Optimized Algorithms for Text Clustering with LLM-Generated Constraints
作者: Chaoqi Jia, Weihong Wu, Longkun Guo, Zhigang Lu, Chao Chen, Kok-Leong Ong
分类: cs.LG
发布日期: 2026-01-16
备注: AAAI-26
💡 一句话要点
提出基于LLM生成约束的文本聚类优化算法,显著降低资源消耗。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本聚类 大型语言模型 约束聚类 自动约束生成 资源优化
📋 核心要点
- 现有文本聚类方法依赖人工标注或成对约束,成本高昂且效率低下,难以有效利用背景知识。
- 该论文提出一种基于LLM自动生成约束集的方法,降低资源消耗,提高查询效率和约束准确性。
- 实验结果表明,该方法在保证聚类准确率的同时,显著降低了LLM查询次数,优于现有方法。
📝 摘要(中文)
聚类是一种基础工具,在包括文本分析在内的广泛应用中引起了极大的兴趣。为了提高聚类准确性,许多研究人员结合了背景知识,通常以must-link和cannot-link约束的形式来指导聚类过程。随着大型语言模型(LLM)的最新发展,人们越来越关注通过基于LLM的自动约束生成来提高聚类质量。本文提出了一种新颖的约束生成方法,通过生成约束集而不是使用传统的成对约束来减少资源消耗。与最先进的方法相比,该方法提高了查询效率和约束准确性。我们进一步引入了一种针对LLM生成约束的特性而定制的约束聚类算法。我们的方法结合了置信度阈值和惩罚机制,以解决潜在的不准确约束。我们在五个文本数据集上评估了我们的方法,同时考虑了约束生成的成本和整体聚类性能。结果表明,我们的方法在实现与最先进算法相当的聚类准确性的同时,将LLM查询的数量减少了20倍以上。
🔬 方法详解
问题定义:论文旨在解决文本聚类中如何有效利用背景知识,同时降低资源消耗的问题。现有方法通常采用人工标注或成对约束,成本高昂且效率低下。利用LLM生成约束虽然可行,但直接生成成对约束会产生大量的LLM查询,带来巨大的计算开销。此外,LLM生成的约束可能存在不准确性,需要有效处理。
核心思路:论文的核心思路是利用LLM生成约束集,而不是传统的成对约束,从而减少LLM查询次数,降低资源消耗。同时,针对LLM生成约束可能存在的不准确性,引入置信度阈值和惩罚机制,提高聚类算法的鲁棒性。
技术框架:该方法主要包含两个阶段:1) 基于LLM的约束生成阶段:利用LLM生成文本数据的约束集,每个约束集包含多个文本样本,这些样本被认为属于同一类别或不同类别。2) 约束聚类阶段:设计一种新的约束聚类算法,该算法利用LLM生成的约束集进行聚类,并结合置信度阈值和惩罚机制来处理不准确的约束。
关键创新:该方法最重要的技术创新点在于提出了基于约束集的LLM约束生成方法,与传统的成对约束生成方法相比,显著减少了LLM查询次数。此外,针对LLM生成约束的不确定性,设计了置信度阈值和惩罚机制,提高了聚类算法的鲁棒性。
关键设计:在约束生成阶段,论文设计了特定的prompt来引导LLM生成高质量的约束集。在约束聚类阶段,论文设计了一种新的目标函数,该目标函数考虑了LLM生成的约束集、置信度阈值和惩罚机制。具体而言,目标函数包含一个聚类损失项和一个约束违反惩罚项,通过调整置信度阈值和惩罚系数来平衡聚类准确性和约束满足程度。
🖼️ 关键图片
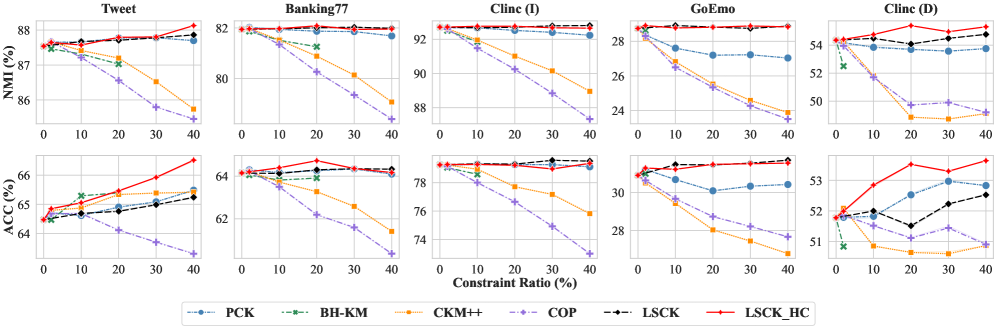
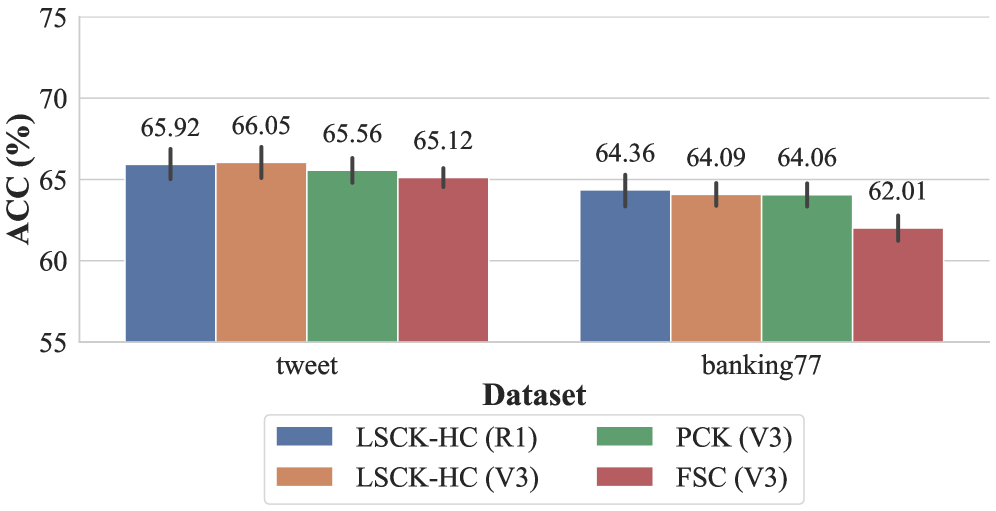
📊 实验亮点
实验结果表明,该方法在五个文本数据集上取得了与最先进算法相当的聚类准确率,同时将LLM查询次数减少了20倍以上。例如,在某个数据集上,该方法在保证聚类准确率不降低的情况下,将LLM查询次数从1000次降低到50次。
🎯 应用场景
该研究成果可应用于各种文本分析任务,如新闻分类、情感分析、主题检测等。通过利用LLM自动生成约束,可以降低人工标注成本,提高聚类效率和准确性。该方法在信息检索、舆情监控、推荐系统等领域具有潜在的应用价值。
📄 摘要(原文)
Clustering is a fundamental tool that has garnered significant interest across a wide range of applications including text analysis. To improve clustering accuracy, many researchers have incorporated background knowledge, typically in the form of must-link and cannot-link constraints, to guide the clustering process. With the recent advent of large language models (LLMs), there is growing interest in improving clustering quality through LLM-based automatic constraint generation. In this paper, we propose a novel constraint-generation approach that reduces resource consumption by generating constraint sets rather than using traditional pairwise constraints. This approach improves both query efficiency and constraint accuracy compared to state-of-the-art methods. We further introduce a constrained clustering algorithm tailored to the characteristics of LLM-generated constraints. Our method incorporates a confidence threshold and a penalty mechanism to address potentially inaccurate constraints. We evaluate our approach on five text datasets, considering both the cost of constraint generation and the overall clustering performance. The results show that our method achieves clustering accuracy comparable to the state-of-the-art algorithms while reducing the number of LLM queries by more than 20 times.