SDFLoRA: Selective Dual-Module LoRA for Federated Fine-tuning with Heterogeneous Clients
作者: Zhikang Shen, Jianrong Lu, Haiyuan Wan, Jianhai Chen
分类: cs.LG, cs.AI
发布日期: 2026-01-16
💡 一句话要点
SDFLoRA:用于异构客户端联邦微调的选择性双模块LoRA
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 参数高效微调 LoRA 异构客户端 差分隐私 模型个性化 全局模块 本地模块
📋 核心要点
- 现有联邦学习方法在处理客户端LoRA秩异构性时,存在聚合偏差和个性化不足的问题。
- SDFLoRA将客户端LoRA适配器分解为全局和本地模块,选择性聚合全局模块,保护本地模块隐私。
- 实验表明,SDFLoRA在GLUE基准测试中优于现有联邦LoRA方法,实现了更好的效用-隐私平衡。
📝 摘要(中文)
针对大型语言模型(LLM)的联邦学习(FL)作为一种在分布式数据上实现隐私保护适应的方法,受到了越来越多的关注。诸如LoRA之类的参数高效方法被广泛采用,以降低通信和内存成本。尽管取得了这些进展,但实际的FL部署通常表现出秩异构性,因为不同的客户端可能使用不同的低秩配置。这使得直接聚合LoRA更新产生偏差且不稳定。现有的解决方案通常强制统一秩或将异构更新对齐到共享子空间中,这过度约束了客户端特定的语义,限制了个性化,并且在差分隐私噪声下对本地客户端信息提供较弱的保护。为了解决这个问题,我们提出了选择性双模块联邦LoRA(SDFLoRA),它将每个客户端适配器分解为一个捕获可转移知识的全局模块和一个保留客户端特定适应的本地模块。全局模块在客户端之间进行选择性对齐和聚合,而本地模块保持私有。这种设计能够在秩异构性下实现稳健的学习,并通过仅将差分隐私噪声注入到全局模块中来支持隐私感知优化。在GLUE基准上的实验表明,SDFLoRA优于具有代表性的联邦LoRA基线,并实现了更好的效用-隐私权衡。
🔬 方法详解
问题定义:论文旨在解决联邦学习中,由于客户端之间LoRA秩配置不同导致的聚合偏差和个性化不足的问题。现有方法要么强制统一秩,要么将更新对齐到共享子空间,限制了个性化,并且在差分隐私保护下,对本地客户端信息的保护较弱。
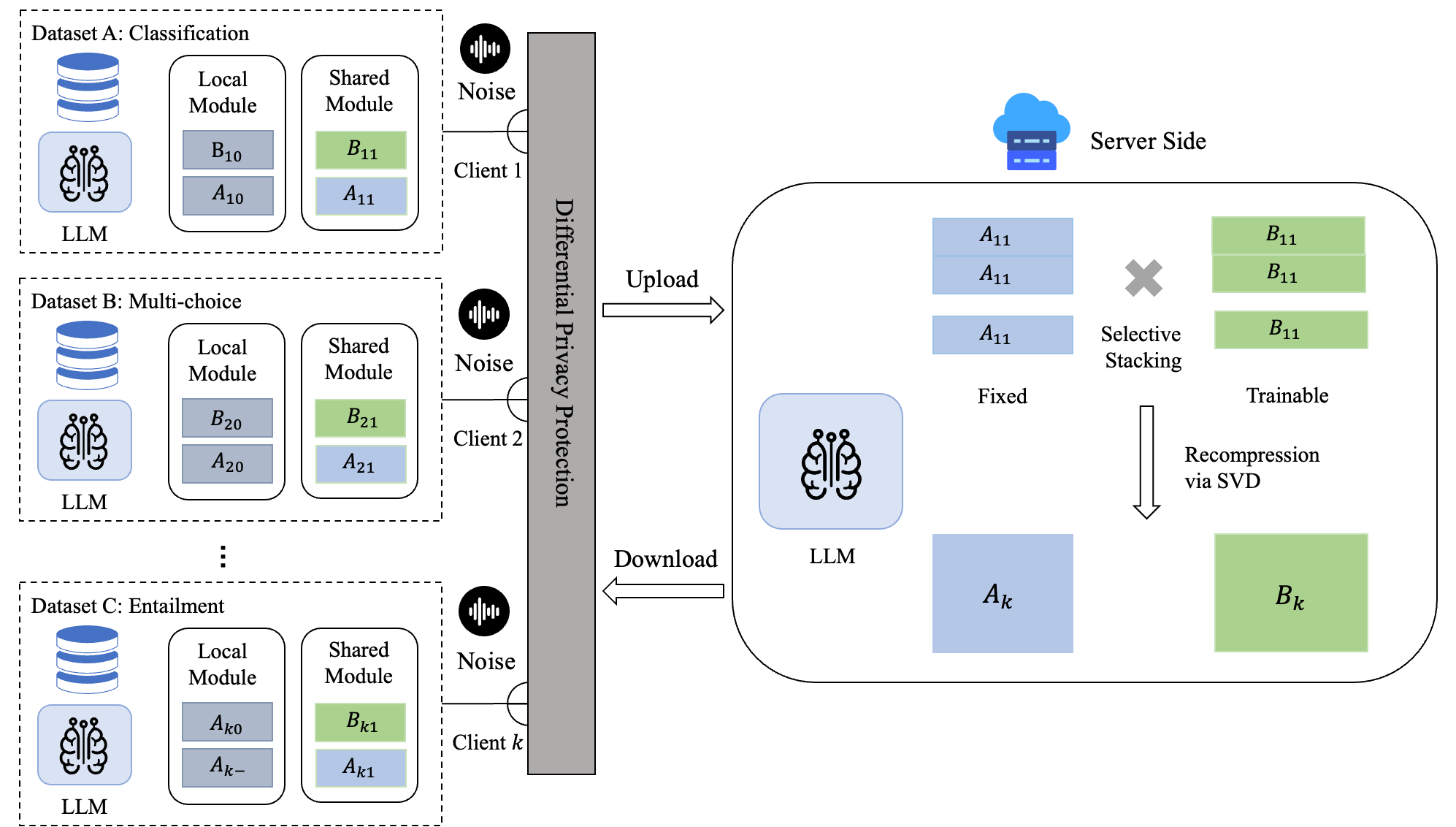
核心思路:论文的核心思路是将每个客户端的LoRA适配器分解为两个模块:一个全局模块,用于捕获可转移的知识;一个本地模块,用于保留客户端特定的适应。全局模块在客户端之间选择性地对齐和聚合,而本地模块保持私有,从而在实现知识共享的同时,保护了客户端的个性化信息。
技术框架:SDFLoRA的整体框架包括以下几个步骤:1) 每个客户端训练自己的LoRA适配器。2) 将每个LoRA适配器分解为全局模块和本地模块。3) 选择性地对齐和聚合全局模块。4) 本地模块保持私有,不参与聚合。5) 使用聚合后的全局模块和本地模块进行推理或微调。
关键创新:SDFLoRA的关键创新在于双模块分解和选择性聚合。通过将LoRA适配器分解为全局和本地模块,SDFLoRA能够更好地平衡知识共享和个性化。选择性聚合允许只聚合全局模块,从而避免了由于秩异构性导致的聚合偏差。
关键设计:SDFLoRA的关键设计包括:1) 如何将LoRA适配器分解为全局和本地模块(具体分解方法未知)。2) 如何选择性地对齐和聚合全局模块(具体对齐和聚合策略未知)。3) 如何在全局模块上注入差分隐私噪声,以保护客户端隐私(具体噪声添加方法和参数设置未知)。
🖼️ 关键图片
📊 实验亮点
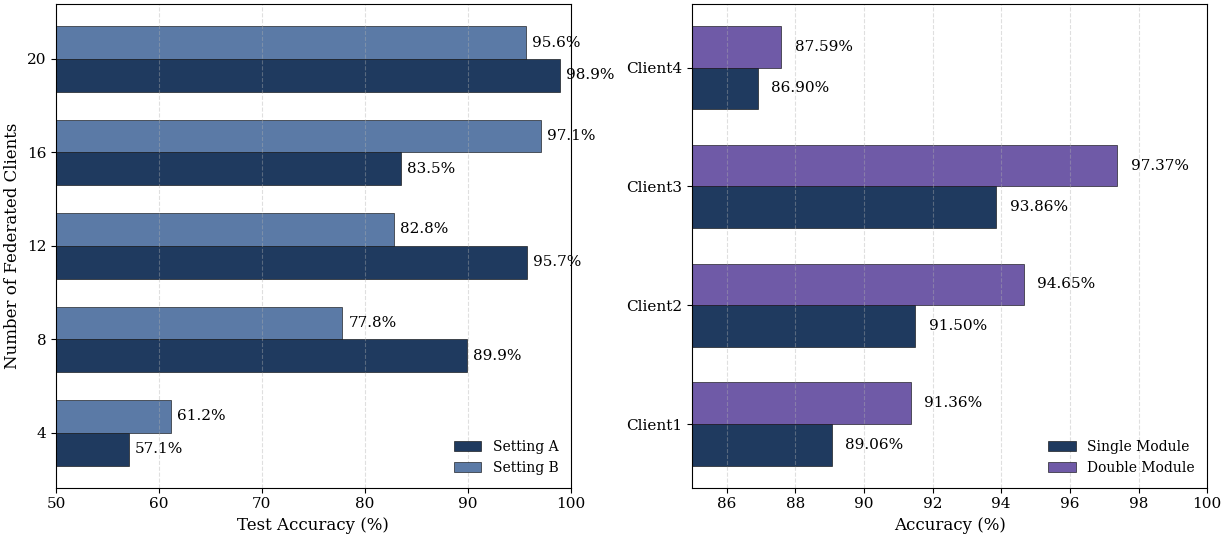
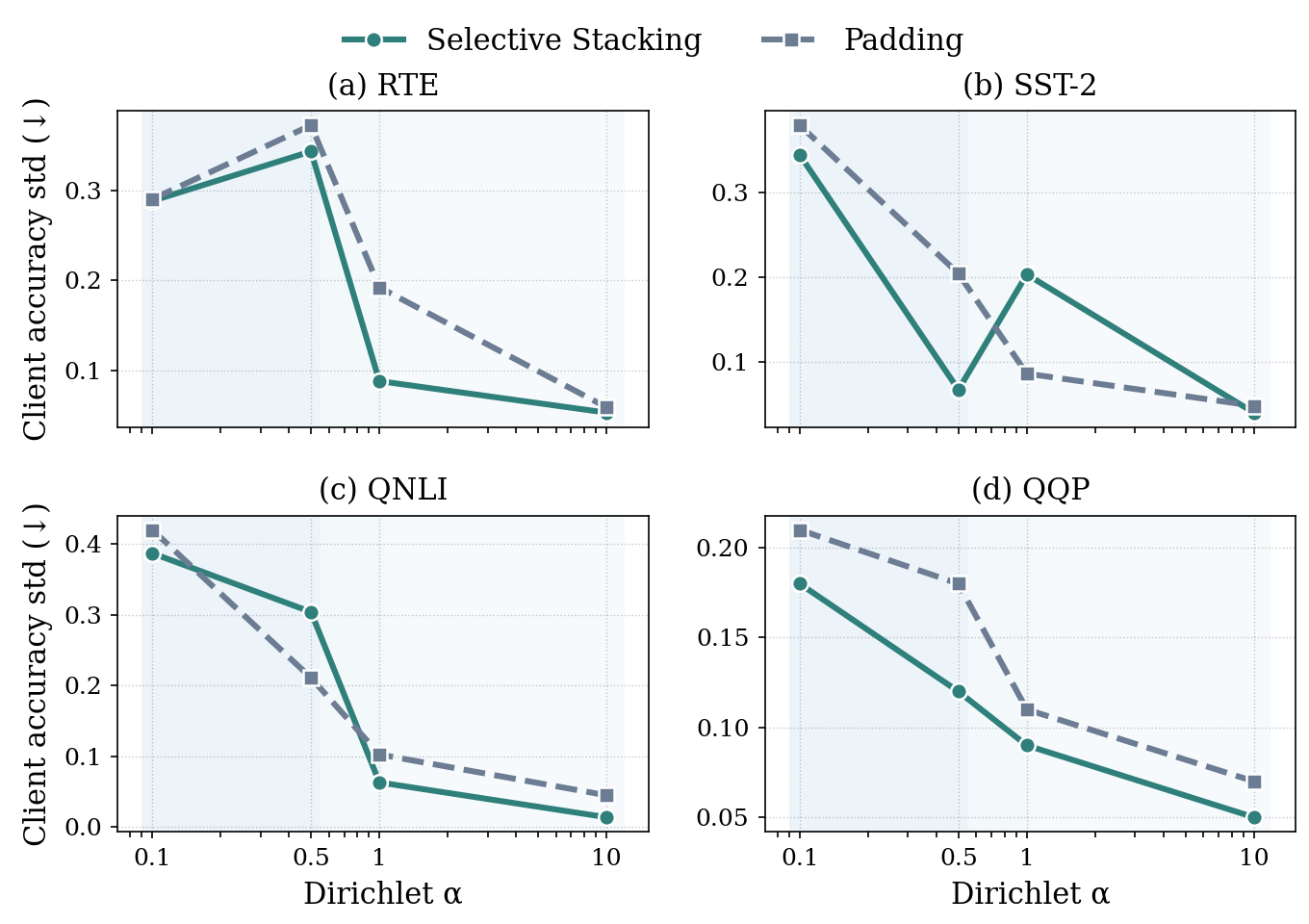
SDFLoRA在GLUE基准测试中取得了显著的性能提升。具体而言,SDFLoRA优于现有的联邦LoRA基线方法,并且在效用-隐私权衡方面表现更好。实验结果表明,SDFLoRA能够在秩异构性下实现更稳健的学习,并且能够更好地保护客户端隐私。
🎯 应用场景
SDFLoRA适用于各种需要联邦学习的场景,尤其是在客户端数据异构性较高的情况下。例如,在医疗领域,不同医院的数据分布可能存在差异,SDFLoRA可以用于训练个性化的医疗诊断模型,同时保护患者隐私。在金融领域,不同用户的交易行为可能存在差异,SDFLoRA可以用于训练个性化的风险评估模型,同时保护用户隐私。
📄 摘要(原文)
Federated learning (FL) for large language models (LLMs) has attracted increasing attention as a way to enable privacy-preserving adaptation over distributed data. Parameter-efficient methods such as LoRA are widely adopted to reduce communication and memory costs. Despite these advances, practical FL deployments often exhibit rank heterogeneity, since different clients may use different low-rank configurations. This makes direct aggregation of LoRA updates biased and unstable. Existing solutions typically enforce unified ranks or align heterogeneous updates into a shared subspace, which over-constrains client-specific semantics, limits personalization, and provides weak protection of local client information under differential privacy noise. To address this issue, we propose Selective Dual-module Federated LoRA (SDFLoRA), which decomposes each client adapter into a global module that captures transferable knowledge and a local module that preserves client-specific adaptations. The global module is selectively aligned and aggregated across clients, while local modules remain private. This design enables robust learning under rank heterogeneity and supports privacy-aware optimization by injecting differential privacy noise exclusively into the global module. Experiments on GLUE benchmarks demonstrate that SDFLoRA outperforms representative federated LoRA baselines and achieves a better utility-privacy trade-off.