Unlocking the Potentials of Retrieval-Augmented Generation for Diffusion Language Models
作者: Chuanyue Yu, Jiahui Wang, Yuhan Li, Heng Chang, Ge Lan, Qingyun Sun, Jia Li, Jianxin Li, Ziwei Zhang
分类: cs.LG, cs.CL
发布日期: 2026-01-16
备注: Preprints
💡 一句话要点
提出SPREAD框架,解决检索增强扩散语言模型中的语义漂移问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 检索增强生成 语义漂移 查询相关性 去噪策略 自然语言处理 文本生成
📋 核心要点
- 现有检索增强的扩散语言模型存在响应语义漂移问题,导致生成内容精度下降。
- SPREAD框架通过查询相关性引导的去噪策略,主动引导去噪轨迹,保持与查询的语义对齐。
- 实验结果表明,SPREAD显著提高了生成答案的精度,有效缓解了响应语义漂移问题。
📝 摘要(中文)
扩散语言模型(DLMs)最近在自然语言处理任务中表现出卓越的能力。然而,检索增强生成(RAG)在增强大型语言模型(LLMs)方面取得了巨大成功,但由于LLM和DLM解码之间的根本差异,RAG在DLM中的潜力尚未得到充分探索。为了填补这一关键空白,我们系统地测试了RAG框架内DLM的性能。我们的研究结果表明,与RAG结合的DLM显示出强大的潜力,对上下文信息的依赖性更强,但生成精度有限。我们发现了一个关键的潜在问题:响应语义漂移(RSD),即生成的答案逐渐偏离查询的原始语义,导致低精度内容。我们将这个问题追溯到DLM中的去噪策略,该策略在整个迭代去噪过程中未能保持与查询的语义对齐。为了解决这个问题,我们提出了一种新的语义保持检索增强扩散(SPREAD)框架,该框架引入了一种查询相关性引导的去噪策略。通过主动引导去噪轨迹,SPREAD确保生成结果始终锚定于查询的语义,并有效抑制漂移。实验结果表明,SPREAD显著提高了RAG框架内生成答案的精度,并有效缓解了RSD。
🔬 方法详解
问题定义:论文旨在解决检索增强扩散语言模型(DLMs)在生成过程中出现的响应语义漂移(Response Semantic Drift, RSD)问题。现有的DLMs在结合检索增强生成(RAG)时,虽然能够利用上下文信息,但由于其迭代去噪的特性,容易在生成过程中逐渐偏离原始查询的语义,导致生成答案的精度降低。
核心思路:论文的核心思路是提出一种语义保持的检索增强扩散(Semantic-Preserving REtrieval-Augmented Diffusion, SPREAD)框架,通过在去噪过程中引入查询相关性引导,确保生成过程始终与原始查询的语义保持一致,从而抑制语义漂移。
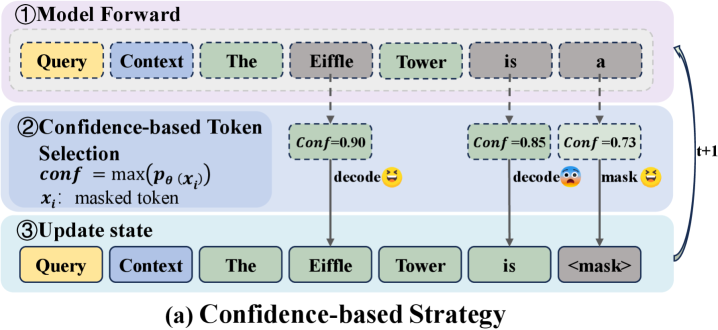
技术框架:SPREAD框架主要包含以下几个关键模块:1) 检索模块:用于从外部知识库中检索与查询相关的文档;2) 扩散模型:作为生成模型的核心,负责从噪声中逐步生成文本;3) 查询相关性引导模块:这是SPREAD的关键创新,它在去噪过程中引入查询相关性信息,引导生成过程朝着与查询语义一致的方向进行。整体流程是:首先,利用检索模块获取相关文档;然后,将查询和检索到的文档输入到扩散模型中;最后,在去噪过程中,利用查询相关性引导模块,调整每一步的生成方向,确保语义一致性。
关键创新:SPREAD最重要的技术创新点在于其查询相关性引导的去噪策略。与传统的DLMs不同,SPREAD不是简单地进行迭代去噪,而是在每一步去噪过程中都考虑查询的相关性,从而避免了语义漂移的发生。这种方法能够更有效地利用检索到的信息,生成更准确、更相关的答案。
关键设计:查询相关性引导模块的具体实现方式未知,论文中可能涉及特定的损失函数设计,用于衡量生成文本与查询之间的语义相关性,并将其作为去噪过程的约束条件。此外,可能还涉及对扩散模型的网络结构进行调整,以便更好地融入查询相关性信息。具体的参数设置和网络结构细节需要在论文中进一步查找。
🖼️ 关键图片
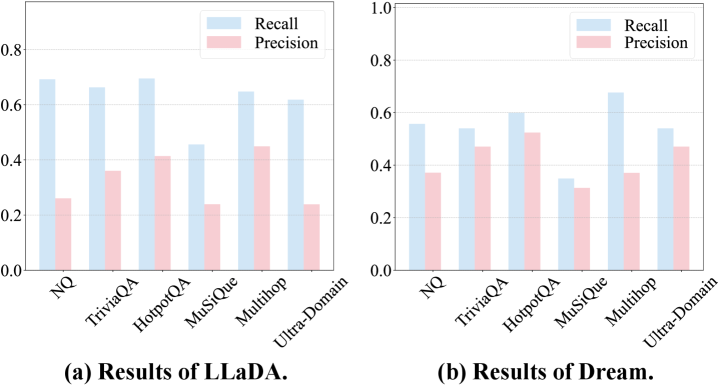

📊 实验亮点
实验结果表明,SPREAD框架能够显著提高检索增强扩散语言模型的生成精度,有效缓解响应语义漂移问题。具体的性能数据和对比基线需要在论文中查找,但摘要中明确指出SPREAD在精度方面取得了显著提升。
🎯 应用场景
该研究成果可应用于问答系统、对话生成、文本摘要等领域,尤其是在需要高精度和语义一致性的场景下。通过缓解语义漂移问题,可以提高生成内容的质量和可靠性,增强用户体验。未来,该方法有望推广到其他生成模型中,进一步提升生成模型的性能。
📄 摘要(原文)
Diffusion Language Models (DLMs) have recently demonstrated remarkable capabilities in natural language processing tasks. However, the potential of Retrieval-Augmented Generation (RAG), which shows great successes for enhancing large language models (LLMs), has not been well explored, due to the fundamental difference between LLM and DLM decoding. To fill this critical gap, we systematically test the performance of DLMs within the RAG framework. Our findings reveal that DLMs coupled with RAG show promising potentials with stronger dependency on contextual information, but suffer from limited generation precision. We identify a key underlying issue: Response Semantic Drift (RSD), where the generated answer progressively deviates from the query's original semantics, leading to low precision content. We trace this problem to the denoising strategies in DLMs, which fail to maintain semantic alignment with the query throughout the iterative denoising process. To address this, we propose Semantic-Preserving REtrieval-Augmented Diffusion (SPREAD), a novel framework that introduces a query-relevance-guided denoising strategy. By actively guiding the denoising trajectory, SPREAD ensures the generation remains anchored to the query's semantics and effectively suppresses drift. Experimental results demonstrate that SPREAD significantly enhances the precision and effectively mitigates RSD of generated answers within the RAG framework.