FORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
作者: Zhihan Yang, Jiaqi Wei, Xiang Zhang, Haoyu Dong, Yiwen Wang, Xiaoke Guo, Pengkun Zhang, Yiwei Xu, Chenyu You
分类: cs.LG
发布日期: 2026-01-16
备注: 23 pages
💡 一句话要点
FORESTLLM:利用大语言模型提升随机森林在少样本表格数据学习中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 少样本学习 表格数据 大语言模型 决策森林 语义分割
📋 核心要点
- 传统树模型在少样本表格数据学习中,因统计纯度指标不稳定易过拟合而失效。
- FORESTLLM结合决策森林结构偏置与LLM语义推理,训练阶段利用LLM指导森林构建。
- FORESTLLM在少样本分类和回归任务上取得了state-of-the-art的性能。
📝 摘要(中文)
在金融、医疗保健和科学发现等领域,表格数据的高风险决策至关重要。然而,在标签数据稀缺的少样本设置中,如何有效地从表格数据中学习仍然是一个根本性的挑战。传统的基于树的方法在这种情况下常常失效,因为它们依赖于统计纯度指标,这些指标在有限的监督下变得不稳定且容易过拟合。同时,直接应用大型语言模型(LLM)通常忽略了表格数据固有的结构,导致次优的性能。为了克服这些限制,我们提出了FORESTLLM,这是一个新颖的框架,它将决策森林的结构归纳偏置与LLM的语义推理能力结合起来。关键的是,FORESTLLM仅在训练期间利用LLM,将其视为离线模型设计器,将丰富的上下文知识编码到轻量级、可解释的森林模型中,从而消除了测试时对LLM推理的需求。我们的方法是双重的。首先,我们引入了一种语义分割标准,其中LLM基于其在标记和未标记数据上的连贯性来评估候选分区,从而能够在少样本监督下归纳出更鲁棒和更具泛化性的树结构。其次,我们提出了一种用于叶节点稳定的一次性上下文推理机制,其中LLM将决策路径及其支持示例提炼成简洁、确定性的预测,用语义信息输出替换嘈杂的经验估计。在各种少样本分类和回归基准测试中,FORESTLLM实现了最先进的性能。
🔬 方法详解
问题定义:论文旨在解决少样本表格数据学习问题。现有方法,如传统树模型,在数据量少时容易过拟合,而直接应用LLM则忽略了表格数据的结构信息,导致性能不佳。
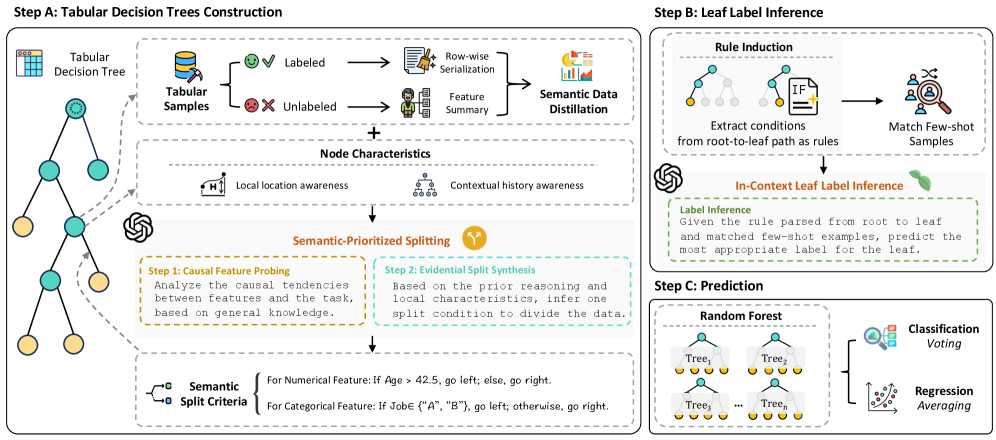
核心思路:核心思想是将LLM作为离线模型设计器,利用其强大的语义理解能力来指导决策森林的构建,从而在少样本情况下也能学习到鲁棒且泛化性强的模型。训练完成后,LLM不再参与推理,保证了效率。
技术框架:FORESTLLM框架主要包含两个阶段:1) 语义分割标准:利用LLM评估候选分割的连贯性,从而选择更优的分割点,构建更合理的树结构。2) 叶节点稳定:利用LLM将决策路径和支持样本提炼成简洁的预测,替代了传统的经验估计。
关键创新:关键创新在于利用LLM的语义理解能力来指导决策树的构建过程,而非直接使用LLM进行预测。这种方法结合了LLM的知识和决策树的结构化优势,同时避免了LLM在推理阶段的计算开销。
关键设计:语义分割标准的设计是关键。LLM被用于评估候选分割的质量,评估标准基于分割后数据的连贯性,这需要设计合适的prompt和评估指标。叶节点稳定阶段,需要设计有效的prompt,让LLM能够从决策路径和支持样本中提取出关键信息,并生成准确的预测。
🖼️ 关键图片
📊 实验亮点
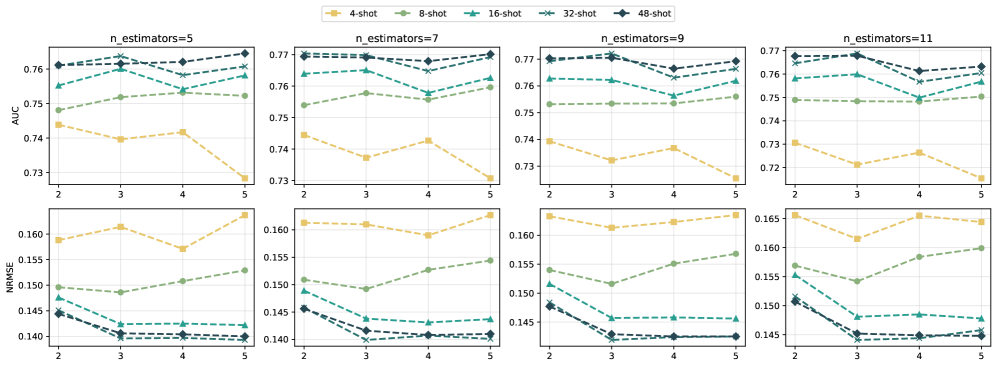
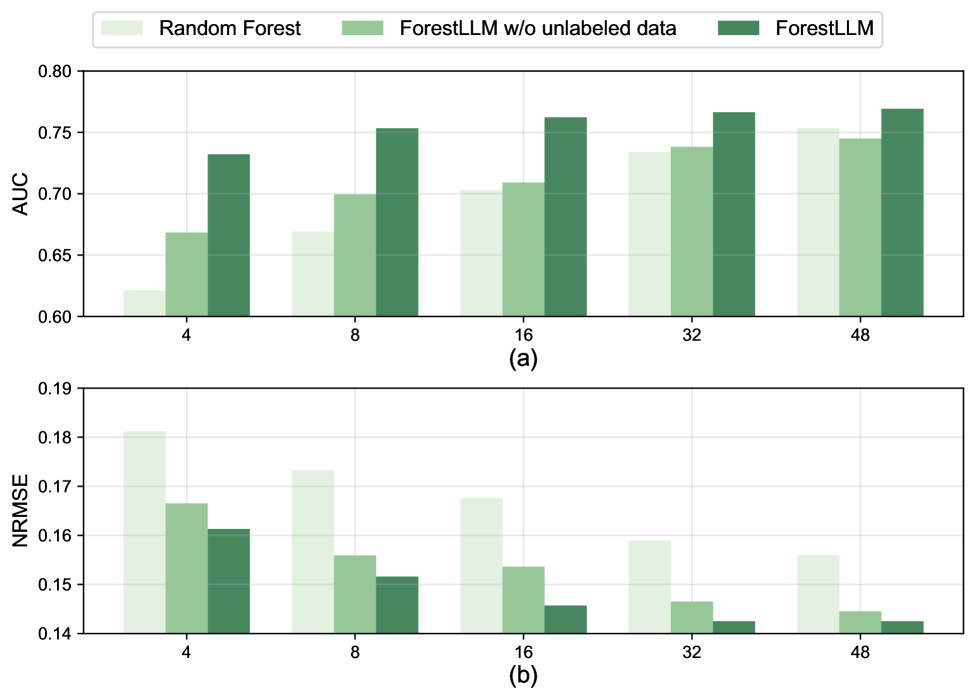
FORESTLLM在多个少样本分类和回归基准测试中取得了state-of-the-art的性能。具体性能数据未知,但论文强调了其在各种数据集上的显著提升,证明了该方法在少样本表格数据学习中的有效性。
🎯 应用场景
FORESTLLM在金融风控、医疗诊断、药物发现等领域具有广泛的应用前景。在这些领域,高质量的标注数据往往难以获取,而模型需要做出高风险的决策。FORESTLLM能够在少量数据下学习到可靠的模型,降低了数据标注成本,并提升了决策的准确性,具有重要的实际价值。
📄 摘要(原文)
Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.