Queueing-Aware Optimization of Reasoning Tokens for Accuracy-Latency Trade-offs in LLM Servers
作者: Emre Ozbas, Melih Bastopcu
分类: cs.LG, cs.AI, cs.IT, cs.NI, math.OC
发布日期: 2026-01-15
💡 一句话要点
针对LLM服务器,提出队列感知的推理Token优化方法,实现精度-延迟权衡。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM服务器 队列论 token分配 精度-延迟权衡
📋 核心要点
- 现有LLM服务器在处理异构任务时,缺乏对不同任务分配token数量的优化,导致精度和延迟难以兼顾。
- 论文提出队列感知的token分配优化方法,通过权衡精度和延迟,在满足队列稳定性的前提下,最大化整体性能。
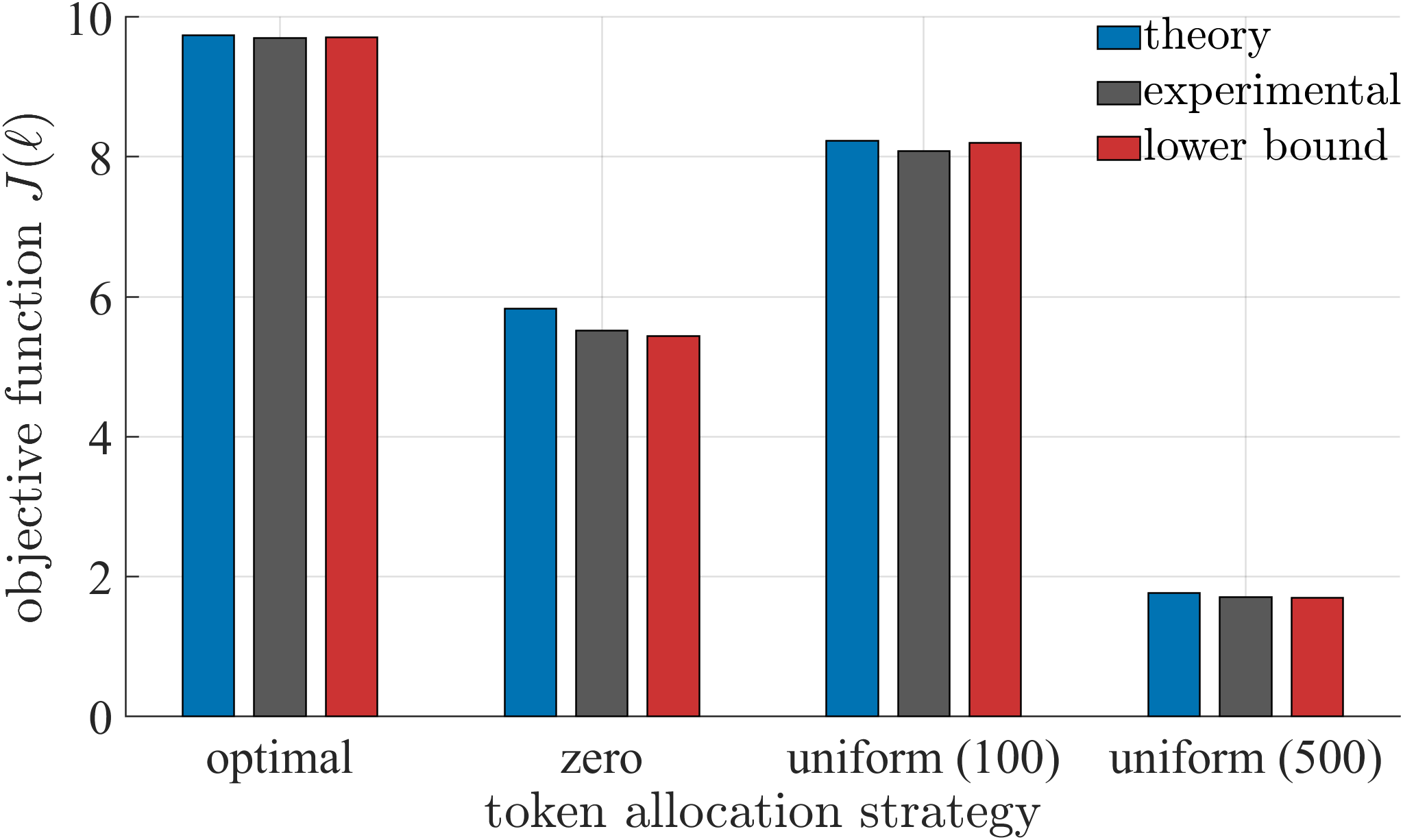
- 实验结果表明,该方法能够在token预算约束下,有效地提升LLM服务器的性能,实现精度和延迟的平衡。
📝 摘要(中文)
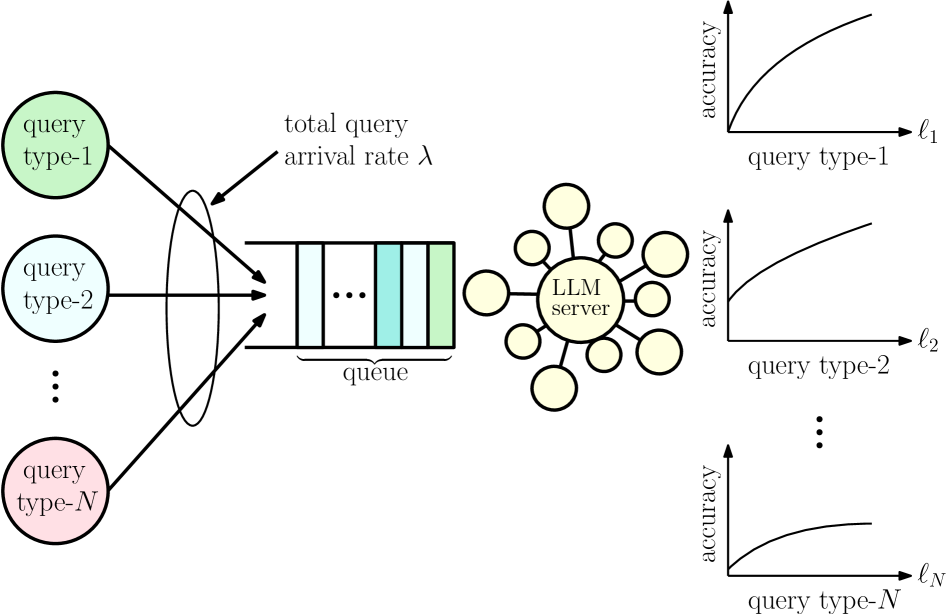
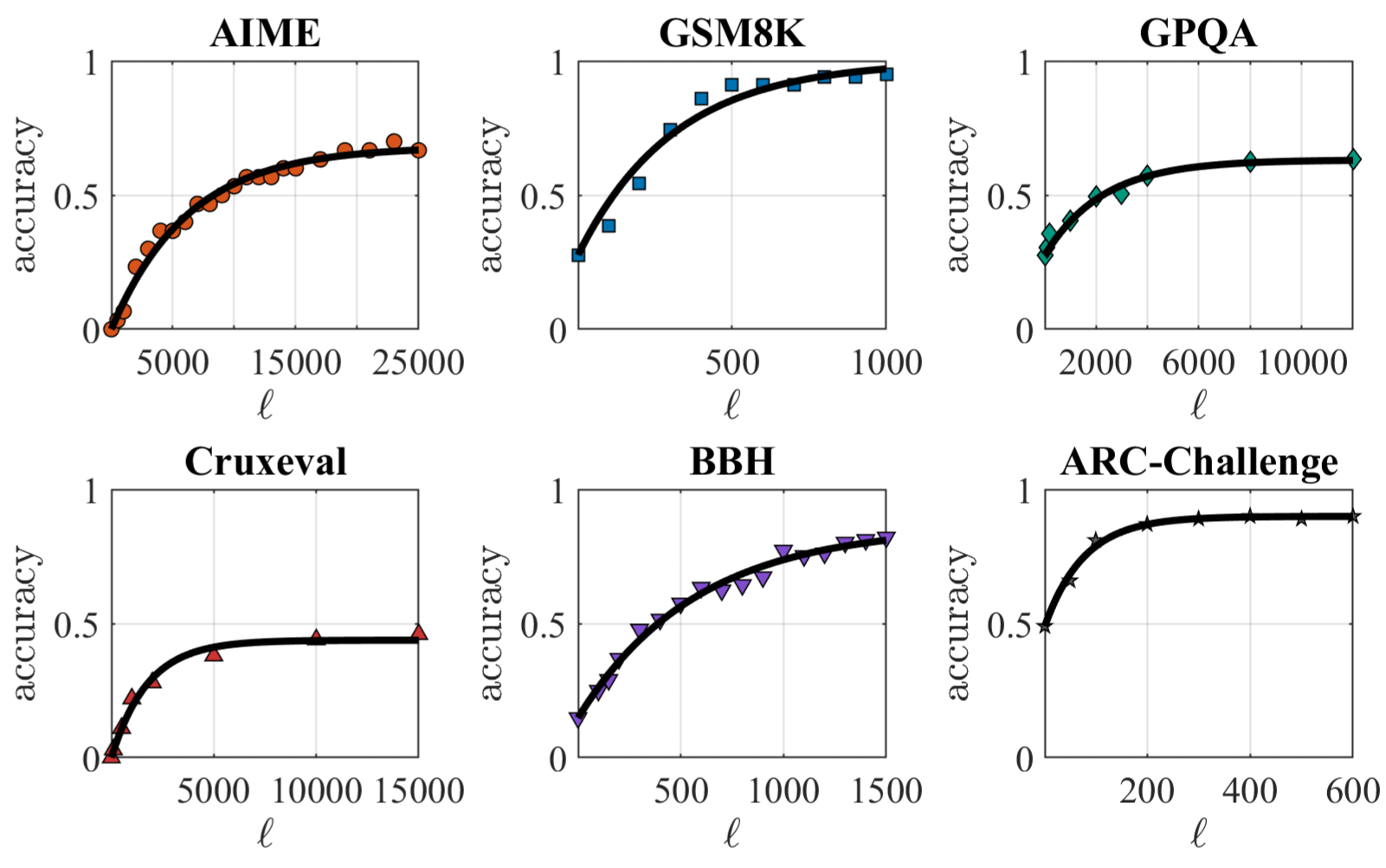
本文研究了一个服务于N种不同任务类型异构查询流的大型语言模型(LLM)服务器。查询按照泊松过程到达,每种类型以已知的先验概率出现。对于每种任务类型,服务器分配固定数量的内部思考token,这决定了对该查询的计算投入。token分配导致精度-延迟的权衡:服务时间近似地遵循分配token的仿射函数,而正确响应的概率表现出收益递减。在先进先出(FIFO)服务规则下,系统作为M/G/1队列运行,平均系统时间取决于所得服务时间分布的一阶和二阶矩。我们提出了一个约束优化问题,该问题最大化了受平均系统时间惩罚的加权平均精度目标,并受到架构token预算约束和队列稳定性条件的约束。目标函数被证明在稳定区域上是严格凹的,这确保了最优token分配的存在性和唯一性。一阶最优性条件产生了最优解的耦合投影不动点特征,以及迭代解和一个明确的收缩充分条件。此外,开发了一种具有可计算全局步长界的投影梯度法,以保证收敛超出收缩范围。最后,通过对连续解进行四舍五入来获得整数值token分配,并在仿真结果中评估由此产生的性能损失。
🔬 方法详解
问题定义:论文旨在解决LLM服务器在处理异构任务流时,如何根据任务类型动态分配推理token,以在精度和延迟之间取得最佳平衡的问题。现有方法通常采用静态的token分配策略,无法适应不同任务的需求,导致部分任务精度不足,而另一部分任务则可能过度计算,造成资源浪费和延迟增加。
核心思路:论文的核心思路是建立一个队列论模型,将LLM服务器视为一个M/G/1队列,并根据任务类型、token分配和服务时间之间的关系,建立一个优化问题。该优化问题旨在最大化加权平均精度,同时受到平均系统时间惩罚、token预算约束和队列稳定性条件的限制。通过求解该优化问题,可以得到针对不同任务类型的最优token分配策略。
技术框架:论文的技术框架主要包括以下几个部分:1) 建立LLM服务器的队列论模型,将系统建模为M/G/1队列;2) 定义任务类型、token分配、服务时间和精度之间的关系;3) 构建一个约束优化问题,目标是最大化加权平均精度,约束条件包括token预算和队列稳定性;4) 推导优化问题的一阶最优性条件,并提出迭代求解算法;5) 通过仿真实验验证所提出方法的有效性。
关键创新:论文的关键创新在于:1) 提出了一种队列感知的token分配优化方法,能够根据任务类型动态调整token数量,从而在精度和延迟之间取得平衡;2) 将LLM服务器建模为M/G/1队列,并利用队列论的理论分析系统性能;3) 证明了优化问题的目标函数在稳定区域上是严格凹的,保证了最优解的存在性和唯一性;4) 提出了一种具有可计算全局步长界的投影梯度法,保证了算法的收敛性。
关键设计:论文的关键设计包括:1) 服务时间建模为分配token的仿射函数;2) 正确响应的概率建模为token数量的递减收益函数;3) 优化问题的目标函数采用加权平均精度,并引入平均系统时间惩罚项;4) 队列稳定性条件采用经典的M/G/1队列稳定性条件,即到达率小于服务率。
🖼️ 关键图片
📊 实验亮点
论文通过仿真实验验证了所提出方法的有效性。实验结果表明,与静态token分配策略相比,该方法能够在满足队列稳定性条件的前提下,显著提高LLM服务器的加权平均精度,并降低平均系统时间。具体而言,在不同的任务类型和token预算下,该方法均能取得较好的性能提升。
🎯 应用场景
该研究成果可应用于各种在线LLM服务平台,例如智能客服、文本生成、代码补全等。通过优化token分配,可以提升用户体验,降低服务成本,并提高服务器的资源利用率。未来,该方法可以进一步扩展到更复杂的LLM服务场景,例如多GPU服务器、分布式推理等。
📄 摘要(原文)
We consider a single large language model (LLM) server that serves a heterogeneous stream of queries belonging to $N$ distinct task types. Queries arrive according to a Poisson process, and each type occurs with a known prior probability. For each task type, the server allocates a fixed number of internal thinking tokens, which determines the computational effort devoted to that query. The token allocation induces an accuracy-latency trade-off: the service time follows an approximately affine function of the allocated tokens, while the probability of a correct response exhibits diminishing returns. Under a first-in, first-out (FIFO) service discipline, the system operates as an $M/G/1$ queue, and the mean system time depends on the first and second moments of the resulting service-time distribution. We formulate a constrained optimization problem that maximizes a weighted average accuracy objective penalized by the mean system time, subject to architectural token-budget constraints and queue-stability conditions. The objective function is shown to be strictly concave over the stability region, which ensures existence and uniqueness of the optimal token allocation. The first-order optimality conditions yield a coupled projected fixed-point characterization of the optimum, together with an iterative solution and an explicit sufficient condition for contraction. Moreover, a projected gradient method with a computable global step-size bound is developed to guarantee convergence beyond the contractive regime. Finally, integer-valued token allocations are attained via rounding of the continuous solution, and the resulting performance loss is evaluated in simulation results.