PDFInspect: A Unified Feature Extraction Framework for Malicious Document Detection
作者: Sharmila S P
分类: cs.CR, cs.LG
发布日期: 2026-01-19
备注: 6 pages, 2 figures, paper accepted in COMSNETS 2026 conference
💡 一句话要点
PDFInspect:用于恶意文档检测的统一特征提取框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 恶意PDF检测 特征提取 图分析 元数据分析 结构分析
📋 核心要点
- 现有恶意PDF检测方法在特征提取方面存在局限性,难以全面捕捉恶意行为。
- PDFInspect框架融合图、结构和元数据分析,提取丰富的特征表示,提升检测能力。
- 该方法提取170维特征向量,适用于恶意软件分类、异常检测和取证分析等任务。
📝 摘要(中文)
恶意PDF文件的日益普及,需要强大而全面的特征提取技术来进行有效的检测和分析。本文提出了一个统一的框架,该框架集成了基于图的分析、结构分析和元数据驱动的分析,从而为每个PDF文档生成丰富的特征表示。该系统从PDF页面提取文本,并基于成对单词关系构建无向图,从而能够计算图论特征,例如节点数、边密度和聚类系数。同时,该框架解析嵌入的元数据,以量化字符分布、熵模式以及作者、标题和生产者等字段中的不一致性。时间特征源自创建和修改时间戳,以捕获行为签名,而结构元素(包括对象流、字体和嵌入的图像)被量化以反映文档的复杂性。还提取了潜在恶意PDF构造(例如,JavaScript、启动操作)的布尔标志。这些特征共同构成了一个高维向量表示(170维),非常适合下游任务,例如恶意软件分类、异常检测和取证分析。所提出的方法是可扩展的、可扩展的,并且旨在支持实际的PDF威胁情报工作流程。
🔬 方法详解
问题定义:当前恶意PDF检测面临的挑战是如何提取足够全面和具有区分性的特征,以有效识别恶意文档。现有方法可能侧重于单一类型的特征(如结构或元数据),无法充分利用PDF文档中蕴含的丰富信息,导致检测精度受限。此外,恶意PDF制造者不断演化其技术,使得传统的基于签名的检测方法难以应对。
核心思路:PDFInspect的核心思路是通过整合多种分析方法,从PDF文档的不同层面提取特征,从而构建一个更全面、更鲁棒的特征表示。具体而言,它结合了基于图的文本分析、结构化元素分析和元数据分析,以捕捉恶意PDF的各种行为特征。
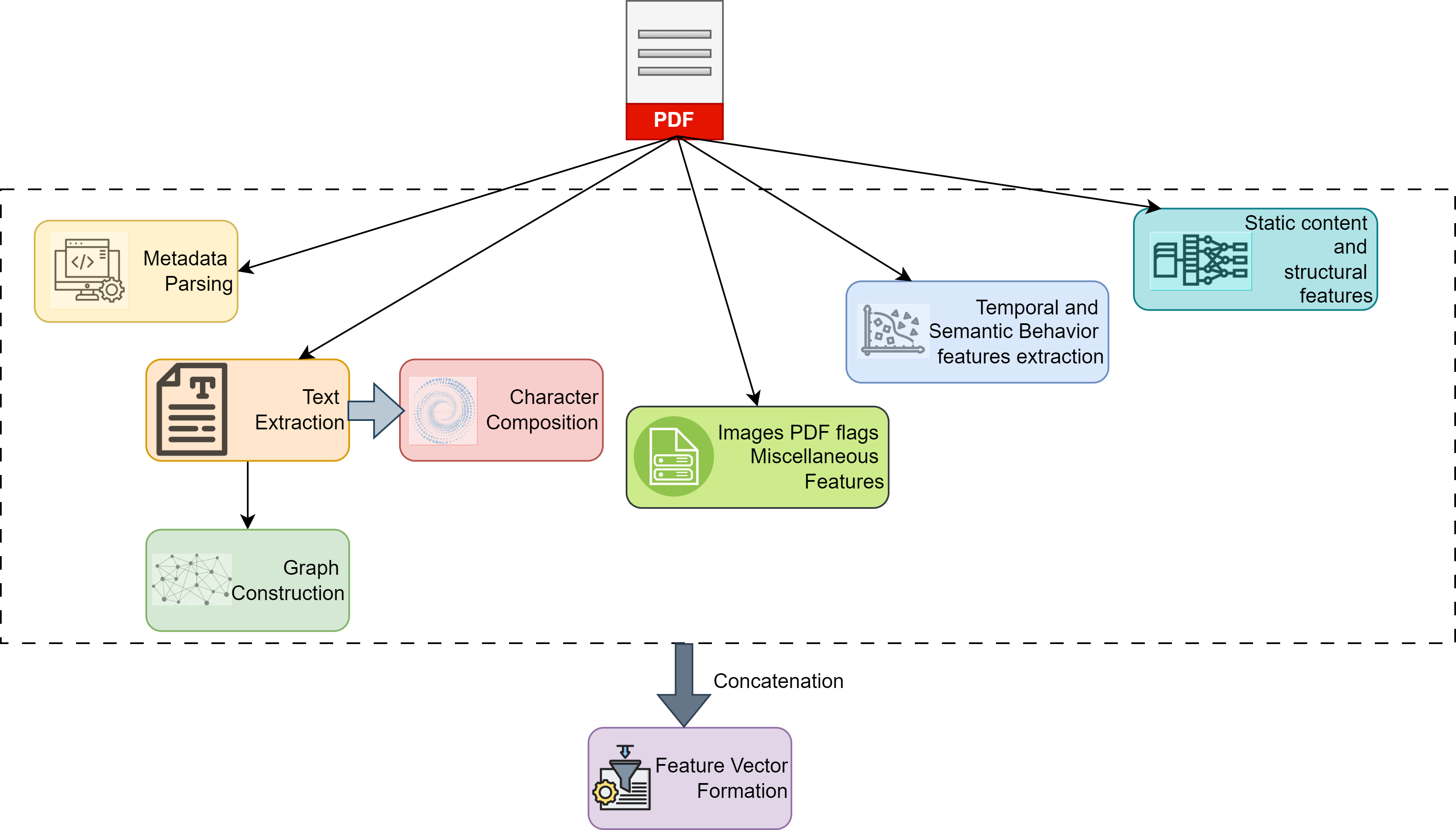
技术框架:PDFInspect框架包含以下主要模块:1) 文本提取与图构建:从PDF页面提取文本,并基于词语之间的关系构建无向图。2) 图特征计算:计算图的节点数、边密度、聚类系数等图论特征。3) 元数据解析:解析PDF文档的元数据,提取字符分布、熵模式以及字段间的不一致性等特征。4) 结构元素分析:量化对象流、字体和嵌入图像等结构元素,反映文档的复杂性。5) 恶意行为标志提取:提取JavaScript和启动操作等潜在恶意行为的布尔标志。最终,将所有提取的特征组合成一个170维的特征向量。
关键创新:PDFInspect的关键创新在于其统一的特征提取框架,它将图分析、结构分析和元数据分析相结合,从而能够更全面地捕捉恶意PDF的行为特征。与仅依赖单一类型特征的方法相比,PDFInspect能够更好地应对恶意PDF制造者的对抗性攻击。
关键设计:在图构建方面,论文采用基于词语关系的无向图,这种设计能够有效地捕捉文本中的语义信息。在元数据分析方面,论文关注字段间的不一致性,这是一种常见的恶意PDF伪装手段。在结构元素分析方面,论文量化了对象流、字体和嵌入图像等关键元素,这些元素的异常使用往往与恶意行为相关。
🖼️ 关键图片
📊 实验亮点
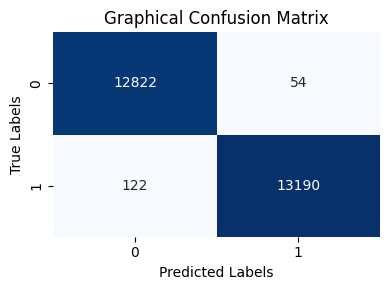
该研究构建了一个包含170维特征的向量,能够有效用于恶意软件分类。虽然论文中没有明确给出性能数据和对比基线,但强调了该方法能够支持实际的PDF威胁情报工作流程,表明其具有良好的可扩展性和实用性。未来的工作可以进一步评估该框架在真实数据集上的性能表现,并与其他先进的恶意PDF检测方法进行比较。
🎯 应用场景
PDFInspect框架可应用于恶意软件分类、异常检测和取证分析等领域。该框架能够帮助安全分析人员更有效地识别和分析恶意PDF文档,从而提高网络安全防御能力。此外,该框架的可扩展性使其能够适应不断演化的PDF威胁环境,具有重要的实际应用价值。
📄 摘要(原文)
The increasing prevalence of malicious Portable Document Format (PDF) files necessitates robust and comprehensive feature extraction techniques for effective detection and analysis. This work presents a unified framework that integrates graph-based, structural, and metadata-driven analysis to generate a rich feature representation for each PDF document. The system extracts text from PDF pages and constructs undirected graphs based on pairwise word relationships, enabling the computation of graph-theoretic features such as node count, edge density, and clustering coefficient. Simultaneously, the framework parses embedded metadata to quantify character distributions, entropy patterns, and inconsistencies across fields such as author, title, and producer. Temporal features are derived from creation and modification timestamps to capture behavioral signatures, while structural elements including, object streams, fonts, and embedded images, are quantified to reflect document complexity. Boolean flags for potentially malicious PDF constructs (e.g., JavaScript, launch actions) are also extracted. Together, these features form a high-dimensional vector representation (170 dimensions) that is well-suited for downstream tasks such as malware classification, anomaly detection, and forensic analysis. The proposed approach is scalable, extensible, and designed to support real-world PDF threat intelligence workflows.6