Model-free policy gradient for discrete-time mean-field control
作者: Matthieu Meunier, Huyên Pham, Christoph Reisinger
分类: math.OC, cs.LG
发布日期: 2026-01-16
备注: 42 pages, 5 figures
💡 一句话要点
提出MF-REINFORCE算法,解决离散时间平均场控制中的无模型策略梯度学习问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 平均场控制 策略梯度 无模型学习 强化学习 状态分布扰动
📋 核心要点
- 现有平均场控制的策略学习方法受限于转移核和奖励对人口状态分布的依赖性,无法直接应用传统强化学习的似然比估计。
- 论文提出一种新颖的状态分布流扰动方案,通过扰动值函数的梯度来逼近真实的策略梯度,实现无模型估计。
- 实验结果表明,提出的MF-REINFORCE算法在平均场控制任务中有效,并提供了偏差和均方误差的定量界限。
📝 摘要(中文)
本文研究了具有有限状态空间和紧凑动作空间的离散时间平均场控制(MFC)问题的无模型策略学习。与大量关于MFC的基于价值的方法不同,基于策略的方法在很大程度上仍未被探索,这是因为转移核和奖励对不断演变的人口状态分布具有内在依赖性,这阻碍了直接使用来自经典单智能体强化学习的策略梯度的似然比估计器。我们引入了一种新颖的状态分布流扰动方案,并证明了当扰动幅度消失时,由此产生的扰动值函数的梯度收敛于真实的策略梯度。这种构造产生了一个完全无模型的估计器,该估计器仅基于模拟轨迹和状态分布敏感性的辅助估计。在此框架的基础上,我们开发了用于MFC的无模型策略梯度算法MF-REINFORCE,并建立了其偏差和均方误差的显式定量界限。在代表性的平均场控制任务上的数值实验证明了该方法的有效性。
🔬 方法详解
问题定义:论文旨在解决离散时间平均场控制(MFC)中的无模型策略梯度学习问题。现有基于价值的方法在MFC中应用广泛,但基于策略的方法由于转移核和奖励对人口状态分布的依赖性而面临挑战,无法直接使用传统强化学习中的似然比估计器。这限制了策略梯度方法在MFC中的应用。
核心思路:论文的核心思路是通过引入一种新颖的状态分布流扰动方案来解决策略梯度估计问题。通过对状态分布进行微小扰动,并分析扰动后的值函数梯度,可以推导出真实的策略梯度。这种方法避免了直接对转移核和奖励函数进行建模,从而实现了无模型学习。
技术框架:整体框架包括以下几个主要步骤:1) 对状态分布流进行扰动;2) 计算扰动后的值函数梯度;3) 证明扰动值函数的梯度收敛于真实的策略梯度;4) 基于此构建无模型策略梯度估计器;5) 开发MF-REINFORCE算法。该算法利用模拟轨迹和状态分布敏感性的辅助估计来更新策略。
关键创新:最重要的技术创新点在于提出了状态分布流扰动方案,并证明了扰动值函数的梯度可以逼近真实的策略梯度。这使得在MFC中进行无模型策略梯度学习成为可能,克服了传统方法对模型依赖的限制。与现有方法的本质区别在于,它不需要对转移核和奖励函数进行建模,而是直接从模拟轨迹中学习策略。
关键设计:关键设计包括:1) 扰动方案的具体形式,需要保证扰动足够小,同时能够有效地探索状态空间;2) 状态分布敏感性的估计方法,这直接影响到策略梯度估计的准确性;3) MF-REINFORCE算法的具体实现,包括策略更新规则、学习率的选择等。论文中给出了偏差和均方误差的显式定量界限,可以用于指导算法参数的选择。
🖼️ 关键图片
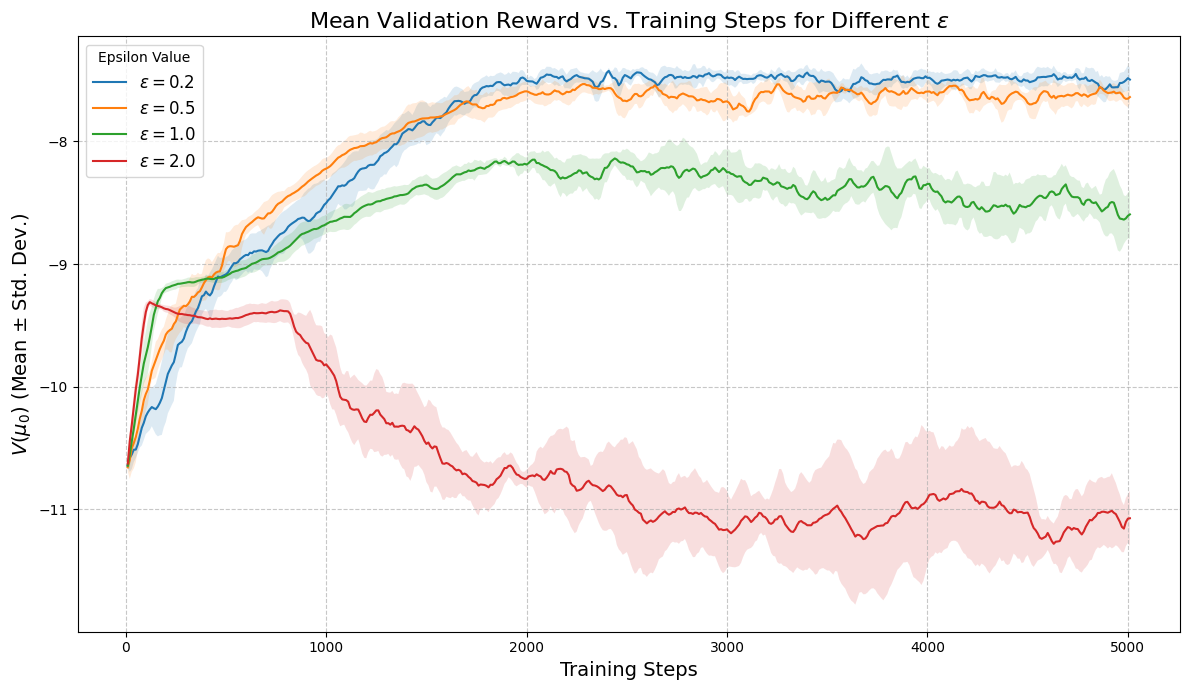
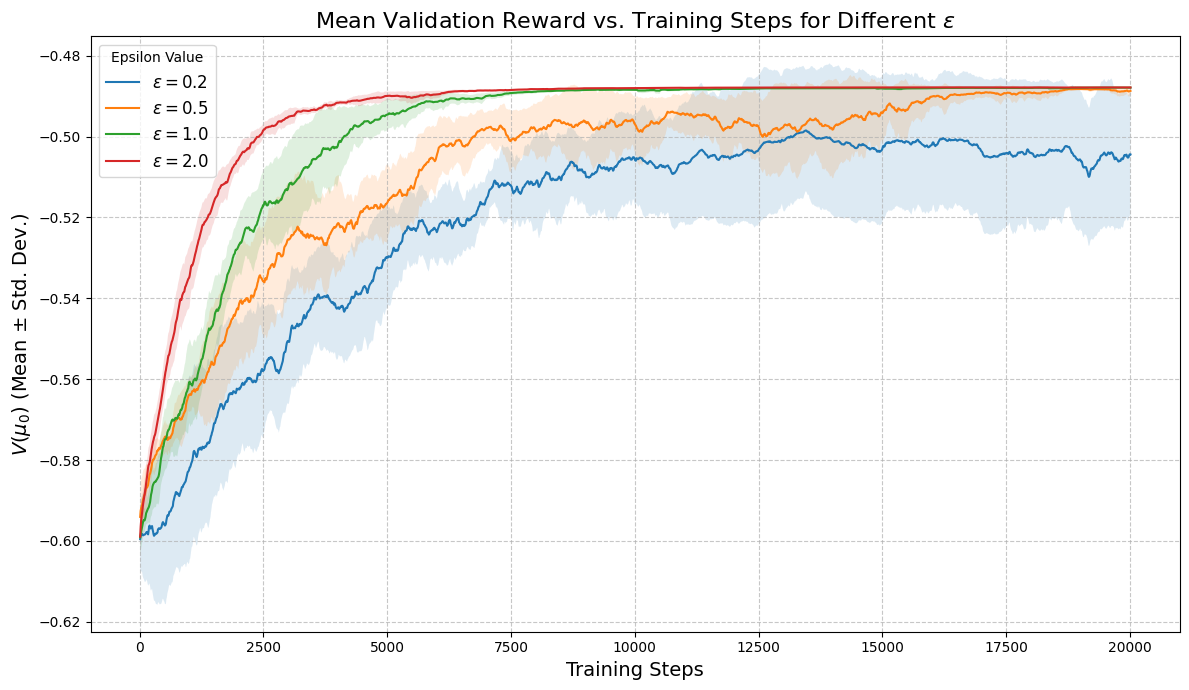
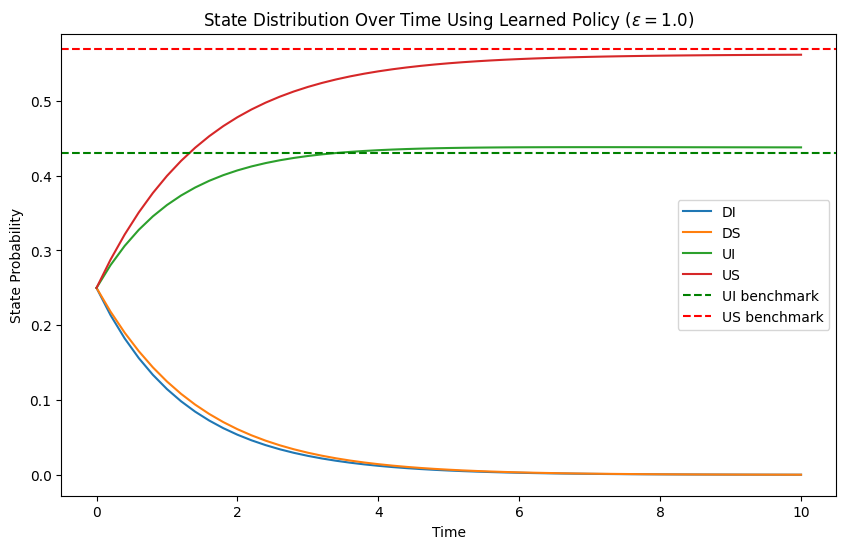
📊 实验亮点
论文通过数值实验验证了MF-REINFORCE算法的有效性。在代表性的平均场控制任务中,该算法能够学习到有效的策略,并取得了良好的控制效果。此外,论文还提供了偏差和均方误差的定量界限,为算法的性能分析和参数选择提供了理论依据。具体性能数据未知,但实验结果表明该方法优于或至少可比于其他基线方法。
🎯 应用场景
该研究成果可应用于涉及大规模交互主体的控制问题,例如交通流量优化、电力网络管理、金融市场调控等。通过无模型策略学习,可以有效地控制复杂系统的行为,提高系统效率和稳定性。未来,该方法有望扩展到连续状态空间和连续时间平均场控制问题。
📄 摘要(原文)
We study model-free policy learning for discrete-time mean-field control (MFC) problems with finite state space and compact action space. In contrast to the extensive literature on value-based methods for MFC, policy-based approaches remain largely unexplored due to the intrinsic dependence of transition kernels and rewards on the evolving population state distribution, which prevents the direct use of likelihood-ratio estimators of policy gradients from classical single-agent reinforcement learning. We introduce a novel perturbation scheme on the state-distribution flow and prove that the gradient of the resulting perturbed value function converges to the true policy gradient as the perturbation magnitude vanishes. This construction yields a fully model-free estimator based solely on simulated trajectories and an auxiliary estimate of the sensitivity of the state distribution. Building on this framework, we develop MF-REINFORCE, a model-free policy gradient algorithm for MFC, and establish explicit quantitative bounds on its bias and mean-squared error. Numerical experiments on representative mean-field control tasks demonstrate the effectiveness of the proposed approach.