Distribution-Centric Policy Optimization Dominates Exploration-Exploitation Trade-off
作者: Zhaochun Li, Chen Wang, Jionghao Bai, Shisheng Cui, Ge Lan, Zhou Zhao, Yue Wang
分类: cs.LG
发布日期: 2026-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出分布中心策略优化(DCPO),解决LLM强化学习中探索-利用难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大语言模型 探索-利用 策略优化 分布正则化
📋 核心要点
- 大语言模型强化学习面临探索-利用困境,现有样本中心方法依赖偶然性,缺乏对策略的有效控制。
- DCPO从分布角度出发,通过分布级别的正则化实现可控熵,引导策略探索,无需外部采样。
- 实验表明,DCPO在多个模型和基准测试中显著优于GRPO,平均提升约20%,提升了探索效率。
📝 摘要(中文)
探索-利用(EE)平衡是大语言模型(LLM)强化学习中的核心挑战。使用Group Relative Policy Optimization (GRPO)时,训练往往由利用驱动:熵单调递减,样本收敛,探索逐渐消失。现有方法大多是 extbf{样本中心}的:它们寻找或奖励稀有样本,假设探索来自新颖的轨迹和token。这些启发式方法依赖于信息丰富的样本的“运气”,缺乏对策略的原则性控制,并且通常产生有限或不一致的收益。本文首次引入了强化学习的 extbf{分布中心}视角,其中探索始终由“更好”的目标分布引导,并揭示了策略抵抗熵崩溃的能力由分布本身而不是单个样本决定。基于此,我们提出了分布中心策略优化(DCPO),它将熵正则化重新定义为分布级别的正则化。DCPO完全在策略上实现可控熵,无需从外部分布采样,从而在保持训练稳定性的同时实现高效探索。在多个模型和七个基准测试中,DCPO比GRPO平均提高了约20%。总的来说,DCPO用分布级别的原则取代了样本级别的启发式方法,为可控探索和更强的EE平衡提供了一个理论基础和灵活的框架。
🔬 方法详解
问题定义:论文旨在解决大语言模型强化学习中,由于过度“利用”导致的探索不足问题。现有基于样本的探索方法,例如奖励稀有样本,存在依赖样本偶然性、缺乏理论指导、效果不稳定等问题。这些方法无法有效控制策略的探索行为,导致模型容易陷入局部最优。
核心思路:论文的核心在于将探索问题从“样本中心”视角转变为“分布中心”视角。作者认为,策略的探索能力是由其分布特性决定的,而非仅仅依赖于个别样本。因此,通过直接对策略分布进行正则化,可以更有效地控制探索行为,避免熵崩溃。
技术框架:DCPO的核心框架是在策略优化过程中,引入分布级别的熵正则化。具体来说,DCPO不再像传统方法那样关注单个样本的奖励,而是关注整个策略分布与目标分布之间的差异。通过最小化这种差异,可以引导策略向更“好”的分布演进,从而实现更有效的探索。整体流程是在策略梯度更新过程中,加入一个基于分布差异的正则化项。
关键创新:DCPO最重要的创新在于其“分布中心”的视角。与以往基于样本的启发式方法不同,DCPO直接对策略分布进行建模和控制,从而实现了更理论化、更可控的探索。这种方法避免了对特定样本的依赖,提高了探索的稳定性和效率。
关键设计:DCPO的关键设计在于如何定义和计算策略分布与目标分布之间的差异。论文中可能采用了KL散度或其他分布距离度量作为正则化项,并将其加入到策略梯度更新的目标函数中。具体的参数设置可能包括正则化系数的大小,以及目标分布的选取方式。此外,可能还涉及到一些网络结构上的调整,以更好地支持分布级别的优化。
🖼️ 关键图片
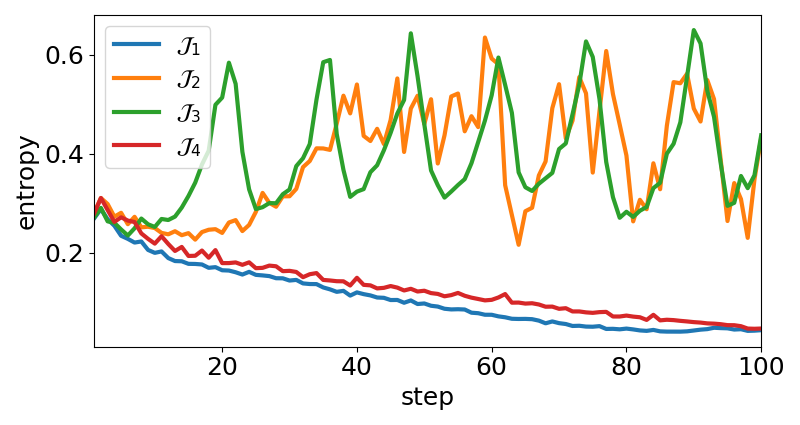
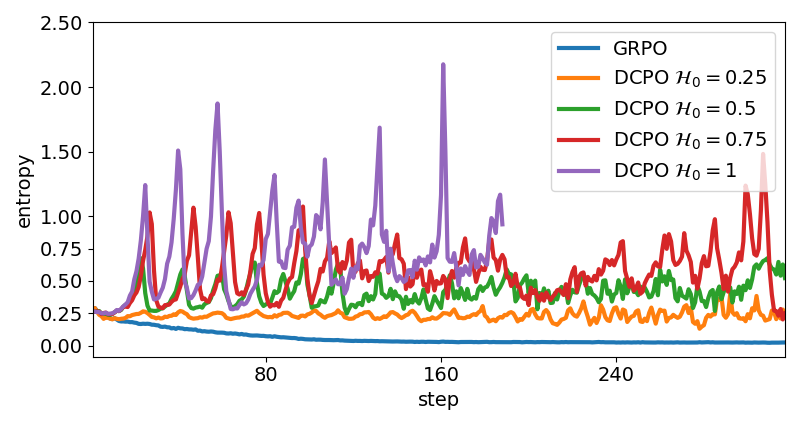
📊 实验亮点
DCPO在多个模型和七个基准测试中进行了验证,实验结果表明,DCPO相比于GRPO,平均提高了约20%。这一显著的性能提升表明,DCPO能够更有效地平衡探索和利用,从而学习到更优的策略。实验结果也验证了“分布中心”视角在强化学习中的有效性。
🎯 应用场景
DCPO可应用于各种需要大语言模型进行策略学习的场景,例如对话生成、文本摘要、代码生成等。通过提升探索能力,DCPO可以帮助模型学习到更优的策略,生成更符合人类意图、更具创造性的内容。该方法在智能客服、内容创作、软件开发等领域具有潜在应用价值。
📄 摘要(原文)
The exploration-exploitation (EE) trade-off is a central challenge in reinforcement learning (RL) for large language models (LLMs). With Group Relative Policy Optimization (GRPO), training tends to be exploitation driven: entropy decreases monotonically, samples convergence, and exploration fades. Most existing fixes are \textbf{sample-centric}: they seek or bonus rare samples, assuming exploration comes from novel trajectories and tokens. These heuristics depend on the "luck" of informative samples, lack principled control of the policy, and often yield limited or inconsistent gains. In this work, we are the first to introduce a \textbf{distribution-centric} perspective for RL, in which exploration is always guided by a "better" target distribution, and reveal that a policy's ability to resist entropy collapse is governed by the distribution itself rather than individual samples. Building on this insight, we propose Distribution-Centric Policy Optimization (DCPO), which reformulates entropy regulation as distribution-level regularization. DCPO achieves controllable entropy fully on-policy without sampling from external distributions, enabling efficient exploration while maintaining training stability. Across multiple models and seven benchmarks, DCPO improves over GRPO by about 20\% on average. Overall, DCPO replaces sample-level heuristics with distribution-level principles, offering a theoretically grounded and flexible framework for controllable exploration and a stronger EE trade-off. The code is available in https://github.com/597358816/DCPO.