Single-Stage Huffman Encoder for ML Compression
作者: Aditya Agrawal, Albert Magyar, Hiteshwar Eswaraiah, Patrick Sheridan, Pradeep Janedula, Ravi Krishnan Venkatesan, Krishna Nair, Ravi Iyer
分类: cs.LG
发布日期: 2026-01-15
备注: 5 pages, 4 figures
💡 一句话要点
提出单阶段霍夫曼编码器,解决LLM压缩中带宽瓶颈问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 霍夫曼编码 模型压缩 大型语言模型 网络带宽 单阶段编码
📋 核心要点
- LLM训练和部署面临网络带宽瓶颈,传统霍夫曼编码因多阶段流程引入额外开销。
- 提出单阶段霍夫曼编码器,利用固定码本避免频率分析和码本传输,降低延迟。
- 实验表明,该方法在Gemma 2B模型上实现了接近最优压缩效果,且开销极低。
📝 摘要(中文)
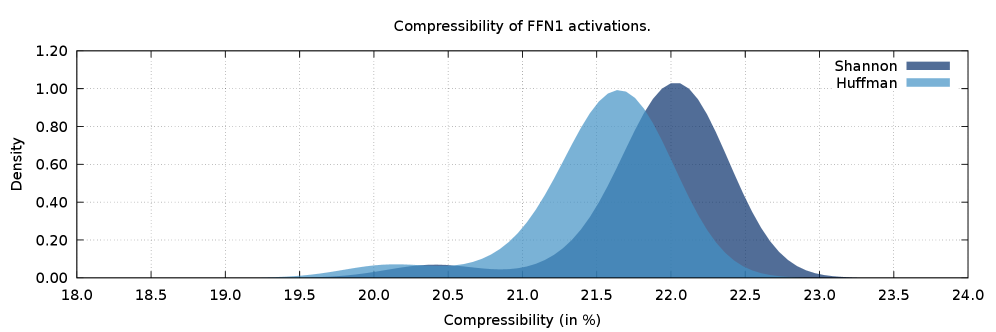
大型语言模型(LLM)的训练和部署需要在多个加速器上进行数据划分,而集合操作常常受限于网络带宽。使用霍夫曼编码进行无损压缩是一种有效的缓解方法,但其三阶段设计(包括即时频率分析、码本生成以及码本与数据一同传输)引入了计算、延迟和数据开销,这对于诸如die-to-die通信等对延迟敏感的场景来说是难以接受的。本文提出了一种单阶段霍夫曼编码器,通过使用从先前数据批次的平均概率分布中导出的固定码本,消除了这些开销。通过对Gemma 2B模型的分析,我们证明了张量在不同层和分片之间表现出高度的统计相似性。使用这种方法,我们实现了在每个分片霍夫曼编码的0.5%以内以及理想香农可压缩性的1%以内的压缩率,从而实现了高效的即时压缩。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在分布式训练和推理过程中,由于网络带宽限制导致的通信瓶颈问题。传统的霍夫曼编码虽然能有效压缩数据,但其三阶段流程(频率分析、码本生成、码本传输)引入了显著的计算开销、延迟和数据传输开销,尤其是在对延迟高度敏感的场景(如芯片间通信)中,这些开销是不可接受的。
核心思路:论文的核心思路是利用LLM中张量在不同层和分片之间表现出的高度统计相似性,预先计算并固定霍夫曼码本。通过使用从先前数据批次的平均概率分布中导出的固定码本,避免了在线频率分析和码本传输,从而显著降低了延迟和计算开销。
技术框架:该方法的核心在于使用预先计算好的固定霍夫曼码本进行数据压缩。整体流程包括:1) 离线阶段:分析历史数据,计算平均概率分布,生成固定霍夫曼码本。2) 在线阶段:使用该固定码本对新的数据进行压缩和解压缩,无需进行额外的频率分析和码本传输。
关键创新:最重要的技术创新点在于使用固定码本替代了传统的在线码本生成过程。这种方法利用了LLM中张量统计特性的稳定性,在保证压缩率的同时,极大地降低了延迟和计算开销。与现有方法的本质区别在于,它将一个动态的、多阶段的压缩过程简化为一个静态的、单阶段的过程。
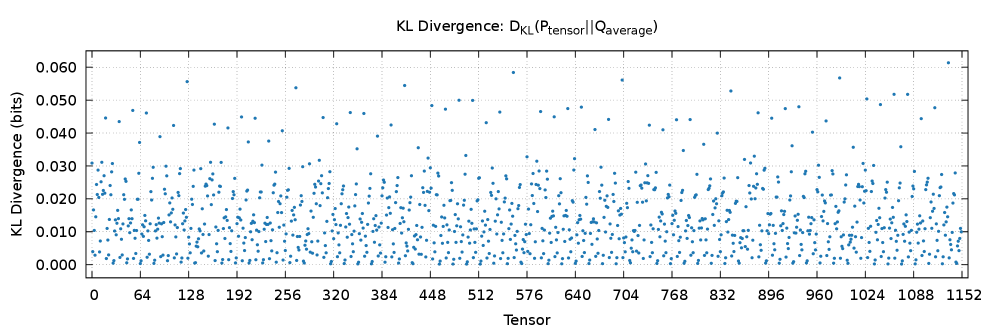
关键设计:关键设计在于如何选择合适的历史数据来生成固定码本,以及如何评估固定码本的性能。论文通过对Gemma 2B模型的分析,验证了张量在不同层和分片之间的统计相似性,从而证明了使用固定码本的可行性。具体的参数设置和损失函数未知,因为论文侧重于编码框架的创新,而非具体的模型训练。
🖼️ 关键图片
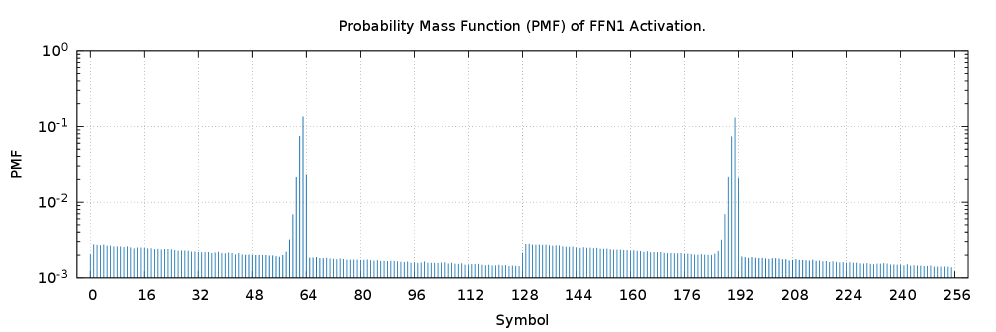
📊 实验亮点
实验结果表明,该单阶段霍夫曼编码器在Gemma 2B模型上实现了接近最优的压缩效果,压缩率在每个分片霍夫曼编码的0.5%以内,以及理想香农可压缩性的1%以内。同时,由于避免了在线频率分析和码本传输,显著降低了延迟和计算开销,实现了高效的即时压缩。
🎯 应用场景
该研究成果可广泛应用于需要高速数据传输和低延迟的场景,例如分布式机器学习、芯片间通信、高性能计算等。通过降低数据传输量,可以有效缓解网络带宽瓶颈,提高系统整体性能。未来,该方法有望应用于边缘计算设备,实现更高效的模型部署和推理。
📄 摘要(原文)
Training and serving Large Language Models (LLMs) require partitioning data across multiple accelerators, where collective operations are frequently bottlenecked by network bandwidth. Lossless compression using Huffman codes is an effective way to alleviate the issue, however, its three-stage design requiring on-the-fly frequency analysis, codebook generation and transmission of codebook along with data introduces computational, latency and data overheads which are prohibitive for latency-sensitive scenarios such as die-to-die communication. This paper proposes a single-stage Huffman encoder that eliminates these overheads by using fixed codebooks derived from the average probability distribution of previous data batches. Through our analysis of the Gemma 2B model, we demonstrate that tensors exhibit high statistical similarity across layers and shards. Using this approach we achieve compression within 0.5% of per-shard Huffman coding and within 1% of the ideal Shannon compressibility, enabling efficient on-the-fly compression.