Polychronous Wave Computing: Timing-Native Address Selection in Spiking Networks
作者: Natalila G. Berloff
分类: cond-mat.dis-nn, cs.LG, cs.NE, physics.optics
发布日期: 2026-01-19
备注: 23 pages, Supplementary Materials are available at https://www.damtp.cam.ac.uk/user/ngb23/publications/SM_PWC.pdf
💡 一句话要点
提出多时波计算,实现脉冲神经网络中基于时序的原生地址选择。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 脉冲神经网络 神经形态计算 时序编码 波计算 地址选择
📋 核心要点
- 现有神经形态和光子系统通常将事件数字化为时间戳或速率,然后在时钟逻辑中进行选择,未能充分利用脉冲时序蕴含的组合地址空间。
- 论文提出多时波计算(PWC),通过在波域中直接映射相对脉冲延迟到离散输出路径,实现了一种时序原生的地址选择。
- 仿真结果表明,非线性竞争提高了路由保真度,硬件在环相位调整显著提升了时间顺序门的准确率,从55.9%提升至97.2%。
📝 摘要(中文)
本文提出了一种多时波计算(PWC)方法,这是一种基于时序的原生地址选择机制,它将相对脉冲延迟直接映射到波域中的离散输出路径。脉冲时间在旋转坐标系中进行相位编码,并通过可编程多端口干涉仪处理,该干涉仪并行评估K个模板相关性。然后,一个驱动-耗散胜者全得阶段执行物理argmax操作,发射一个one-hot输出端口。推导了由相位包裹和互相关性施加的工作范围,并将时序抖动、静态相位失配和退相干坍缩为单个有效相位噪声预算,其引起的胜者-亚军裕度预测了边界优先失效,并提供了一个仅强度校准目标。仿真表明,与噪声线性强度读数相比,非线性竞争提高了路由保真度,并且硬件在环相位调整将时间顺序门从55.9%的准确率提高到97.2%(在强静态失配下)。PWC为极化子、光子和振荡器平台上的LUT式脉冲神经网络和稀疏top-1门(例如,混合专家路由)提供了一个快速路由协处理器。
🔬 方法详解
问题定义:现有神经形态计算和光子计算系统在处理脉冲神经网络时,通常需要将脉冲事件数字化为时间戳或速率,然后使用时钟逻辑进行地址选择。这种方法无法充分利用脉冲时序所蕴含的丰富信息,限制了计算效率和灵活性。因此,需要一种能够直接利用脉冲时序进行地址选择的机制。
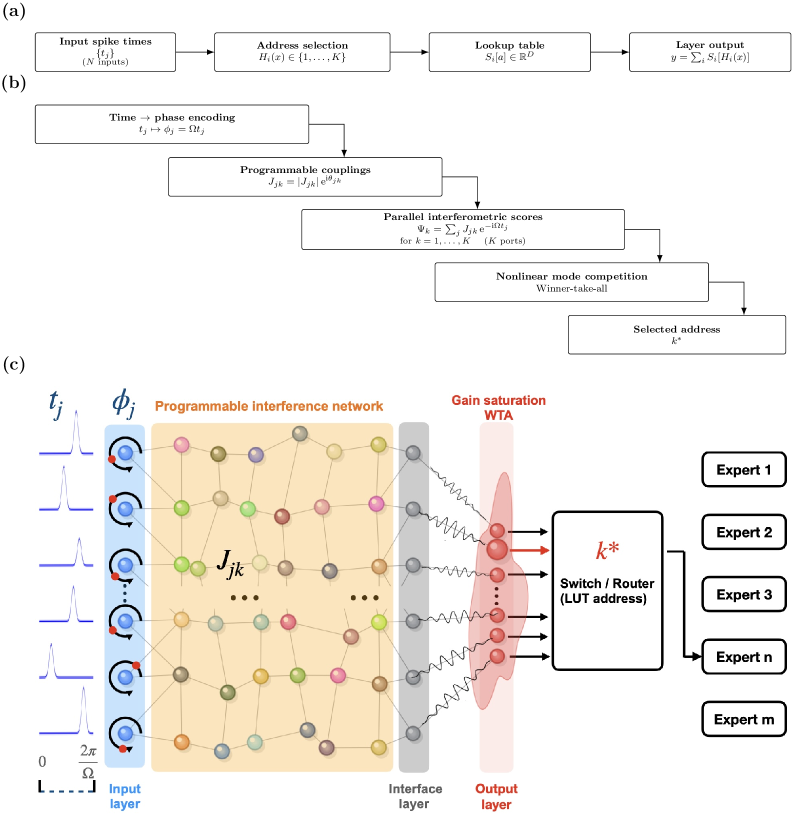
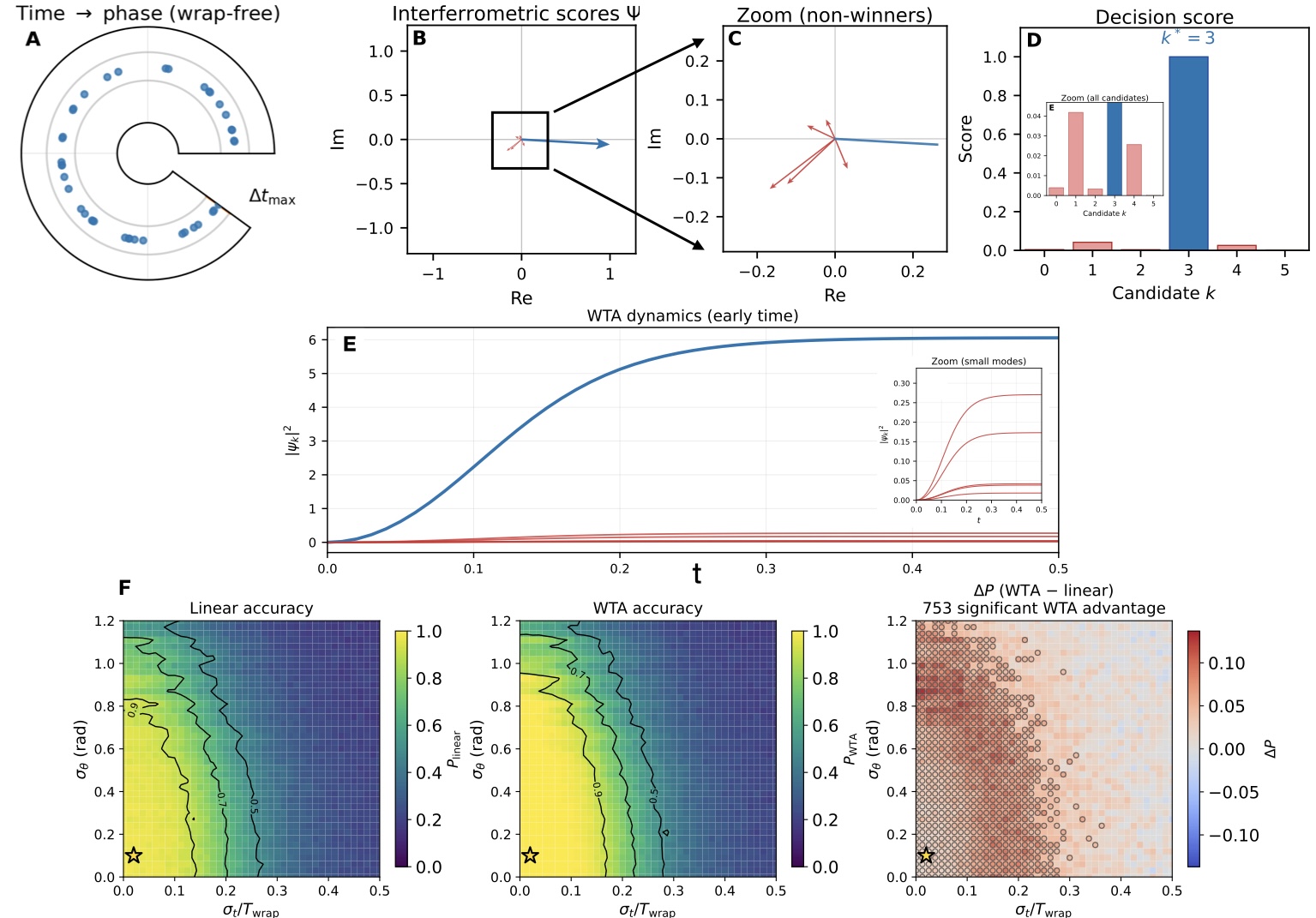
核心思路:论文的核心思路是利用波的干涉和竞争特性,将脉冲时序信息编码到波的相位中,并通过可编程干涉仪实现对不同时序模式的并行匹配和选择。通过胜者全得机制,最终选择与输入脉冲时序最匹配的输出端口,从而实现时序原生的地址选择。
技术框架:PWC系统的整体架构包括以下几个主要模块:1) 相位编码器:将脉冲时间信息编码到波的相位中。2) 可编程多端口干涉仪:并行评估K个模板相关性,实现对不同时序模式的匹配。3) 胜者全得(Winner-Take-All)模块:通过驱动-耗散机制,选择与输入时序最匹配的输出端口。4) 输出端口:输出one-hot编码,指示被选中的地址。
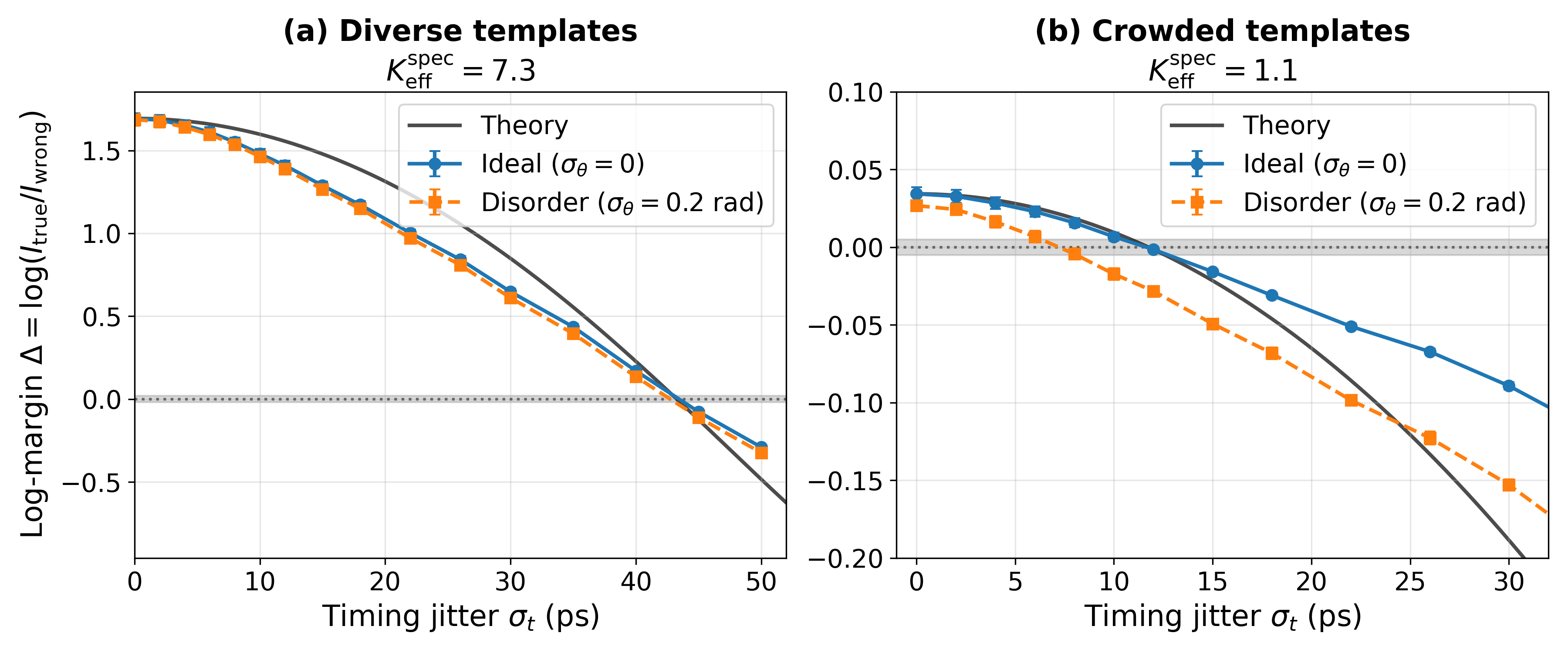
关键创新:PWC的关键创新在于实现了时序原生的地址选择,避免了数字化和时钟逻辑的限制。它利用波的干涉和竞争特性,实现了对脉冲时序信息的并行处理和高效选择。此外,论文还提出了一个有效的相位噪声预算模型,用于评估系统的性能。
关键设计:PWC的关键设计包括:1) 使用旋转坐标系进行相位编码,以处理相对脉冲延迟。2) 设计可编程多端口干涉仪,以实现对不同时序模式的并行匹配。3) 采用驱动-耗散胜者全得机制,以提高选择的鲁棒性和准确性。4) 推导相位噪声预算模型,用于评估系统的性能并指导参数优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,非线性竞争显著提高了路由保真度。在强静态失配条件下,硬件在环相位调整将时间顺序门的准确率从55.9%提高到97.2%。这些结果验证了PWC的有效性和鲁棒性,表明其在实际应用中具有良好的潜力。
🎯 应用场景
PWC可应用于多种领域,包括:1) 脉冲神经网络的快速路由协处理器,加速神经形态计算。2) 混合专家路由,实现高效的top-1选择。3) 光子计算和极化子计算,构建新型计算架构。该研究有望推动人工智能和神经形态计算的发展。
📄 摘要(原文)
Spike timing offers a combinatorial address space, suggesting that timing-based spiking inference can be executed as lookup and routing rather than as dense multiply--accumulate. Yet most neuromorphic and photonic systems still digitize events into timestamps, bins, or rates and then perform selection in clocked logic. We introduce Polychronous Wave Computing (PWC), a timing-native address-selection primitive that maps relative spike latencies directly to a discrete output route in the wave domain. Spike times are phase-encoded in a rotating frame and processed by a programmable multiport interferometer that evaluates K template correlations in parallel; a driven--dissipative winner-take-all stage then performs a physical argmax, emitting a one-hot output port. We derive the operating envelope imposed by phase wrapping and mutual coherence, and collapse timing jitter, static phase mismatch, and dephasing into a single effective phase-noise budget whose induced winner--runner-up margin predicts boundary-first failures and provides an intensity-only calibration target. Simulations show that nonlinear competition improves routing fidelity compared with noisy linear intensity readout, and that hardware-in-the-loop phase tuning rescues a temporal-order gate from 55.9% to 97.2% accuracy under strong static mismatch. PWC provides a fast routing coprocessor for LUT-style spiking networks and sparse top-1 gates (e.g., mixture-of-experts routing) across polaritonic, photonic, and oscillator platforms.