PACEvolve: Enabling Long-Horizon Progress-Aware Consistent Evolution
作者: Minghao Yan, Bo Peng, Benjamin Coleman, Ziqi Chen, Zhouhang Xie, Zhankui He, Noveen Sachdeva, Isabella Ye, Weili Wang, Chi Wang, Ed H. Chi, Wang-Cheng Kang, Derek Zhiyuan Cheng, Beidou Wang
分类: cs.NE, cs.LG
发布日期: 2026-01-15
💡 一句话要点
PACEvolve:实现长程、感知进度且一致的进化搜索框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 进化搜索 大型语言模型 上下文管理 探索-利用平衡 自适应采样 程序合成 算法设计
📋 核心要点
- 现有LLM进化搜索方法缺乏系统性,面临上下文污染、模式崩溃和弱协作等挑战。
- PACEvolve通过分层上下文管理、动量回溯和自适应采样策略,实现稳健的上下文管理和搜索动态。
- 实验表明,PACEvolve在LLM-SR、KernelBench和Modded NanoGPT上均取得了显著的性能提升。
📝 摘要(中文)
大型语言模型(LLM)已成为进化搜索的强大算子,但高效搜索框架的设计仍然是临时性的。现有的LLM在环系统中缺乏系统性的方法来管理进化过程,存在三个主要问题:上下文污染,即实验历史偏见未来的候选生成;模式崩溃,即由于不良的探索-利用平衡,智能体停滞在局部最小值;以及弱协作,即刚性的交叉策略未能有效利用并行搜索轨迹。我们引入了Progress-Aware Consistent Evolution (PACEvolve)框架,旨在稳健地管理智能体的上下文和搜索动态,以应对这些挑战。PACEvolve结合了分层上下文管理(HCM)与剪枝来解决上下文污染;基于动量的回溯(MBB)来逃离局部最小值;以及一种自适应采样策略,它统一了回溯和交叉以实现动态搜索协调(CE),允许智能体平衡内部改进与跨轨迹协作。我们证明了PACEvolve提供了一条系统性的路径,以实现一致的、长程的自我改进,在LLM-SR和KernelBench上取得了最先进的结果,同时发现了超越Modded NanoGPT记录的解决方案。
🔬 方法详解
问题定义:现有基于LLM的进化搜索方法在长程进化过程中面临三大挑战:一是上下文污染,即过多的历史实验信息干扰了新候选解的生成;二是模式崩溃,由于探索和利用不平衡,算法容易陷入局部最优;三是弱协作,固定的交叉策略无法有效利用并行搜索轨迹的信息。这些问题限制了LLM在复杂问题上的进化能力。
核心思路:PACEvolve的核心思路是通过系统性的框架设计,解决LLM进化搜索中的上下文管理、探索-利用平衡和协作问题。它旨在提供一种更稳健、一致且高效的进化搜索方法,使LLM能够更好地进行长程自我改进。
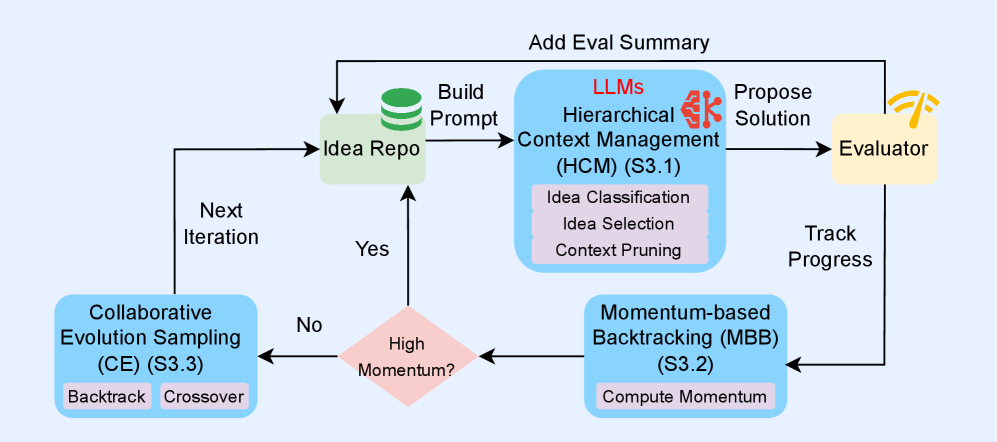
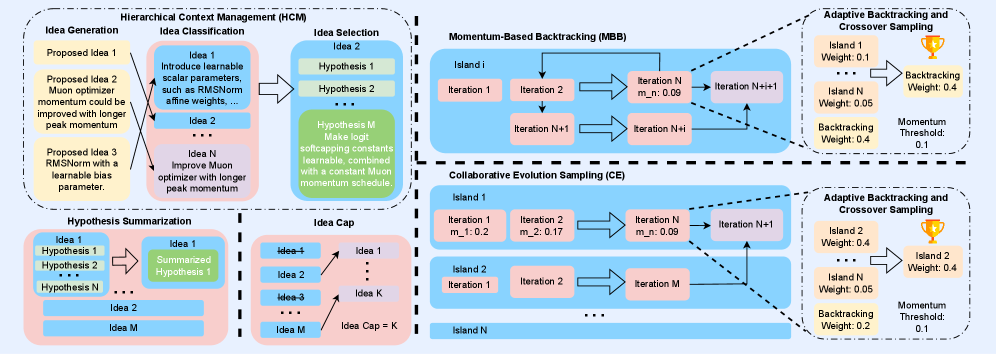
技术框架:PACEvolve包含三个主要模块:1) 分层上下文管理(HCM)与剪枝,用于解决上下文污染问题,通过分层组织上下文信息并定期剪枝,减少噪声干扰。2) 基于动量的回溯(MBB),用于逃离局部最小值,通过记录搜索过程中的动量信息,帮助智能体跳出停滞区域。3) 自适应采样策略(CE),统一回溯和交叉,实现动态搜索协调,允许智能体在内部改进和跨轨迹协作之间进行平衡。
关键创新:PACEvolve的关键创新在于其系统性的框架设计,它将上下文管理、探索-利用平衡和协作整合到一个统一的框架中。与现有方法相比,PACEvolve能够更有效地管理LLM的搜索过程,避免上下文污染和模式崩溃,并促进智能体之间的协作。自适应采样策略是另一个重要创新,它允许智能体根据搜索状态动态调整回溯和交叉的概率,从而更好地适应不同的搜索阶段。
关键设计:HCM采用分层结构组织上下文,并使用剪枝策略定期删除不相关的信息。MBB使用动量信息来指导回溯方向,避免盲目搜索。CE使用一个可学习的采样策略,根据当前搜索状态动态调整回溯和交叉的概率。具体的参数设置和损失函数细节在论文中进行了详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
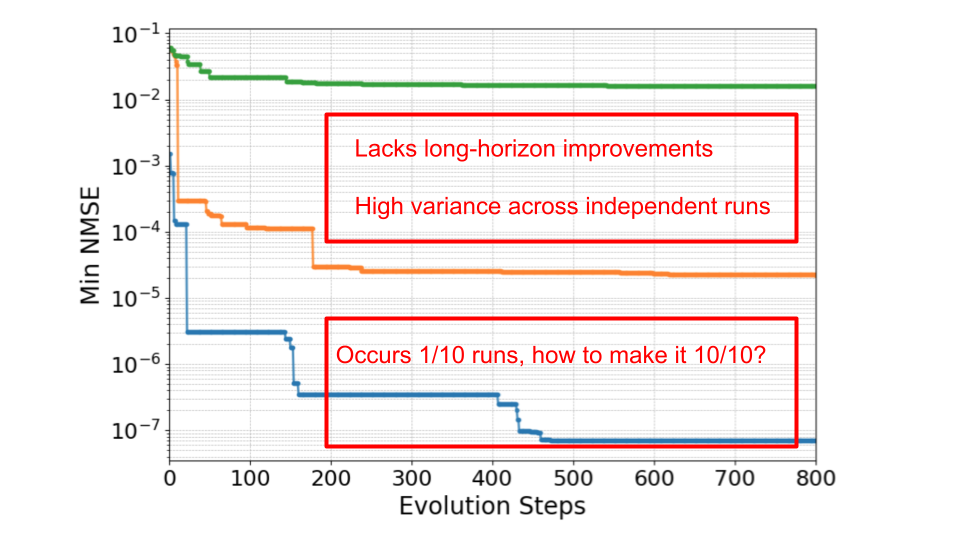
PACEvolve在LLM-SR和KernelBench上取得了state-of-the-art的结果,证明了其在进化搜索方面的优越性。更重要的是,PACEvolve在Modded NanoGPT上发现了超越现有记录的解决方案,表明其具有强大的长程自我改进能力。具体的性能提升数据未知,但结果表明PACEvolve显著优于现有方法。
🎯 应用场景
PACEvolve可应用于各种需要复杂问题求解和优化的领域,例如:程序合成、算法设计、超参数优化、以及新材料发现等。通过利用LLM的强大生成能力和PACEvolve的系统性搜索框架,可以自动发现高性能的解决方案,加速相关领域的研发进程,并可能带来突破性的创新。
📄 摘要(原文)
Large Language Models (LLMs) have emerged as powerful operators for evolutionary search, yet the design of efficient search scaffolds remains ad hoc. While promising, current LLM-in-the-loop systems lack a systematic approach to managing the evolutionary process. We identify three distinct failure modes: Context Pollution, where experiment history biases future candidate generation; Mode Collapse, where agents stagnate in local minima due to poor exploration-exploitation balance; and Weak Collaboration, where rigid crossover strategies fail to leverage parallel search trajectories effectively. We introduce Progress-Aware Consistent Evolution (PACEvolve), a framework designed to robustly govern the agent's context and search dynamics, to address these challenges. PACEvolve combines hierarchical context management (HCM) with pruning to address context pollution; momentum-based backtracking (MBB) to escape local minima; and a self-adaptive sampling policy that unifies backtracking and crossover for dynamic search coordination (CE), allowing agents to balance internal refinement with cross-trajectory collaboration. We demonstrate that PACEvolve provides a systematic path to consistent, long-horizon self-improvement, achieving state-of-the-art results on LLM-SR and KernelBench, while discovering solutions surpassing the record on Modded NanoGPT.