Distilling Time Series Foundation Models for Efficient Forecasting
作者: Yuqi Li, Kuiye Ding, Chuanguang Yang, Szu-Yu Chen, Yingli Tian
分类: cs.LG, cs.AI
发布日期: 2026-01-19
备注: Accepted by ICASSP-2026
🔗 代码/项目: GITHUB
💡 一句话要点
提出DistilTS,用于高效蒸馏时序基础模型以实现高效预测。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时序预测 知识蒸馏 模型压缩 基础模型 时间序列分析
📋 核心要点
- 现有时序基础模型参数量巨大,部署成本高昂,而通用知识蒸馏方法难以直接应用于时序预测。
- DistilTS通过范围加权目标平衡不同预测范围的学习,并采用时间对齐策略减少架构不匹配。
- 实验表明,DistilTS在显著减少参数和加速推理的同时,保持了与全尺寸TSFM相当的预测性能。
📝 摘要(中文)
时序基础模型(TSFMs)通过大规模预训练实现了强大的预测性能,但其庞大的参数规模使得部署成本高昂。知识蒸馏为模型压缩提供了一种自然而有效的方法,但为通用机器学习任务开发的技术由于时序预测的独特性而无法直接应用。为了解决这个问题,我们提出了DistilTS,这是第一个专门为TSFM设计的蒸馏框架。DistilTS解决了两个关键挑战:(1)特定于预测的任务难度差异,其中均匀加权使得优化被更容易的短期范围所主导,而长期范围接收到较弱的监督;(2)架构差异,这是蒸馏中的一个普遍挑战,为此我们设计了一种时序对齐机制。为了克服这些问题,DistilTS引入了范围加权目标来平衡跨范围的学习,以及一种减少架构不匹配的时间对齐策略,从而实现紧凑的模型。在多个基准上的实验表明,DistilTS实现了与全尺寸TSFM相当的预测性能,同时将参数减少高达1/150,并将推理速度提高高达6000倍。代码可在https://github.com/itsnotacie/DistilTS-ICASSP2026获得。
🔬 方法详解
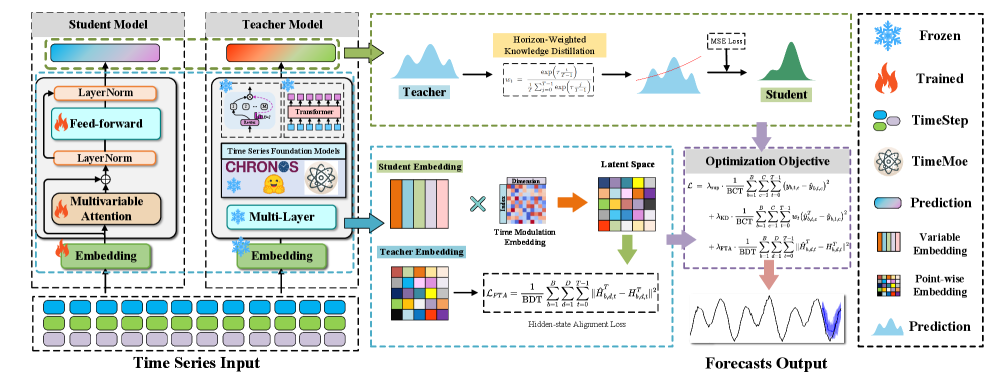
问题定义:论文旨在解决时序基础模型(TSFMs)参数量过大,导致部署成本高昂的问题。现有的通用知识蒸馏方法无法有效应用于时序预测,主要痛点在于:一是不同预测范围(horizon)的任务难度差异大,简单平均损失会导致模型过度关注短期预测,而忽略长期预测;二是学生模型和教师模型之间存在架构差异,影响蒸馏效果。
核心思路:论文的核心思路是设计一种专门针对时序基础模型的知识蒸馏框架DistilTS,通过引入范围加权目标和时间对齐策略,解决任务难度差异和架构差异带来的问题,从而在保证预测性能的前提下,显著减小模型规模。
技术框架:DistilTS框架主要包含两个关键模块:范围加权目标和时间对齐策略。范围加权目标通过对不同预测范围的损失函数进行加权,平衡模型在不同范围上的学习效果。时间对齐策略则通过对学生模型和教师模型的中间层特征进行对齐,减少架构差异带来的影响。整体流程是先用大型TSFM作为教师模型,然后使用DistilTS框架训练小型学生模型,最终得到一个参数量小、预测性能好的时序预测模型。
关键创新:DistilTS的关键创新在于针对时序预测任务的特性,提出了范围加权目标和时间对齐策略。范围加权目标解决了传统蒸馏方法中存在的任务难度差异问题,使得模型能够更好地学习长期预测。时间对齐策略则解决了学生模型和教师模型之间的架构差异问题,提高了蒸馏效果。
关键设计:范围加权目标的设计是根据不同预测范围的难度进行加权,例如,可以对长期预测范围赋予更高的权重。时间对齐策略的具体实现方式可以是最小化学生模型和教师模型对应时间步的特征之间的距离,例如使用均方误差(MSE)作为损失函数。具体的网络结构选择和参数设置需要根据具体的TSFM和数据集进行调整。
🖼️ 关键图片
📊 实验亮点
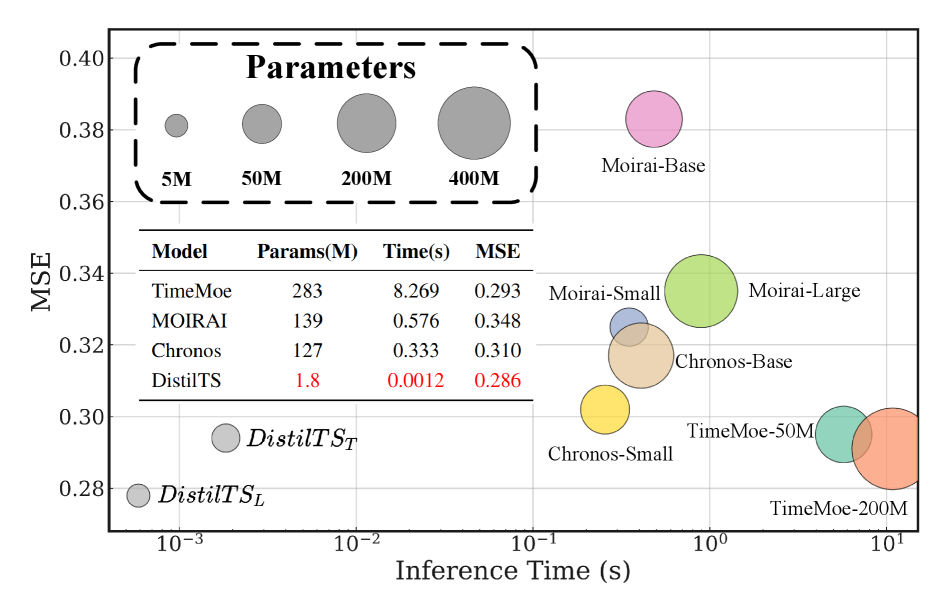
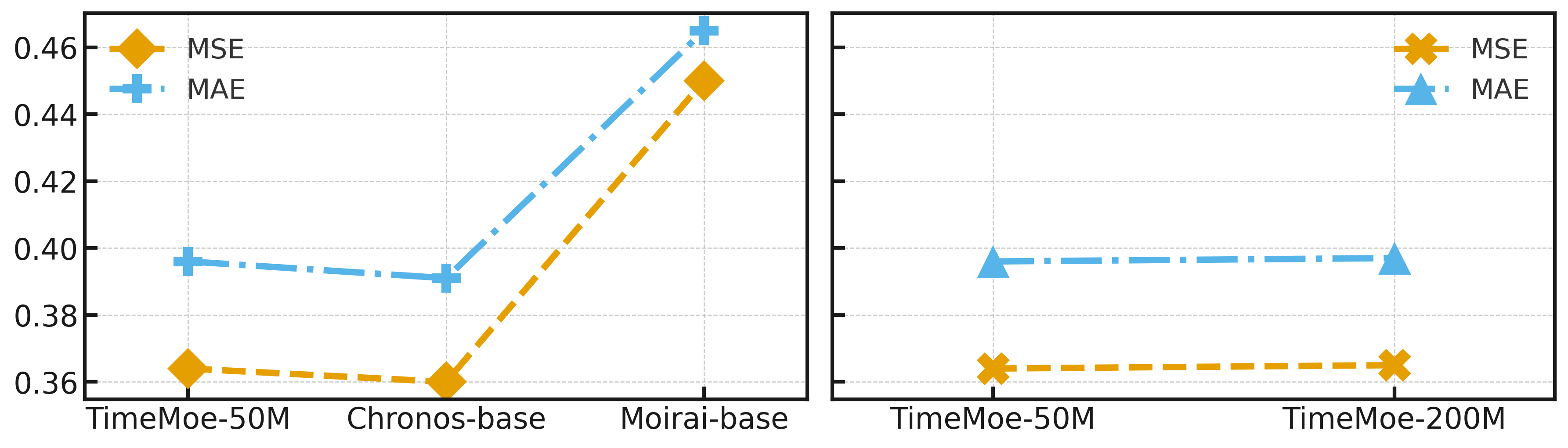
实验结果表明,DistilTS在多个基准数据集上实现了与全尺寸TSFM相当的预测性能,同时将参数减少高达1/150,并将推理速度提高高达6000倍。例如,在某个数据集上,DistilTS在保持预测精度不变的情况下,将模型大小从1.5GB压缩到10MB以下。
🎯 应用场景
DistilTS可应用于各种需要高效时序预测的场景,例如:智能电网负荷预测、金融市场预测、供应链管理、交通流量预测等。通过减小模型规模,降低部署成本,DistilTS使得时序基础模型能够更广泛地应用于资源受限的边缘设备和移动设备,实现更智能化的决策。
📄 摘要(原文)
Time Series foundation models (TSFMs) deliver strong forecasting performance through large-scale pretraining, but their large parameter sizes make deployment costly. While knowledge distillation offers a natural and effective approach for model compression, techniques developed for general machine learning tasks are not directly applicable to time series forecasting due to the unique characteristics. To address this, we present DistilTS, the first distillation framework specifically designed for TSFMs. DistilTS addresses two key challenges: (1) task difficulty discrepancy, specific to forecasting, where uniform weighting makes optimization dominated by easier short-term horizons, while long-term horizons receive weaker supervision; and (2) architecture discrepancy, a general challenge in distillation, for which we design an alignment mechanism in the time series forecasting. To overcome these issues, DistilTS introduces horizon-weighted objectives to balance learning across horizons, and a temporal alignment strategy that reduces architectural mismatch, enabling compact models. Experiments on multiple benchmarks demonstrate that DistilTS achieves forecasting performance comparable to full-sized TSFMs, while reducing parameters by up to 1/150 and accelerating inference by up to 6000x. Code is available at: https://github.com/itsnotacie/DistilTS-ICASSP2026.