Combating Spurious Correlations in Graph Interpretability via Self-Reflection
作者: Kecheng Cai, Chenyang Xu, Chao Peng
分类: cs.LG, cs.AI
发布日期: 2026-01-16
💡 一句话要点
提出基于自反思的图解释性方法,提升在虚假相关性图上的性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图解释性 自反思 虚假相关性 图神经网络 可解释机器学习
📋 核心要点
- 现有图解释性方法在存在虚假相关性的图数据上表现不佳,难以区分真实和误导性模式。
- 借鉴大语言模型的自反思思想,提出一种迭代式的图解释性框架,通过反馈机制提升性能。
- 实验结果表明,该方法在 Spurious-Motif 基准上显著提升了图解释的准确性。
📝 摘要(中文)
可解释的图学习最近成为机器学习领域的热门研究课题。其目标是识别输入图中对于执行特定图推理任务至关重要的重要节点和边。已经有许多研究致力于此,并提出了各种基准数据集以促进评估。其中,最具挑战性的是 ICLR 2022 提出的 Spurious-Motif 基准。这个合成基准中的数据集经过精心设计,包含虚假相关性,使得模型难以区分真正相关的结构和误导性模式。因此,现有方法在这个基准上的表现明显不如其他基准。本文着重于提高在具有挑战性的 Spurious-Motif 数据集上的可解释性。我们证明了通常用于大型语言模型以解决复杂任务的自反思技术,也可以有效地用于增强具有强虚假相关性的数据集中的可解释性。具体来说,我们提出了一个可以与现有可解释图学习方法集成的自反思框架。当一种方法为每个节点和边生成重要性分数时,我们的框架将这些预测反馈回原始方法以执行第二轮评估。这个迭代过程模仿了大型语言模型如何使用自反思提示来重新评估它们之前的输出。我们进一步从图表示学习的角度分析了这种改进背后的原因,这促使我们提出了一种基于这种反馈机制的微调训练方法。
🔬 方法详解
问题定义:论文旨在解决图解释性方法在存在虚假相关性的图数据上表现不佳的问题。现有方法难以区分图中真正重要的结构和由虚假相关性引起的误导性模式,导致解释结果不准确,影响模型的可信度和可靠性。Spurious-Motif 数据集是专门为此设计的挑战性基准。
核心思路:论文的核心思路是借鉴大型语言模型中常用的自反思技术,通过迭代的方式不断修正和完善图解释的结果。模型首先进行初步的图解释,然后将解释结果反馈回模型自身,进行第二轮的评估和修正。这个过程类似于人类的反思过程,可以帮助模型更好地理解图的结构和关系,从而消除虚假相关性的影响。
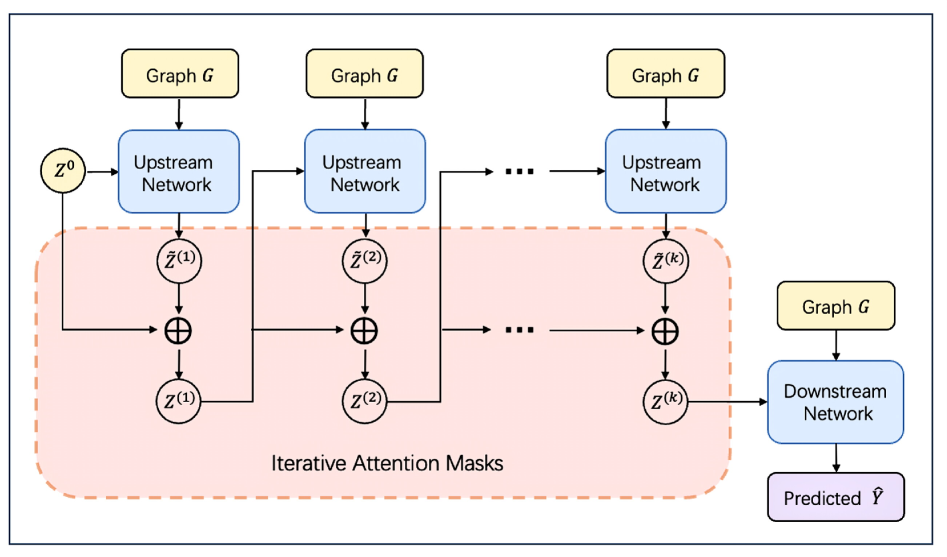
技术框架:该方法的核心是一个自反思框架,可以与现有的可解释图学习方法集成。框架的主要流程如下:1) 使用现有的可解释图学习方法对输入图进行初步的解释,得到节点和边的重要性分数。2) 将这些重要性分数作为反馈信息,重新输入到原始的可解释图学习方法中。3) 模型基于反馈信息进行第二轮的评估和修正,得到更准确的节点和边的重要性分数。4) 可以选择重复上述过程多次,以进一步提升解释的准确性。
关键创新:该方法最重要的创新点是将自反思的思想引入到图解释性领域。通过迭代的反馈机制,模型可以不断地修正和完善自身的解释结果,从而更好地应对虚假相关性的挑战。此外,论文还从图表示学习的角度分析了自反思机制有效的原因,并提出了一种基于反馈机制的微调训练方法。
关键设计:该方法的关键设计在于如何将反馈信息有效地融入到可解释图学习方法中。一种常见的方法是将重要性分数作为节点或边的特征,重新输入到图神经网络中。此外,论文还提出了一种基于反馈机制的微调训练方法,通过调整损失函数,使模型更加关注真正重要的结构,从而提高解释的准确性。具体的参数设置和网络结构取决于所使用的可解释图学习方法。
🖼️ 关键图片
📊 实验亮点
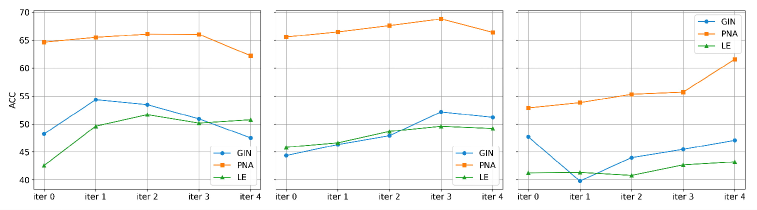
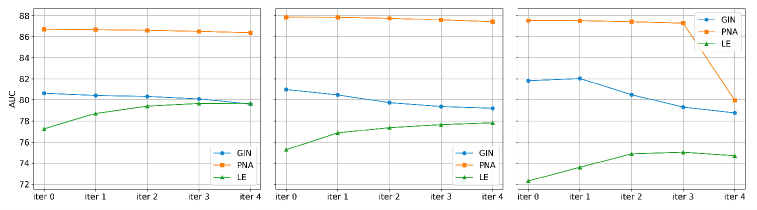
论文在 Spurious-Motif 基准数据集上进行了实验,结果表明,所提出的自反思框架可以显著提升现有可解释图学习方法的性能。具体的性能提升幅度取决于所使用的可解释图学习方法和数据集的特点,但总体而言,该方法能够有效地消除虚假相关性的影响,提高图解释的准确性和可靠性。
🎯 应用场景
该研究成果可应用于对图结构数据进行可解释性分析的各种领域,例如社交网络分析、生物信息学、知识图谱推理等。通过提高图解释的准确性,可以帮助人们更好地理解复杂系统的运作机制,发现潜在的规律和关联,并做出更明智的决策。例如,在社交网络中,可以识别出影响舆论传播的关键节点;在生物信息学中,可以找到与疾病相关的基因或蛋白质。
📄 摘要(原文)
Interpretable graph learning has recently emerged as a popular research topic in machine learning. The goal is to identify the important nodes and edges of an input graph that are crucial for performing a specific graph reasoning task. A number of studies have been conducted in this area, and various benchmark datasets have been proposed to facilitate evaluation. Among them, one of the most challenging is the Spurious-Motif benchmark, introduced at ICLR 2022. The datasets in this synthetic benchmark are deliberately designed to include spurious correlations, making it particularly difficult for models to distinguish truly relevant structures from misleading patterns. As a result, existing methods exhibit significantly worse performance on this benchmark compared to others. In this paper, we focus on improving interpretability on the challenging Spurious-Motif datasets. We demonstrate that the self-reflection technique, commonly used in large language models to tackle complex tasks, can also be effectively adapted to enhance interpretability in datasets with strong spurious correlations. Specifically, we propose a self-reflection framework that can be integrated with existing interpretable graph learning methods. When such a method produces importance scores for each node and edge, our framework feeds these predictions back into the original method to perform a second round of evaluation. This iterative process mirrors how large language models employ self-reflective prompting to reassess their previous outputs. We further analyze the reasons behind this improvement from the perspective of graph representation learning, which motivates us to propose a fine-tuning training method based on this feedback mechanism.