Knowledge is Not Enough: Injecting RL Skills for Continual Adaptation
作者: Pingzhi Tang, Yiding Wang, Muhan Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-16
💡 一句话要点
提出PaST框架,通过注入强化学习技能向量实现LLM的持续知识适应
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 持续学习 知识适应 强化学习 技能转移 大型语言模型 参数化技能 工具使用
📋 核心要点
- LLM存在知识截止问题,无法直接吸收新知识,而SFT虽然能更新知识,但难以提升模型利用新知识的能力。
- PaST框架通过提取领域无关的技能向量,并将其线性注入到经过SFT的目标模型中,从而实现知识操作技能的迁移。
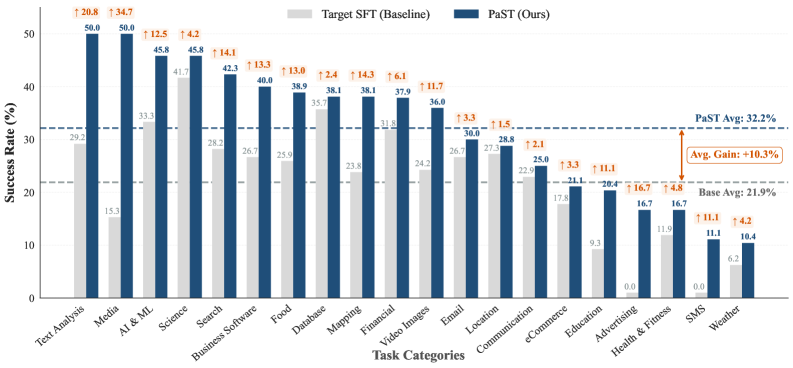
- 实验表明,PaST在知识整合问答和代理工具使用任务上均取得了显著提升,验证了其有效性和跨域可迁移性。
📝 摘要(中文)
大型语言模型(LLM)面临“知识截止”的挑战,其冻结的参数记忆阻止了新信息的直接内化。监督微调(SFT)通常用于更新模型知识,但它通常更新事实内容,而不能可靠地提高模型使用新信息进行问答或决策的能力。强化学习(RL)对于获得推理技能至关重要;然而,其高计算成本使其不适合高效的在线适应。我们通过实验观察到,SFT和RL引起的参数更新几乎是正交的。基于此,我们提出了参数化技能转移(PaST)框架,该框架支持模块化技能转移,以实现高效和有效的知识适应。通过从源域提取领域无关的技能向量,我们可以在目标模型经过对新数据的轻量级SFT后,线性地将知识操作技能注入到目标模型中。在知识整合问答(SQuAD, LooGLE)和代理工具使用基准(ToolBench)上的实验证明了我们方法的有效性。在SQuAD上,PaST优于最先进的自编辑SFT基线高达9.9分。PaST进一步扩展到LooGLE上的长上下文问答,绝对精度提高了8.0分,并在ToolBench上将零样本成功率平均提高了+10.3分,在所有工具类别中都取得了持续的收益,表明了技能向量的强大可扩展性和跨域可转移性。
🔬 方法详解
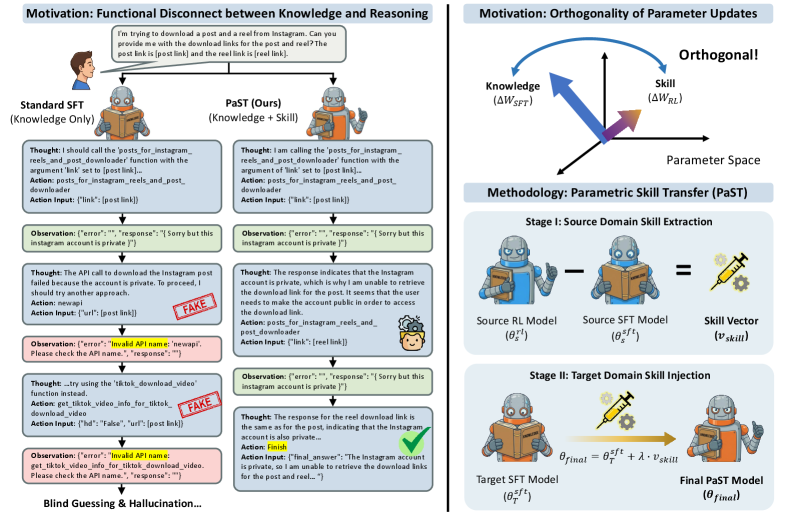
问题定义:大型语言模型(LLM)由于其固定的参数化知识,无法直接吸收新的信息,面临“知识截止”问题。虽然监督微调(SFT)可以更新模型知识,但它往往只关注事实内容的更新,而忽略了模型利用这些新知识进行推理和决策的能力。现有方法难以在更新知识的同时,有效提升模型的使用技能。
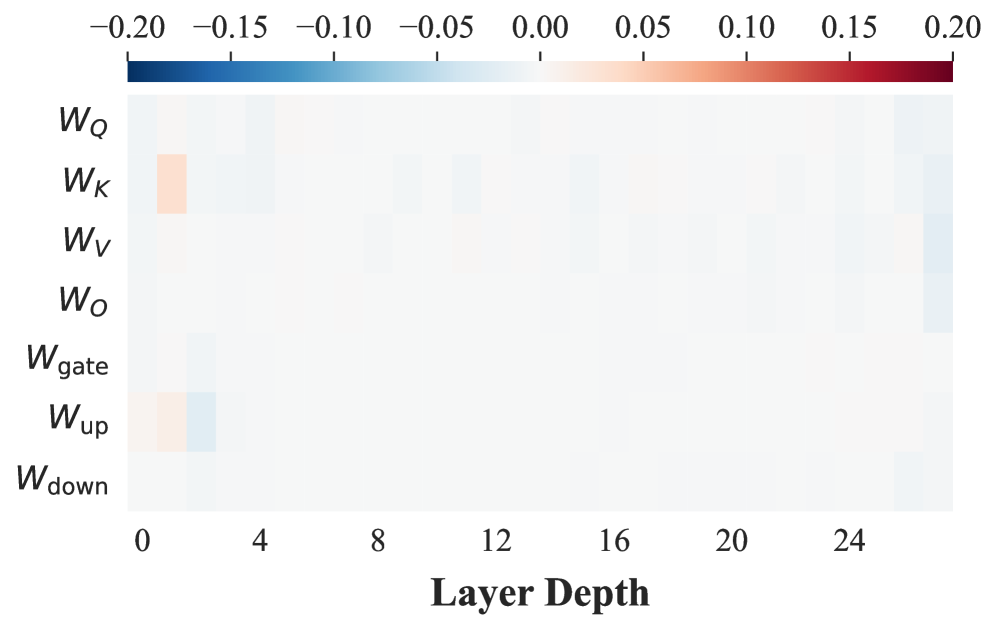
核心思路:论文的核心思路是利用强化学习(RL)来学习知识操作技能,并通过参数化技能转移(PaST)框架,将这些技能从源域迁移到目标域。作者观察到SFT和RL引起的参数更新是近乎正交的,这为技能的独立转移提供了理论基础。通过提取领域无关的技能向量,可以将其线性注入到经过SFT的目标模型中,从而赋予模型利用新知识的能力。
技术框架:PaST框架主要包含以下几个阶段:1) 技能学习阶段:使用RL在源域上训练模型,学习知识操作技能。2) 技能提取阶段:从训练好的RL模型中提取领域无关的技能向量。3) 知识更新阶段:在目标域上使用SFT对模型进行微调,使其掌握新的知识。4) 技能注入阶段:将提取的技能向量线性注入到经过SFT的目标模型中,从而赋予模型利用新知识的能力。
关键创新:PaST框架的关键创新在于:1) 提出了参数化技能转移的概念,将RL学习到的技能以参数化的形式进行迁移。2) 观察到SFT和RL引起的参数更新是近乎正交的,为技能的独立转移提供了理论依据。3) 提出了领域无关的技能向量,使其能够跨领域进行迁移。
关键设计:PaST框架的关键设计包括:1) 使用RL训练模型时,需要设计合适的奖励函数,以引导模型学习知识操作技能。2) 技能向量的提取方法需要保证其领域无关性,例如可以使用某种降维或解耦技术。3) 技能注入的方式可以选择线性注入,也可以尝试其他非线性方式。4) SFT的学习率和训练轮数需要根据具体任务进行调整。
🖼️ 关键图片
📊 实验亮点
PaST在SQuAD上优于最先进的自编辑SFT基线高达9.9分,在LooGLE上绝对精度提高了8.0分,在ToolBench上将零样本成功率平均提高了+10.3分。这些实验结果表明,PaST在知识整合问答和代理工具使用任务上均取得了显著提升,验证了其有效性和跨域可迁移性。尤其是在ToolBench上的提升,证明了PaST能够有效地提升LLM的工具使用能力。
🎯 应用场景
该研究成果可应用于各种需要持续学习和适应新知识的场景,例如智能客服、知识图谱问答、智能助手等。通过PaST框架,可以快速地将新知识融入到LLM中,并提升其利用新知识进行推理和决策的能力,从而提高LLM的实用性和智能化水平。未来,该方法还可以扩展到其他模态的数据,例如图像、语音等,实现多模态知识的持续学习。
📄 摘要(原文)
Large Language Models (LLMs) face the "knowledge cutoff" challenge, where their frozen parametric memory prevents direct internalization of new information. While Supervised Fine-Tuning (SFT) is commonly used to update model knowledge, it often updates factual content without reliably improving the model's ability to use the newly incorporated information for question answering or decision-making. Reinforcement Learning (RL) is essential for acquiring reasoning skills; however, its high computational cost makes it impractical for efficient online adaptation. We empirically observe that the parameter updates induced by SFT and RL are nearly orthogonal. Based on this observation, we propose Parametric Skill Transfer (PaST), a framework that supports modular skill transfer for efficient and effective knowledge adaptation. By extracting a domain-agnostic Skill Vector from a source domain, we can linearly inject knowledge manipulation skills into a target model after it has undergone lightweight SFT on new data. Experiments on knowledge-incorporation QA (SQuAD, LooGLE) and agentic tool-use benchmarks (ToolBench) demonstrate the effectiveness of our method. On SQuAD, PaST outperforms the state-of-the-art self-editing SFT baseline by up to 9.9 points. PaST further scales to long-context QA on LooGLE with an 8.0-point absolute accuracy gain, and improves zero-shot ToolBench success rates by +10.3 points on average with consistent gains across tool categories, indicating strong scalability and cross-domain transferability of the Skill Vector.