FAQ: Mitigating Quantization Error via Regenerating Calibration Data with Family-Aware Quantization
作者: Haiyang Xiao, Weiqing Li, Jinyue Guo, Guochao Jiang, Guohua Liu, Yuewei Zhang
分类: cs.LG, cs.AI
发布日期: 2026-01-16
💡 一句话要点
FAQ:通过家族感知量化再生校准数据,缓解量化误差
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后训练量化 大型语言模型 校准数据 知识迁移 模型压缩
📋 核心要点
- 现有后训练量化方法依赖有限校准数据,难以准确捕捉激活分布,导致量化参数偏差。
- FAQ框架利用同一家族更大LLM的知识,生成高保真校准样本,提升数据代表性。
- 实验表明,FAQ能显著降低量化带来的精度损失,在Qwen3-8B上最高降低28.5%。
📝 摘要(中文)
后训练量化(PTQ)为在资源受限设备上部署大型语言模型(LLM)提供了一种高效的数值压缩方案,但校准数据的代表性和通用性仍然是决定量化参数精度的核心瓶颈。传统的PTQ方法通常依赖于有限的样本,难以捕捉推理阶段的激活分布,导致量化参数出现偏差。为了解决这个问题,我们提出了 extbf{FAQ}(家族感知量化),这是一个校准数据再生框架,它利用来自同一家族的LLM的先验知识来生成高保真校准样本。具体来说,FAQ首先将原始校准样本输入到同一家族的更大的LLM中,使用高度一致的知识系统再生一系列高保真校准数据。随后,这些携带思维链推理并符合预期激活分布的数据,在专家指导下进行群体竞争,以选择最佳样本,然后重新归一化,以提高标准PTQ的有效性。在包括Qwen3-8B在内的多个模型系列上的实验表明,与使用原始校准数据的基线相比,FAQ将精度损失降低了高达28.5%,证明了其强大的潜力和贡献。
🔬 方法详解
问题定义:论文旨在解决后训练量化(PTQ)中,由于校准数据不足或不具代表性,导致量化参数偏差,进而影响量化模型精度的难题。现有PTQ方法通常使用少量样本进行校准,无法充分覆盖模型推理时的激活分布,尤其是在大型语言模型(LLM)上表现更为明显。
核心思路:论文的核心思路是利用同一家族中更大规模的LLM所拥有的更丰富的知识和推理能力,来生成更具代表性和高质量的校准数据。通过将原始校准数据输入到更大的LLM中,可以获得包含更复杂推理过程和更符合实际激活分布的新校准数据。
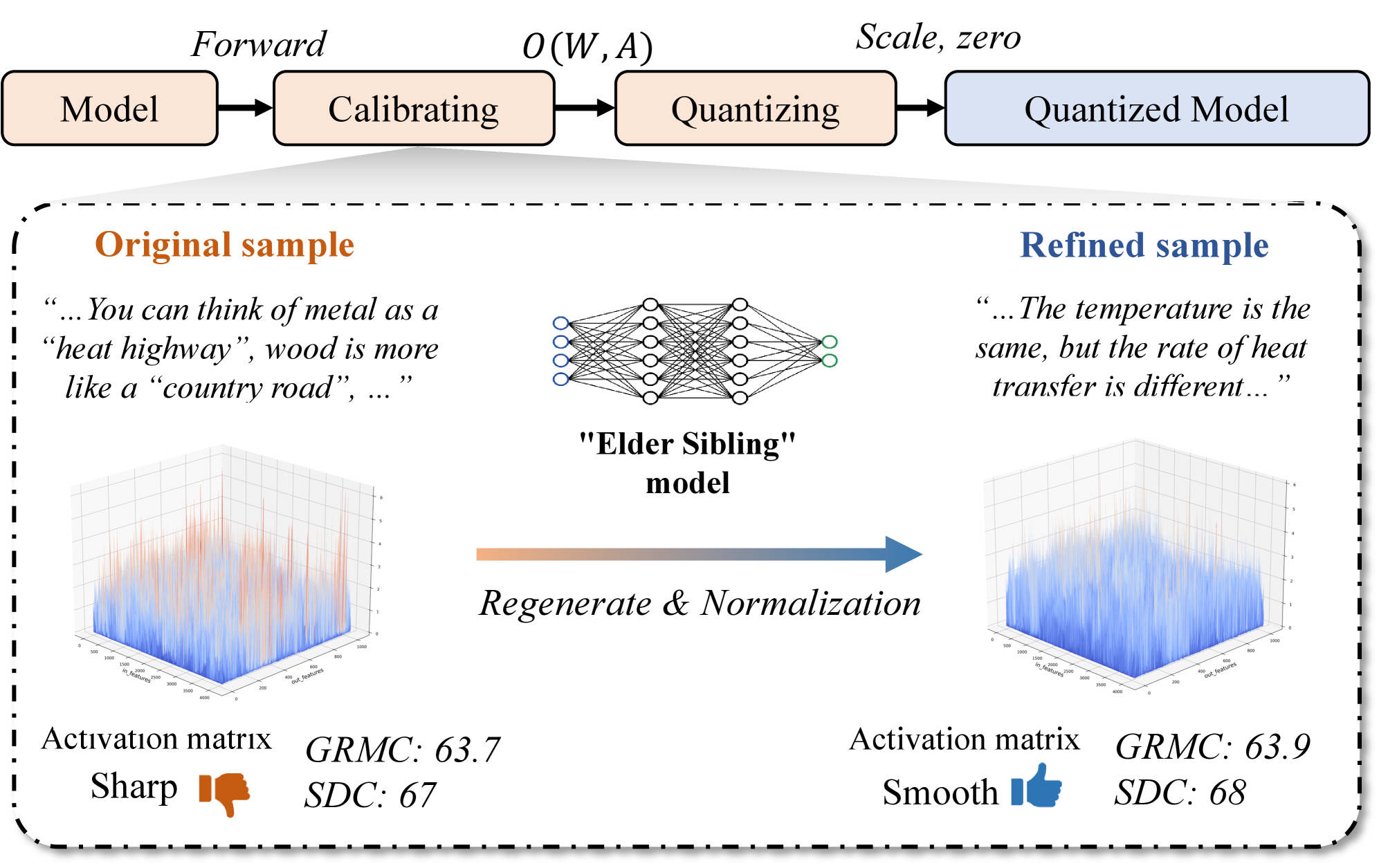
技术框架:FAQ框架主要包含以下几个阶段:1) 使用原始校准数据作为prompt,输入到同一家族的更大LLM中,生成新的校准数据;2) 对生成的数据进行专家指导下的群体竞争,选择最佳样本;3) 对选定的样本进行重新归一化,以增强其对标准PTQ的有效性。最终,使用这些再生后的校准数据进行PTQ。
关键创新:FAQ的关键创新在于利用了LLM家族内部的知识迁移能力,通过更大模型的推理来增强校准数据的质量。与传统PTQ方法直接使用原始数据或简单的数据增强方法不同,FAQ能够生成包含更丰富语义信息和更符合模型实际激活分布的校准数据。
关键设计:FAQ的关键设计包括:1) 选择合适的更大LLM,确保其与目标模型属于同一家族,具有相似的知识体系;2) 设计有效的群体竞争策略,筛选出最具代表性的校准样本;3) 采用合适的重新归一化方法,以优化校准数据的分布,提升PTQ效果。具体的参数设置和损失函数选择取决于具体的模型和数据集。
🖼️ 关键图片
📊 实验亮点
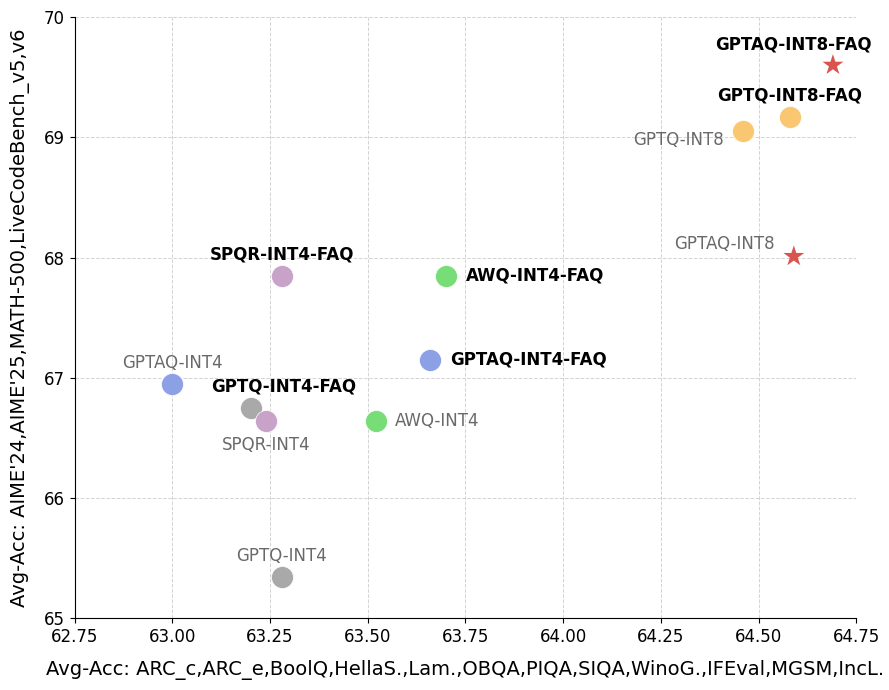
实验结果表明,FAQ在多个模型系列(包括Qwen3-8B)上均取得了显著的性能提升。与使用原始校准数据的基线方法相比,FAQ能够将精度损失降低高达28.5%。这表明FAQ能够有效缓解量化误差,提升量化模型的精度,具有很强的实用价值。
🎯 应用场景
该研究成果可广泛应用于大型语言模型在资源受限设备上的部署,例如移动设备、嵌入式系统等。通过降低量化带来的精度损失,FAQ能够提升量化模型的实用性,使其能够在计算资源有限的环境下提供高质量的服务。未来,该方法有望进一步推广到其他类型的深度学习模型,并与其他模型压缩技术相结合,实现更高效的模型部署。
📄 摘要(原文)
Although post-training quantization (PTQ) provides an efficient numerical compression scheme for deploying large language models (LLMs) on resource-constrained devices, the representativeness and universality of calibration data remain a core bottleneck in determining the accuracy of quantization parameters. Traditional PTQ methods typically rely on limited samples, making it difficult to capture the activation distribution during the inference phase, leading to biases in quantization parameters. To address this, we propose \textbf{FAQ} (Family-Aware Quantization), a calibration data regeneration framework that leverages prior knowledge from LLMs of the same family to generate high-fidelity calibration samples. Specifically, FAQ first inputs the original calibration samples into a larger LLM from the same family as the target model, regenerating a series of high-fidelity calibration data using a highly consistent knowledge system. Subsequently, this data, carrying Chain-of-Thought reasoning and conforming to the expected activation distribution, undergoes group competition under expert guidance to select the best samples, which are then re-normalized to enhance the effectiveness of standard PTQ. Experiments on multiple model series, including Qwen3-8B, show that FAQ reduces accuracy loss by up to 28.5\% compared to the baseline with original calibration data, demonstrating its powerful potential and contribution.