HOSL: Hybrid-Order Split Learning for Memory-Constrained Edge Training
作者: Aakriti, Zhe Li, Dandan Liang, Chao Huang, Rui Li, Haibo Yang
分类: cs.LG
发布日期: 2026-01-16
备注: 12 pages, 2 figures, 6 tables. Submitted to WiOpt 2026
💡 一句话要点
提出HOSL以解决边缘设备内存受限的训练问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分割学习 边缘计算 内存优化 零阶优化 一阶优化 大型语言模型 协作训练
📋 核心要点
- 现有的分割学习方法主要依赖一阶优化,导致客户端需要存储大量中间激活值,造成内存开销过大。
- HOSL框架通过在客户端使用零阶优化来减少内存消耗,同时在服务器端使用一阶优化以确保快速收敛和良好性能。
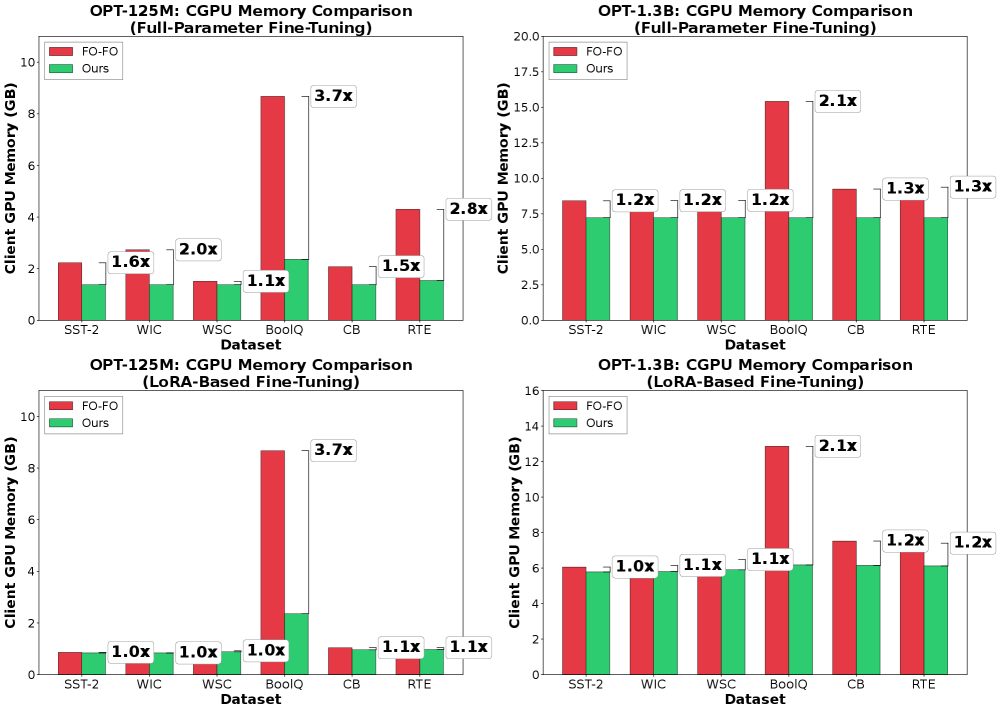
- 实验结果显示,HOSL在多个任务中将客户端GPU内存减少了最多3.7倍,且准确率与基线相差不大,验证了其有效性。
📝 摘要(中文)
Split learning (SL) 使得资源受限的边缘设备与计算能力强大的服务器之间能够协作训练大型语言模型(LLMs),通过在网络边界上划分模型计算。然而,现有的SL系统主要依赖一阶(FO)优化,这需要客户端存储中间量,如激活值,导致显著的内存开销,基本抵消了模型分区的好处。相对而言,零阶(ZO)优化消除了反向传播,显著减少了内存使用,但通常会遭遇收敛速度慢和性能下降的问题。本文提出了一种新颖的混合阶分割学习框架HOSL,通过在客户端上战略性地整合ZO优化与服务器端的FO优化,解决了内存效率与优化效果之间的基本权衡。HOSL在客户端采用内存高效的ZO梯度估计,消除了反向传播和激活存储,减少了客户端内存消耗。同时,服务器端的FO优化确保了快速收敛和竞争性能。理论上,我们证明HOSL达到了$ ext{O}( rac{ ext{sqrt}(d_c)}{TQ})$的收敛率,依赖于客户端模型维度$d_c$而非完整模型维度$d$,表明随着更多计算被卸载到服务器,收敛性得以改善。对OPT模型(125M和1.3B参数)在6个任务上的广泛实验表明,HOSL将客户端GPU内存减少了最多3.7倍,同时准确率与基线相差在0.20%-4.23%之间。此外,HOSL在性能上比ZO基线提高了最多15.55%,验证了我们混合策略在边缘设备上内存高效训练的有效性。
🔬 方法详解
问题定义:本文旨在解决现有分割学习方法在内存受限的边缘设备上训练大型语言模型时的内存开销问题。现有方法主要依赖一阶优化,导致客户端需要存储中间激活值,从而增加了内存负担。
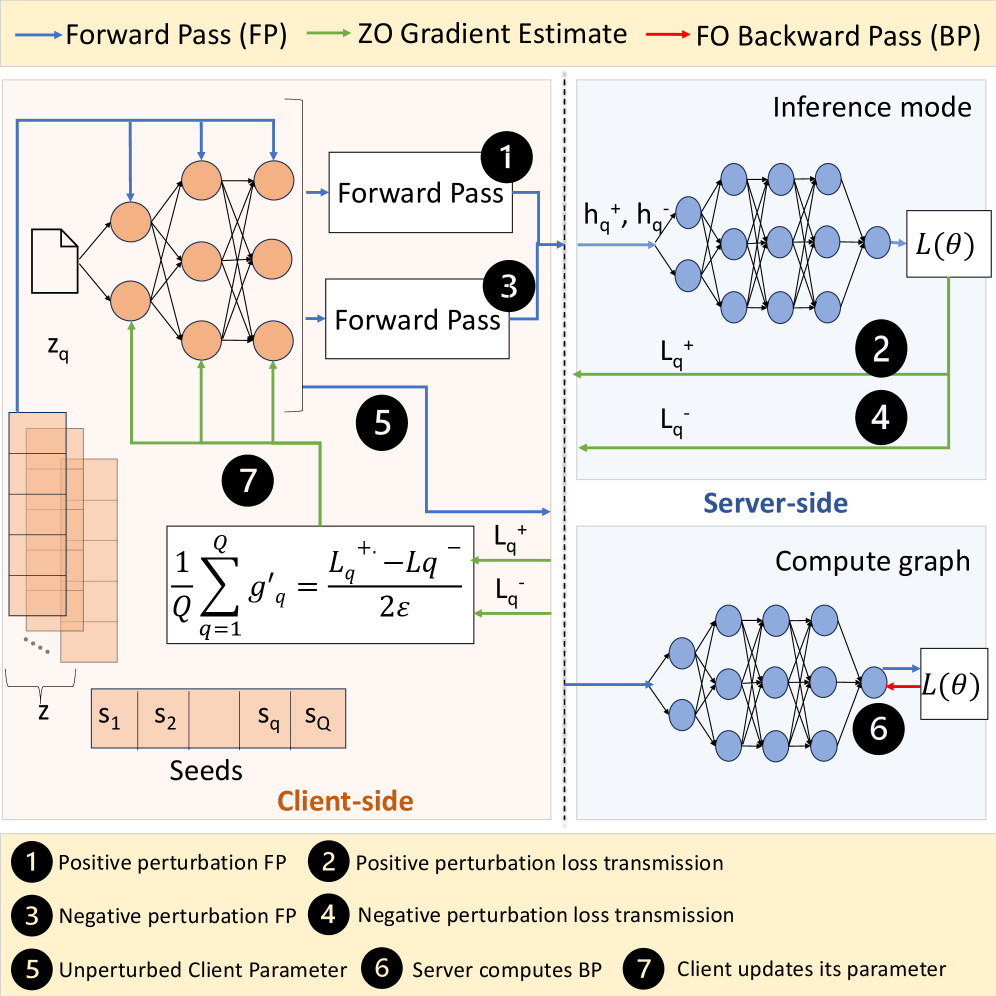
核心思路:HOSL框架的核心思想是将零阶优化与一阶优化相结合,利用零阶优化在客户端消除反向传播和激活存储的需求,从而降低内存消耗,同时在服务器端保持一阶优化以确保快速收敛。
技术框架:HOSL的整体架构包括客户端和服务器两个主要模块。客户端负责执行零阶优化以进行梯度估计,而服务器则执行一阶优化以更新模型参数。通过这种分工,HOSL能够在保证性能的同时显著降低内存使用。
关键创新:HOSL的主要创新在于其混合优化策略,结合了零阶和一阶优化的优点,解决了内存效率与优化效果之间的权衡。这一策略使得客户端能够在不牺牲性能的情况下,显著减少内存使用。
关键设计:HOSL在客户端采用内存高效的零阶梯度估计方法,避免了反向传播的内存开销。同时,服务器端的一阶优化确保了模型的快速收敛。具体的参数设置和损失函数设计在实验中经过优化,以确保最佳性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HOSL在多个任务上将客户端GPU内存减少了最多3.7倍,相较于一阶优化方法,准确率仅相差0.20%-4.23%。此外,HOSL在性能上比零阶基线提高了最多15.55%,验证了其混合策略的有效性。
🎯 应用场景
HOSL框架在边缘计算场景中具有广泛的应用潜力,尤其是在资源受限的设备上进行大型模型的训练。其内存高效的特性使得在移动设备、物联网设备等场景中能够实现更高效的模型训练,推动智能设备的普及和应用。未来,HOSL有望在更多实际应用中发挥重要作用,如智能家居、自动驾驶等领域。
📄 摘要(原文)
Split learning (SL) enables collaborative training of large language models (LLMs) between resource-constrained edge devices and compute-rich servers by partitioning model computation across the network boundary. However, existing SL systems predominantly rely on first-order (FO) optimization, which requires clients to store intermediate quantities such as activations for backpropagation. This results in substantial memory overhead, largely negating benefits of model partitioning. In contrast, zeroth-order (ZO) optimization eliminates backpropagation and significantly reduces memory usage, but often suffers from slow convergence and degraded performance. In this work, we propose HOSL, a novel Hybrid-Order Split Learning framework that addresses this fundamental trade-off between memory efficiency and optimization effectiveness by strategically integrating ZO optimization on the client side with FO optimization on the server side. By employing memory-efficient ZO gradient estimation at the client, HOSL eliminates backpropagation and activation storage, reducing client memory consumption. Meanwhile, server-side FO optimization ensures fast convergence and competitive performance. Theoretically, we show that HOSL achieves a $\mathcal{O}(\sqrt{d_c/TQ})$ rate, which depends on client-side model dimension $d_c$ rather than the full model dimension $d$, demonstrating that convergence improves as more computation is offloaded to the server. Extensive experiments on OPT models (125M and 1.3B parameters) across 6 tasks demonstrate that HOSL reduces client GPU memory by up to 3.7$\times$ compared to the FO method while achieving accuracy within 0.20%-4.23% of this baseline. Furthermore, HOSL outperforms the ZO baseline by up to 15.55%, validating the effectiveness of our hybrid strategy for memory-efficient training on edge devices.