SuS: Strategy-aware Surprise for Intrinsic Exploration
作者: Mark Kashirskiy, Ilya Makarov
分类: cs.LG, cs.AI, cs.CL, cs.GT
发布日期: 2026-01-15
备注: 8 pages, 7 figures, 3 tables. Code available at https://github.com/mariklolik/sus
💡 一句话要点
提出策略感知惊讶以解决强化学习中的探索问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 内在动机 策略稳定性 策略惊讶 探索效率 数学推理 多样性
📋 核心要点
- 现有的强化学习探索方法往往仅依赖于状态预测误差,导致探索效率低下。
- 论文提出的SuS框架通过引入策略稳定性和策略惊讶两个组件,增强了探索的有效性。
- 实验结果表明,SuS在数学推理任务中显著提升了准确性和解决方案的多样性。
📝 摘要(中文)
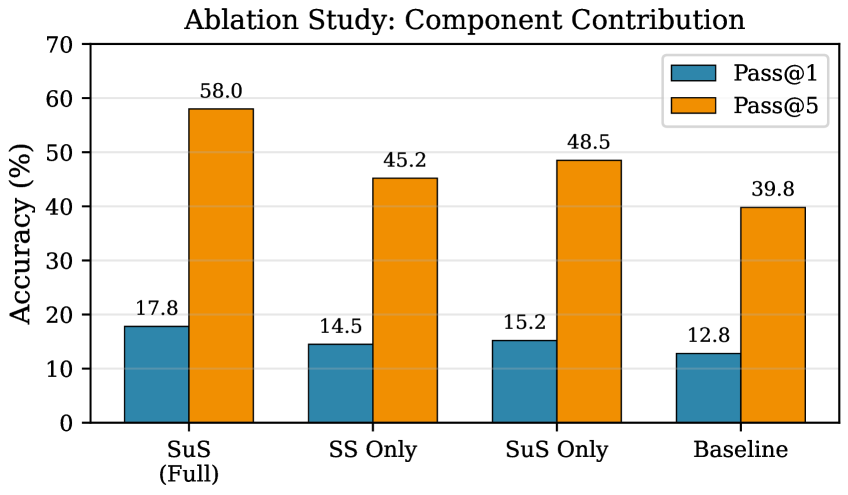
我们提出了策略感知惊讶(SuS),这是一种新颖的内在动机框架,利用预测前后不匹配作为探索中的新奇信号。与传统的好奇心驱动方法仅依赖状态预测误差不同,SuS引入了两个互补组件:策略稳定性(SS)和策略惊讶(SuS)。SS衡量行为策略在时间步骤间的一致性,而SuS则捕捉相对于代理当前策略表示的意外结果。我们的组合奖励公式通过学习的权重系数利用这两个信号。我们在数学推理任务中评估SuS,显示出在准确性和解决方案多样性方面的显著改善。消融研究确认去除任一组件都会导致至少10%的性能下降,验证了我们方法的协同特性。SuS在Pass@1上提高了17.4%,在Pass@5上提高了26.4%,同时在训练过程中保持了更高的策略多样性。
🔬 方法详解
问题定义:本论文旨在解决强化学习中探索效率不足的问题,现有方法多依赖于状态预测误差,未能充分利用策略信息。
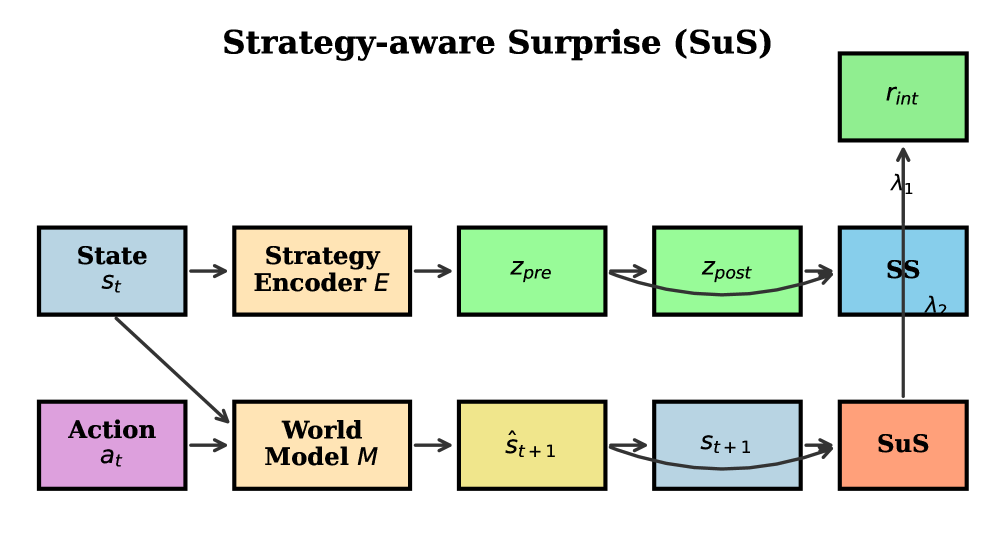
核心思路:SuS框架通过结合策略稳定性(SS)和策略惊讶(SuS)两个信号,提供了一种新的内在动机机制,以促进更有效的探索。
技术框架:SuS的整体架构包括两个主要模块:策略稳定性模块用于评估行为一致性,策略惊讶模块用于捕捉意外结果。通过学习的权重系数将这两个信号结合到奖励函数中。
关键创新:SuS的核心创新在于引入了策略稳定性和策略惊讶两个互补的信号,这与传统方法的单一状态预测误差形成了本质区别,增强了探索的多样性和有效性。
关键设计:在设计中,使用了学习的权重系数来动态调整策略稳定性和策略惊讶的影响力,确保了奖励信号的灵活性和适应性。
🖼️ 关键图片
📊 实验亮点
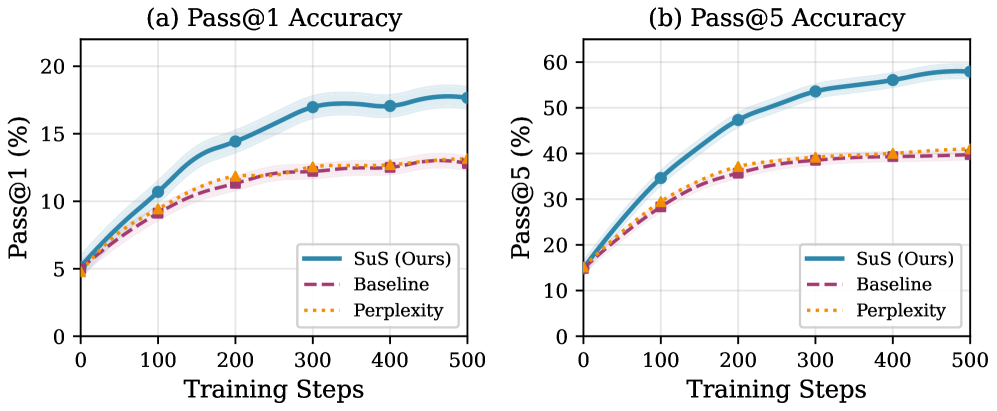
实验结果显示,SuS在Pass@1上提高了17.4%,在Pass@5上提高了26.4%,相较于基线方法显著提升。同时,SuS在训练过程中保持了更高的策略多样性,验证了其有效性。
🎯 应用场景
该研究的潜在应用领域包括机器人导航、游戏智能体以及其他需要高效探索的强化学习任务。通过提升探索效率,SuS可以帮助智能体更快地适应复杂环境,进而提高决策质量和任务完成率。
📄 摘要(原文)
We propose Strategy-aware Surprise (SuS), a novel intrinsic motivation framework that uses pre-post prediction mismatch as a novelty signal for exploration in reinforcement learning. Unlike traditional curiosity-driven methods that rely solely on state prediction error, SuS introduces two complementary components: Strategy Stability (SS) and Strategy Surprise (SuS). SS measures consistency in behavioral strategy across temporal steps, while SuS captures unexpected outcomes relative to the agent's current strategy representation. Our combined reward formulation leverages both signals through learned weighting coefficients. We evaluate SuS on mathematical reasoning tasks using large language models, demonstrating significant improvements in both accuracy and solution diversity. Ablation studies confirm that removing either component results in at least 10% performance degradation, validating the synergistic nature of our approach. SuS achieves 17.4% improvement in Pass@1 and 26.4% improvement in Pass@5 compared to baseline methods, while maintaining higher strategy diversity throughout training.