在减少计算量。第二阶段是精细剪枝,在后续层考虑token对下一个token生成的影响,进行更细粒度的剪枝,以保证模型性能。该框架与FlashAttention等高效注意力机制兼容。
关键创新:FastAV的关键创新在于其针对AV-LLM设计的两阶段剪枝策略,以及利用注意力权重评估token重要性的方法。与传统的token剪枝方法相比,FastAV能够更准确地识别出对AV-LLM性能影响较小的token,从而实现更高的剪枝率和更小的性能损失。此外,FastAV不依赖于完整的注意力图,使其能够与高效注意力机制兼容。
关键设计:FastAV的关键设计包括:1) 使用注意力权重作为token重要性的度量;2) 两阶段剪枝策略,包括全局剪枝和精细剪枝;3) 剪枝率的动态调整,根据不同层的特点和模型性能进行调整;4) 损失函数的设计,在剪枝过程中尽量保持模型性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,FastAV在两个具有代表性的AV-LLM上减少了超过40%的FLOPs,同时保持甚至提高了模型性能。例如,在某个AV-LLM上,FastAV在减少42% FLOPs的同时,性能提升了0.5%。这些结果表明,FastAV是一种高效且有效的AV-LLM token剪枝方法。
🎯 应用场景
FastAV可应用于各种需要处理音视频数据的AV-LLM应用场景,例如智能助手、视频理解、语音识别、多模态对话等。通过降低AV-LLM的计算成本,FastAV可以使其更容易部署在资源受限的设备上,并提高推理速度,从而提升用户体验。该研究对于推动AV-LLM在实际应用中的普及具有重要意义。
📄 摘要(原文)
In this work, we present FastAV, the first token pruning framework tailored for audio-visual large language models (AV-LLMs). While token pruning has been actively explored in standard large language models (LLMs) and vision-language models (LVLMs), its application to AV-LLMs has received little attention, even though multimodal integration substantially increases their token demands. To address this gap, we introduce a pruning strategy that utilizes attention weights to identify tokens emphasized at different stages and estimates their importance. Building on this analysis, FastAV applies a two-stage pruning strategy: (1) global pruning in intermediate layers to remove broadly less influential tokens, and (2) fine pruning in later layers considering the impact on next token generation. Notably, our method does not rely on full attention maps, which makes it fully compatible with efficient attention mechanisms such as FlashAttention. Extensive experiments demonstrate that FastAV reduces FLOPs by more than 40% on two representative AV-LLMs, while preserving or even improving model performance.