DeFlow: Decoupling Manifold Modeling and Value Maximization for Offline Policy Extraction
作者: Zhancun Mu
分类: cs.LG
发布日期: 2026-01-15
备注: 13 pages, 3 figures
💡 一句话要点
DeFlow:解耦流形建模与价值最大化,用于离线策略提取
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 离线强化学习 流匹配 策略提取 流形建模 价值最大化
📋 核心要点
- 现有离线强化学习方法在优化生成策略时计算成本高昂,需要通过ODE求解器反向传播。
- DeFlow通过在流形信任区域内学习轻量级细化模块,避免了求解器微分和损失平衡,保证了稳定提升。
- 实验表明,DeFlow在OGBench基准测试中表现出色,并能高效地进行离线到在线的适应。
📝 摘要(中文)
本文提出DeFlow,一个解耦的离线强化学习框架,它利用流匹配来忠实地捕获复杂的行为流形。优化生成策略在计算上是极其昂贵的,通常需要通过ODE求解器进行反向传播。为了解决这个问题,我们没有牺牲通过单步蒸馏实现的迭代生成能力,而是在流形的一个显式的、数据导出的信任区域内学习一个轻量级的细化模块。通过这种方式,我们绕过了求解器微分,并消除了平衡损失项的需要,确保了稳定的改进,同时完全保留了流的迭代表达能力。实验结果表明,DeFlow在具有挑战性的OGBench基准测试中取得了优异的性能,并展示了高效的离线到在线适应能力。
🔬 方法详解
问题定义:离线强化学习旨在利用静态数据集学习最优策略。现有方法,特别是基于生成模型的策略学习,面临着计算复杂度高的挑战。直接优化生成策略通常需要通过常微分方程(ODE)求解器进行反向传播,这在计算上非常昂贵,并且可能导致训练不稳定。此外,单步蒸馏方法虽然可以加速推理,但牺牲了生成模型的迭代表达能力。
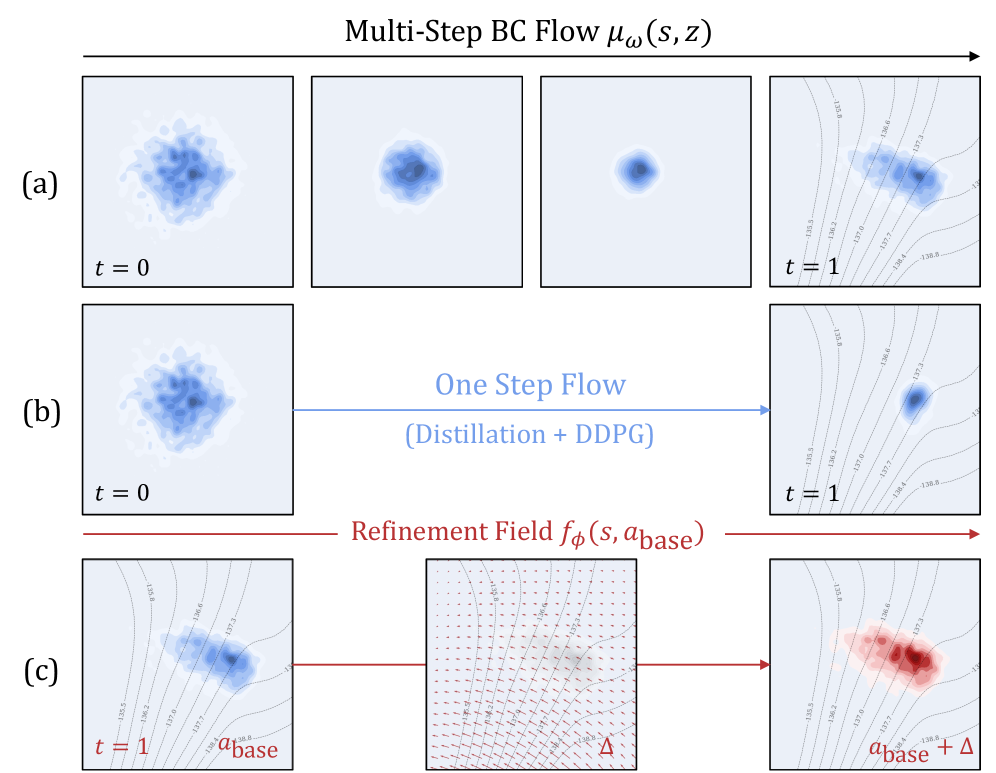
核心思路:DeFlow的核心思路是将流形建模(行为策略的表示)和价值最大化(策略优化)解耦。它首先使用流匹配技术学习一个能够忠实捕获行为流形的生成模型。然后,在流形的一个显式信任区域内,学习一个轻量级的细化模块来提升策略性能。这种解耦设计避免了直接对生成模型进行复杂的优化,从而降低了计算成本并提高了训练稳定性。
技术框架:DeFlow框架包含两个主要模块:流形建模模块和策略细化模块。流形建模模块使用流匹配技术,通过学习一个时间相关的向量场来建模行为策略的流形。策略细化模块则在流形建模的基础上,学习一个轻量级的神经网络,用于在流形的一个信任区域内对策略进行微调。整个流程包括:1. 使用离线数据训练流匹配模型,得到行为流形的表示;2. 定义流形上的信任区域;3. 在信任区域内,训练策略细化模块,以最大化累积奖励。
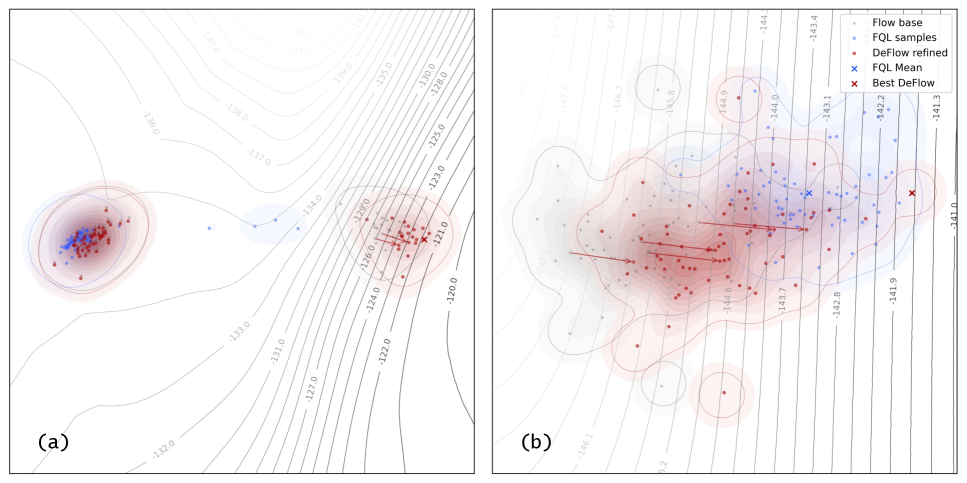
关键创新:DeFlow的关键创新在于解耦了流形建模和价值最大化过程。与直接优化生成策略的方法不同,DeFlow首先学习一个精确的行为流形表示,然后通过一个轻量级的细化模块来提升策略性能。这种解耦设计避免了复杂的优化过程,降低了计算成本,并提高了训练稳定性。此外,DeFlow通过在流形的信任区域内进行策略细化,保证了策略改进的安全性。
关键设计:DeFlow的关键设计包括:1. 使用流匹配技术进行流形建模,确保能够精确地捕获行为策略的复杂分布;2. 定义流形上的信任区域,限制策略细化的范围,避免策略偏离原始数据分布过远;3. 使用轻量级的神经网络作为策略细化模块,降低计算成本;4. 使用合适的损失函数来训练策略细化模块,例如,可以使用优势函数或Q函数来指导策略改进。
🖼️ 关键图片
📊 实验亮点
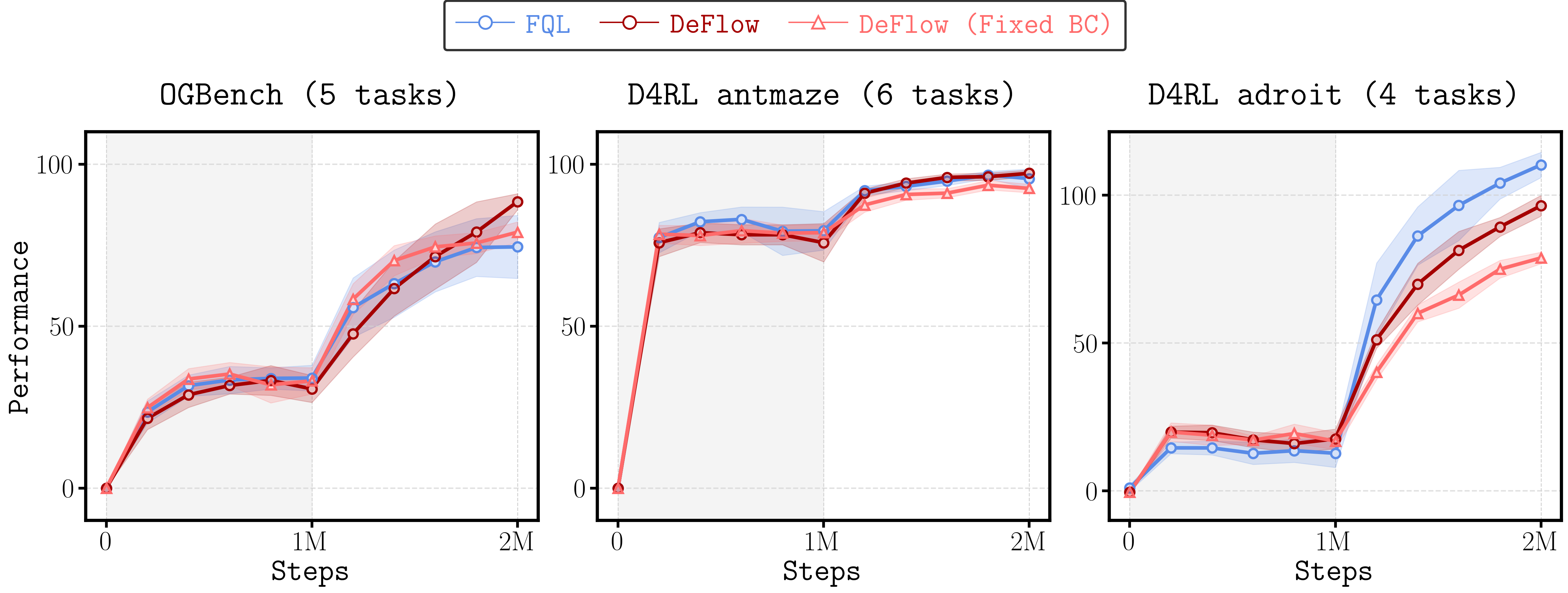
DeFlow在OGBench基准测试中取得了优异的性能,显著优于现有的离线强化学习算法。具体而言,DeFlow在多个任务上取得了最高的平均奖励,并且在离线到在线的适应过程中表现出更高的效率。实验结果表明,DeFlow能够有效地利用离线数据学习高性能的策略,并且能够快速地适应新的环境。
🎯 应用场景
DeFlow具有广泛的应用前景,例如在机器人控制、自动驾驶、推荐系统等领域。它可以利用离线数据学习高性能的策略,并能高效地适应新的环境。此外,DeFlow的解耦设计使得策略学习过程更加稳定和可控,有助于解决实际应用中遇到的各种挑战。未来,DeFlow可以进一步扩展到多智能体强化学习、元强化学习等领域。
📄 摘要(原文)
We present DeFlow, a decoupled offline RL framework that leverages flow matching to faithfully capture complex behavior manifolds. Optimizing generative policies is computationally prohibitive, typically necessitating backpropagation through ODE solvers. We address this by learning a lightweight refinement module within an explicit, data-derived trust region of the flow manifold, rather than sacrificing the iterative generation capability via single-step distillation. This way, we bypass solver differentiation and eliminate the need for balancing loss terms, ensuring stable improvement while fully preserving the flow's iterative expressivity. Empirically, DeFlow achieves superior performance on the challenging OGBench benchmark and demonstrates efficient offline-to-online adaptation.