Scalable Music Cover Retrieval Using Lyrics-Aligned Audio Embeddings
作者: Joanne Affolter, Benjamin Martin, Elena V. Epure, Gabriel Meseguer-Brocal, Frédéric Kaplan
分类: cs.SD, cs.IR, cs.LG
发布日期: 2026-01-16
备注: Published at ECIR 2026 (European Conference of Information Retrieval)
💡 一句话要点
提出LIVI:利用歌词对齐音频嵌入实现可扩展的音乐翻唱检索
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐翻唱检索 版本识别 歌词对齐 音频嵌入 语音转录
📋 核心要点
- 现有音乐翻唱检索方法依赖复杂音频处理,计算成本高昂,且对不同版本间的音乐属性变化鲁棒性不足。
- LIVI利用歌词作为跨版本的不变特征,通过歌词对齐的音频嵌入,在训练时借助先进的转录和文本嵌入模型。
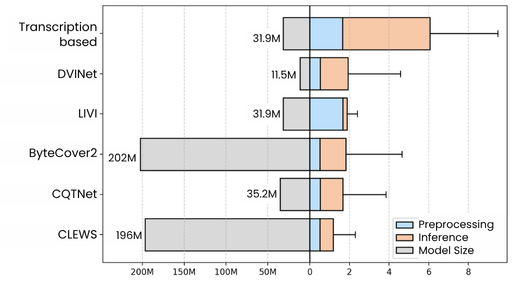
- LIVI在推理阶段去除转录步骤,显著降低计算复杂度,同时达到或超过基于谐波特征的检索精度。
📝 摘要(中文)
音乐翻唱检索,又称版本识别,旨在识别同一音乐作品的不同演绎版本,对于目录管理、版权执法和音乐检索至关重要。现有方法主要集中于谐波和旋律特征,采用日益复杂的音频处理流程,以对音乐属性保持不变性,而这些属性在不同翻唱版本中差异很大。虽然有效,但这些方法需要大量的训练时间和计算资源。相比之下,歌词构成了不同翻唱版本之间的强不变性,但其使用受到从复音音频中准确有效地提取歌词的难度的限制。早期方法依赖于限制下游性能的简单框架,而最近的系统提供了更强的结果,但需要集成在复杂的多模态架构中的大型模型。我们介绍LIVI(Lyrics-Informed Version Identification),一种旨在平衡检索准确性和计算效率的方法。首先,LIVI在训练期间利用来自最先进的转录和文本嵌入模型的监督,以实现与基于谐波的系统相当或优于它们的检索准确性。其次,LIVI通过在推理时移除转录步骤,保持轻量级和高效性,挑战了复杂管道的主导地位。
🔬 方法详解
问题定义:音乐翻唱检索旨在识别同一首歌曲的不同演绎版本。现有方法主要依赖音频特征,但计算成本高,且需要复杂的处理流程来保证对不同版本间音乐属性变化的鲁棒性。歌词虽然是更稳定的特征,但从音频中准确提取歌词非常困难。
核心思路:LIVI的核心思路是利用歌词作为桥梁,学习歌词对齐的音频嵌入。通过在训练阶段引入歌词信息,模型可以学习到对不同版本具有不变性的音频表示,从而提高翻唱检索的准确性。同时,在推理阶段去除歌词转录步骤,保证了计算效率。
技术框架:LIVI的整体框架包含训练和推理两个阶段。在训练阶段,模型同时接收音频和歌词作为输入,利用先进的语音转录模型和文本嵌入模型提供监督信号,学习音频嵌入。在推理阶段,模型仅接收音频输入,直接输出音频嵌入,用于翻唱检索。
关键创新:LIVI的关键创新在于利用歌词信息指导音频嵌入的学习,从而获得对不同版本更鲁棒的音频表示。与传统方法相比,LIVI避免了复杂的音频特征工程和后处理,简化了流程,提高了效率。同时,在推理阶段去除转录步骤,进一步降低了计算复杂度。
关键设计:LIVI使用了预训练的语音转录模型(如Whisper)和文本嵌入模型(如Sentence-BERT)来提取歌词信息和文本表示。损失函数的设计旨在使音频嵌入与对应的歌词嵌入尽可能接近,从而实现歌词对齐。具体的网络结构和参数设置未知,需要参考论文细节。
🖼️ 关键图片


📊 实验亮点
LIVI在音乐翻唱检索任务上取得了与基于谐波特征的系统相当或更优的性能,同时显著降低了计算复杂度。具体性能数据未知,但论文强调LIVI在推理阶段无需转录步骤,大大提高了效率,挑战了现有复杂流程的主导地位。
🎯 应用场景
LIVI可应用于音乐版权管理、音乐推荐系统和音乐信息检索等领域。例如,可以用于识别未经授权的翻唱版本,保护音乐版权;也可以用于在音乐推荐系统中推荐同一歌曲的不同版本,丰富用户体验;还可以用于构建更强大的音乐搜索引擎,提高检索准确率。
📄 摘要(原文)
Music Cover Retrieval, also known as Version Identification, aims to recognize distinct renditions of the same underlying musical work, a task central to catalog management, copyright enforcement, and music retrieval. State-of-the-art approaches have largely focused on harmonic and melodic features, employing increasingly complex audio pipelines designed to be invariant to musical attributes that often vary widely across covers. While effective, these methods demand substantial training time and computational resources. By contrast, lyrics constitute a strong invariant across covers, though their use has been limited by the difficulty of extracting them accurately and efficiently from polyphonic audio. Early methods relied on simple frameworks that limited downstream performance, while more recent systems deliver stronger results but require large models integrated within complex multimodal architectures. We introduce LIVI (Lyrics-Informed Version Identification), an approach that seeks to balance retrieval accuracy with computational efficiency. First, LIVI leverages supervision from state-of-the-art transcription and text embedding models during training to achieve retrieval accuracy on par with--or superior to--harmonic-based systems. Second, LIVI remains lightweight and efficient by removing the transcription step at inference, challenging the dominance of complexity-heavy pipelines.