Semi-supervised Instruction Tuning for Large Language Models on Text-Attributed Graphs
作者: Zixing Song, Irwin King
分类: cs.LG
发布日期: 2026-01-19
💡 一句话要点
提出半监督指令调优方法以解决图学习中的标签稀缺问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 半监督学习 图学习 大型语言模型 指令调优 节点分类 社交网络 文本属性图
📋 核心要点
- 现有的图学习方法在社交领域面临标注数据稀缺的问题,获取专家标签既昂贵又缓慢。
- 本文提出的SIT-Graph方法通过半监督学习,利用未标记节点的信息来增强模型性能。
- 实验结果显示,SIT-Graph在最新的图指令调优方法中,性能提升超过20%,尤其在低标签比例的情况下。
📝 摘要(中文)
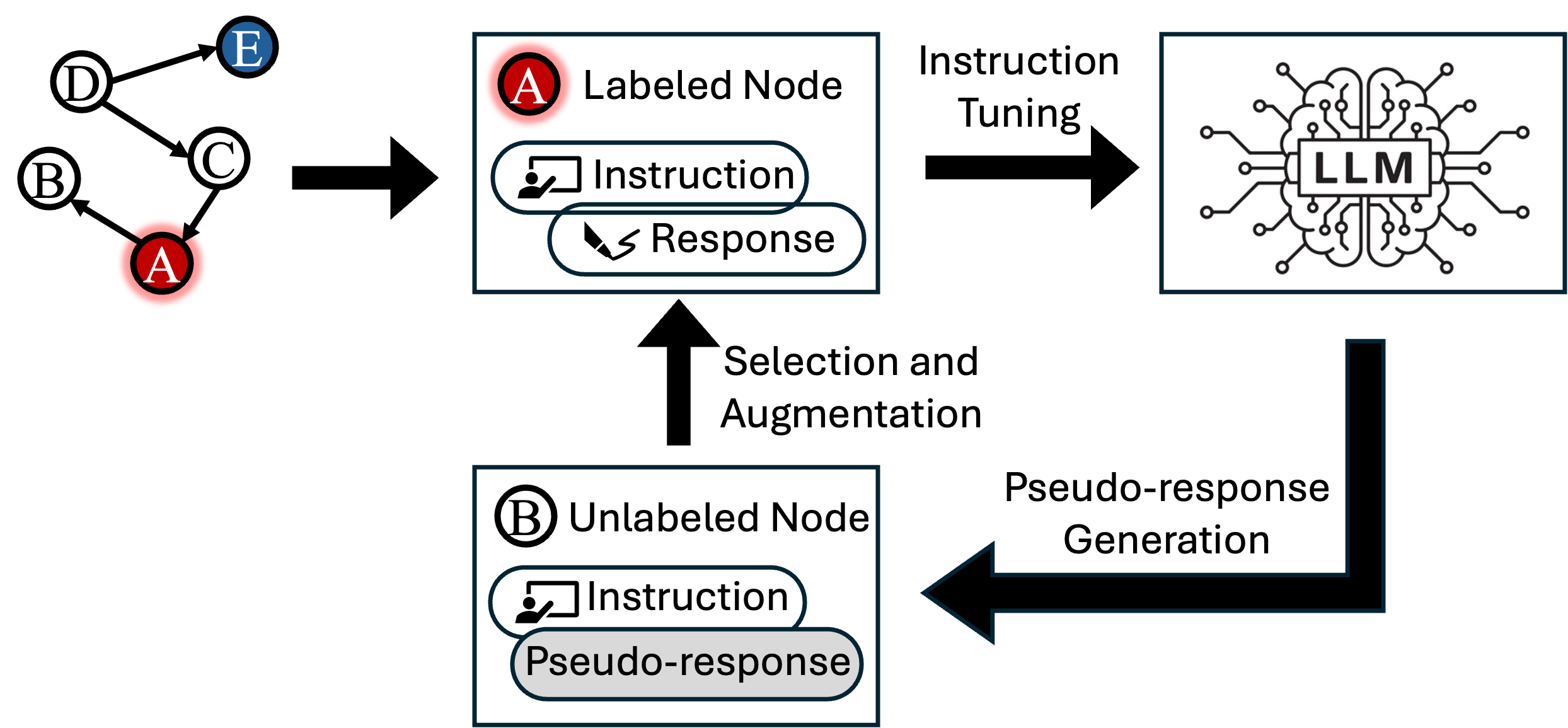
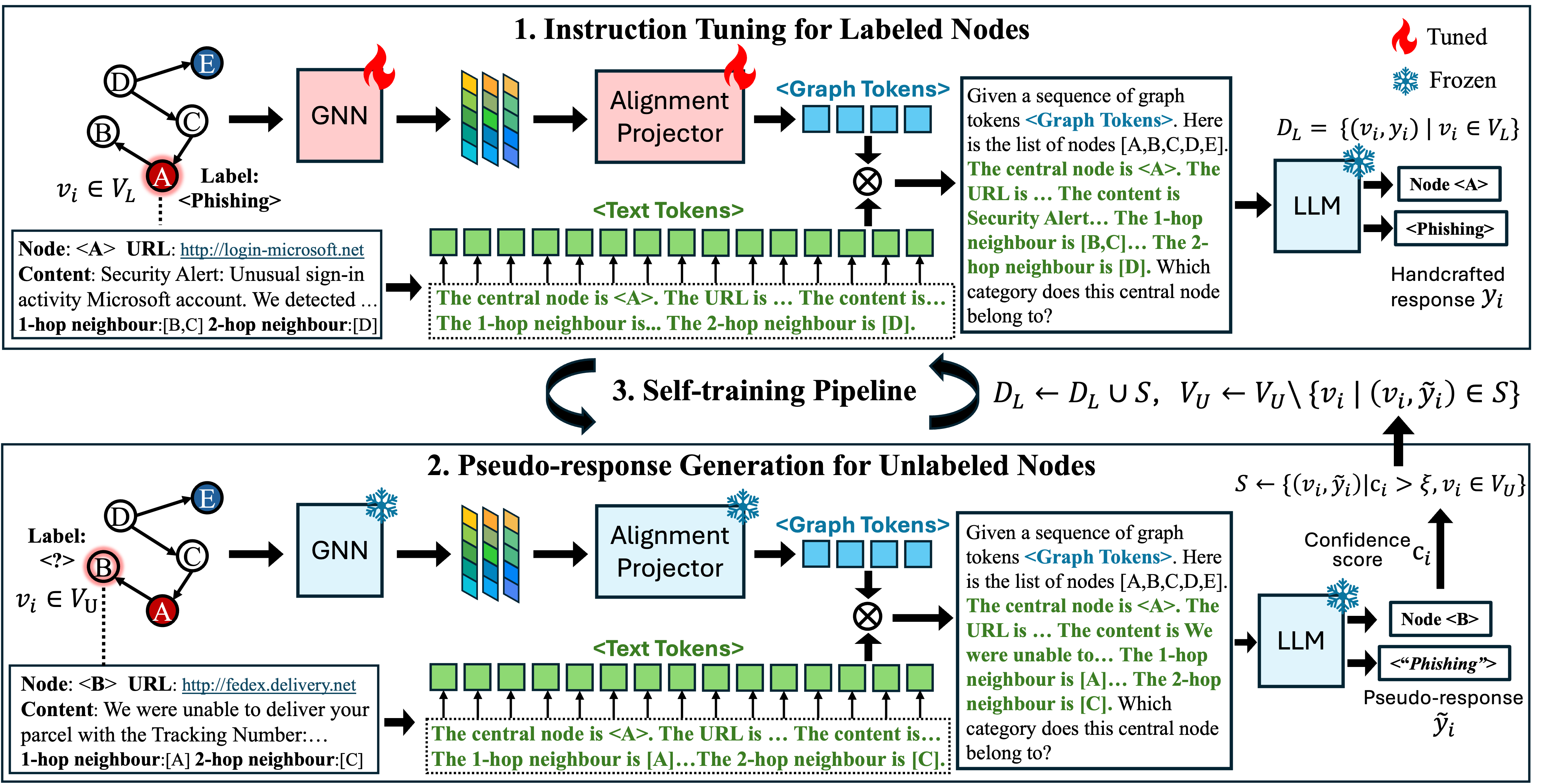
大型语言模型(LLMs)在分析文本属性图方面展现出新兴的推理能力。尽管指令调优是将预训练LLMs适应图学习任务(如节点分类)的主要方法,但其需要大量标注的(指令,输出)对,这在社交领域尤其困难。为了解决这一问题,本文提出了一种名为SIT-Graph的新型半监督指令调优管道,能够有效利用未标记节点的信息。SIT-Graph通过迭代自我训练过程,首先使用标记节点构建指令对进行微调,然后为未标记节点生成经过置信度过滤的伪响应,逐步增强数据集。实验表明,SIT-Graph在低标签比例设置下,显著提升了图学习方法的性能,提升幅度超过20%。
🔬 方法详解
问题定义:本文旨在解决图学习任务中对标注数据的高需求,尤其是在社交领域,获取专家标签的成本和时间都非常高。现有的图指令调优方法未能充分利用未标记节点的信息,导致性能受限。
核心思路:SIT-Graph通过半监督学习策略,利用未标记节点的潜在关联性,增强模型的学习能力。该方法通过迭代自我训练,逐步改善模型的预测能力。
技术框架:SIT-Graph的整体架构包括两个主要阶段:首先,使用标记节点构建指令对进行初步微调;其次,生成未标记节点的伪响应,并利用这些伪响应进行后续的微调。
关键创新:SIT-Graph的创新在于其模型无关性,能够与任何使用LLMs作为预测器的图指令调优方法无缝集成,显著提升了模型对节点关联性的理解。
关键设计:在设计上,SIT-Graph采用置信度过滤机制来选择伪响应,确保生成的伪标签具有较高的可靠性,从而增强训练数据集的质量。
🖼️ 关键图片

📊 实验亮点
实验结果表明,将SIT-Graph集成到最先进的图指令调优方法中,性能提升超过20%。在低标签比例设置下,SIT-Graph显著改善了模型在文本属性图基准测试中的表现,展示了其强大的实用性。
🎯 应用场景
该研究的潜在应用领域包括社交网络分析、推荐系统和知识图谱构建等。在这些领域,获取标注数据的成本高昂且耗时,SIT-Graph能够有效利用未标记数据,提升模型的实用性和性能,具有重要的实际价值和广泛的应用前景。
📄 摘要(原文)
The emergent reasoning capabilities of Large Language Models (LLMs) offer a transformative paradigm for analyzing text-attributed graphs. While instruction tuning is the prevailing method for adapting pre-trained LLMs to graph learning tasks like node classification, it requires a substantial volume of annotated (INSTRUCTION, OUTPUT) pairs deriving from labeled nodes. This requirement is particularly prohibitive in the social domain, where obtaining expert labels for sensitive or evolving content is costly and slow. Furthermore, standard graph instruction tuning fails to exploit the vast amount of unlabeled nodes, which contain latent correlations due to edge connections that are beneficial for downstream predictions. To bridge this gap, we propose a novel Semi-supervised Instruction Tuning pipeline for Graph Learning, named SIT-Graph. Notably, SIT-Graph is model-agnostic and can be seamlessly integrated into any graph instruction tuning method that utilizes LLMs as the predictor. SIT-Graph operates via an iterative self-training process. Initially, the model is fine-tuned using instruction pairs constructed solely from the labeled nodes. Then it generates confidence-filtered pseudo-responses for unlabeled nodes to strategically augment the dataset for the next round of fine-tuning. Finally, this iterative refinement progressively aligns the LLM with the underlying node correlations. Extensive experiments demonstrate that when incorporated into state-of-the-art graph instruction tuning methods, SIT-Graph significantly enhances their performance on text-attributed graph benchmarks, achieving over 20% improvement under the low label ratio settings.