PASs-MoE: Mitigating Misaligned Co-drift among Router and Experts via Pathway Activation Subspaces for Continual Learning
作者: Zhiyan Hou, Haiyun Guo, Haokai Ma, Yandu Sun, Yonghui Yang, Jinqiao Wang
分类: cs.LG, cs.AI
发布日期: 2026-01-19
💡 一句话要点
提出PASs-MoE,通过路径激活子空间缓解持续学习中路由与专家之间的错位共漂移问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 混合专家模型 LoRA 多模态学习 灾难性遗忘 路径激活子空间 指令调优
📋 核心要点
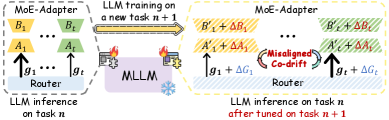
- 现有MoE方法在持续学习中联合更新路由和专家,导致路由偏好与专家适应路径共同漂移,专家职责模糊并加剧遗忘。
- 论文提出路径激活子空间(PASs),通过LoRA诱导的子空间反映输入在专家中的激活路径,为路由提供能力对齐的坐标系。
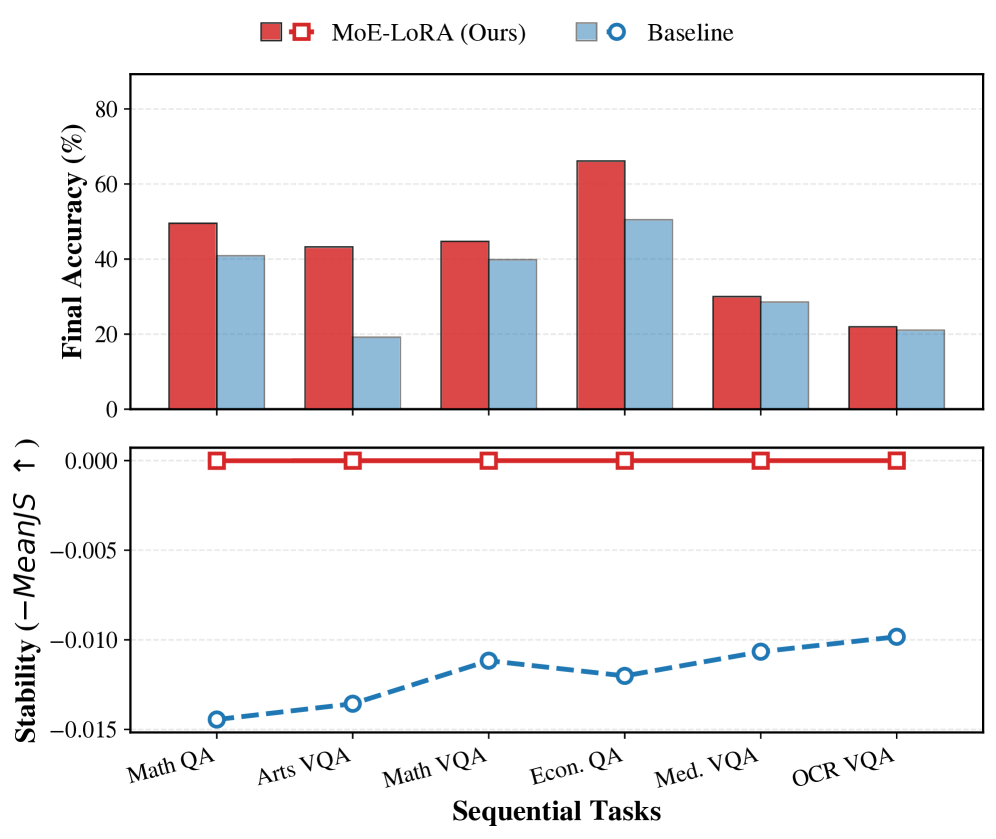
- 提出的PASs-MoE方法在CIT基准测试中,在不增加参数的情况下,显著优于传统持续学习基线和MoE-LoRA变体。
📝 摘要(中文)
持续指令调优(CIT)要求多模态大型语言模型(MLLM)适应一系列任务,同时不忘记先前的能力。一种常见的策略是通过将输入路由到不同的LoRA专家来隔离更新。然而,现有的基于LoRA的混合专家(MoE)方法通常以不加区分的方式联合更新路由器和专家,导致路由器的偏好与专家的适应路径共同漂移,并逐渐偏离早期阶段的输入-专家专业化。我们将这种现象称为错位共漂移,它模糊了专家的职责并加剧了遗忘。为了解决这个问题,我们引入了路径激活子空间(PASs),这是一个LoRA诱导的子空间,反映了输入在每个专家中激活的低秩路径方向,为路由和保存提供了一个能力对齐的坐标系。基于PASs,我们提出了一种固定容量的基于PASs的MoE-LoRA方法,包含两个组件:PAS引导的重加权,它使用每个专家的路径激活信号来校准路由;以及PAS感知的秩稳定化,它选择性地稳定对先前任务重要的秩方向。在CIT基准上的实验表明,我们的方法在准确性和抗遗忘方面始终优于一系列传统的持续学习基线和MoE-LoRA变体,且不增加参数。我们的代码将在接受后发布。
🔬 方法详解
问题定义:论文旨在解决持续学习(Continual Learning)中,多模态大型语言模型(MLLM)在持续指令调优(CIT)过程中出现的“错位共漂移”(Misaligned Co-drift)问题。现有基于LoRA的混合专家(MoE)方法在更新过程中,路由器和专家模块同时更新,导致路由器的偏好逐渐偏离初始的输入-专家专业化,模糊了专家之间的职责,加剧了灾难性遗忘现象。
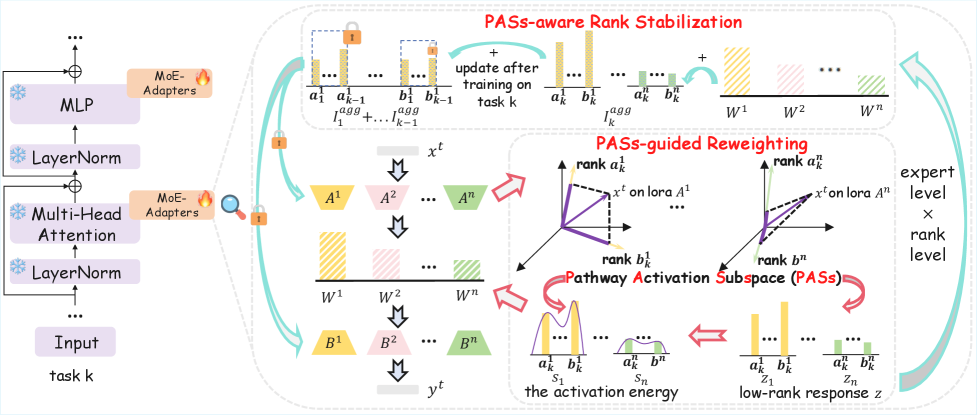
核心思路:论文的核心思路是引入“路径激活子空间”(Pathway Activation Subspaces,PASs)的概念,利用LoRA的低秩特性,捕捉输入在每个专家中激活的低秩路径方向。PASs可以被视为一个能力对齐的坐标系,用于指导路由和知识的保存,从而缓解路由与专家之间的错位共漂移问题。
技术框架:PASs-MoE方法主要包含两个核心组件:1) PAS引导的重加权(PAS-guided Reweighting):利用每个专家的PASs信息,校准路由器的决策,使得路由更加关注与专家能力相关的输入特征。2) PAS感知的秩稳定化(PAS-aware Rank Stabilization):选择性地稳定对先前任务重要的秩方向,防止模型遗忘先前学习到的知识。整体框架是在MoE-LoRA的基础上,引入PASs作为桥梁,连接输入、路由器和专家。
关键创新:论文的关键创新在于提出了PASs的概念,并将其应用于持续学习中的MoE模型。PASs提供了一种新的视角,能够更好地理解输入与专家之间的关系,并指导路由和知识的保存。与现有方法相比,PASs-MoE能够更有效地缓解错位共漂移问题,提高模型的持续学习能力。
关键设计:PAS引导的重加权模块,通过计算输入在每个专家PASs上的投影,得到一个激活信号,用于调整路由器的输出。PAS感知的秩稳定化模块,通过分析每个秩方向对先前任务的重要性,选择性地稳定重要的秩方向,防止模型遗忘。具体实现细节包括如何计算PASs、如何定义激活信号、以及如何选择和稳定重要的秩方向等。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PASs-MoE在持续指令调优(CIT)基准测试中,显著优于一系列传统的持续学习基线和MoE-LoRA变体。在准确性和抗遗忘方面均取得了提升,且无需增加额外的参数。具体性能数据将在论文发表后公开。
🎯 应用场景
该研究成果可应用于需要持续学习能力的多模态大型语言模型,例如智能客服、自动驾驶、智能医疗等领域。通过缓解灾难性遗忘,模型能够不断学习新的知识和技能,同时保持对先前知识的掌握,从而提供更稳定、更可靠的服务。未来的研究可以探索如何将PASs应用于其他类型的模型和任务,进一步提升模型的持续学习能力。
📄 摘要(原文)
Continual instruction tuning (CIT) requires multimodal large language models (MLLMs) to adapt to a stream of tasks without forgetting prior capabilities. A common strategy is to isolate updates by routing inputs to different LoRA experts. However, existing LoRA-based Mixture-of-Experts (MoE) methods often jointly update the router and experts in an indiscriminate way, causing the router's preferences to co-drift with experts' adaptation pathways and gradually deviate from early-stage input-expert specialization. We term this phenomenon Misaligned Co-drift, which blurs expert responsibilities and exacerbates forgetting.To address this, we introduce the pathway activation subspace (PASs), a LoRA-induced subspace that reflects which low-rank pathway directions an input activates in each expert, providing a capability-aligned coordinate system for routing and preservation. Based on PASs, we propose a fixed-capacity PASs-based MoE-LoRA method with two components: PAS-guided Reweighting, which calibrates routing using each expert's pathway activation signals, and PAS-aware Rank Stabilization, which selectively stabilizes rank directions important to previous tasks. Experiments on a CIT benchmark show that our approach consistently outperforms a range of conventional continual learning baselines and MoE-LoRA variants in both accuracy and anti-forgetting without adding parameters. Our code will be released upon acceptance.