PRL: Process Reward Learning Improves LLMs' Reasoning Ability and Broadens the Reasoning Boundary
作者: Jiarui Yao, Ruida Wang, Tong Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-15
💡 一句话要点
PRL:过程奖励学习提升LLM的推理能力并拓展推理边界
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 强化学习 过程奖励 推理能力 KL散度 策略梯度 过程监督
📋 核心要点
- 现有LLM推理能力提升方法主要依赖结果奖励,忽略了推理过程的细粒度监督。
- PRL方法将熵正则化强化学习目标分解为中间步骤,设计过程奖励以指导模型探索。
- 实验表明,PRL不仅提升了LLM的平均推理性能,还拓展了其推理边界。
📝 摘要(中文)
本文提出过程奖励学习(PRL)方法,旨在提升大型语言模型(LLM)的推理能力。现有方法主要基于轨迹级别的结果奖励,缺乏推理过程中的细粒度监督。其他结合过程信号的训练框架依赖于繁琐的额外步骤,如蒙特卡洛树搜索(MCTS)和单独的奖励模型训练,降低了训练效率,且过程信号设计的理论依据不足,优化机制不明确。PRL将熵正则化强化学习目标分解为中间步骤,并为模型分配严格的过程奖励。理论上,PRL等价于奖励最大化目标加上策略模型与参考模型之间的KL散度惩罚项。PRL将结果奖励转化为过程监督信号,更好地指导强化学习优化过程中的探索。实验结果表明,PRL不仅提高了LLM推理能力的平均性能(average @ n),还通过提高pass @ n指标拓展了推理边界。大量实验验证了PRL的有效性和泛化性。
🔬 方法详解
问题定义:现有大型语言模型(LLM)的推理能力提升方法主要依赖于最终结果的奖励,缺乏对推理过程的细粒度监督。此外,一些尝试结合过程信号的方法存在训练效率低、理论依据不足等问题,导致优化机制不明确。因此,如何更有效地利用过程信息来提升LLM的推理能力是一个关键问题。
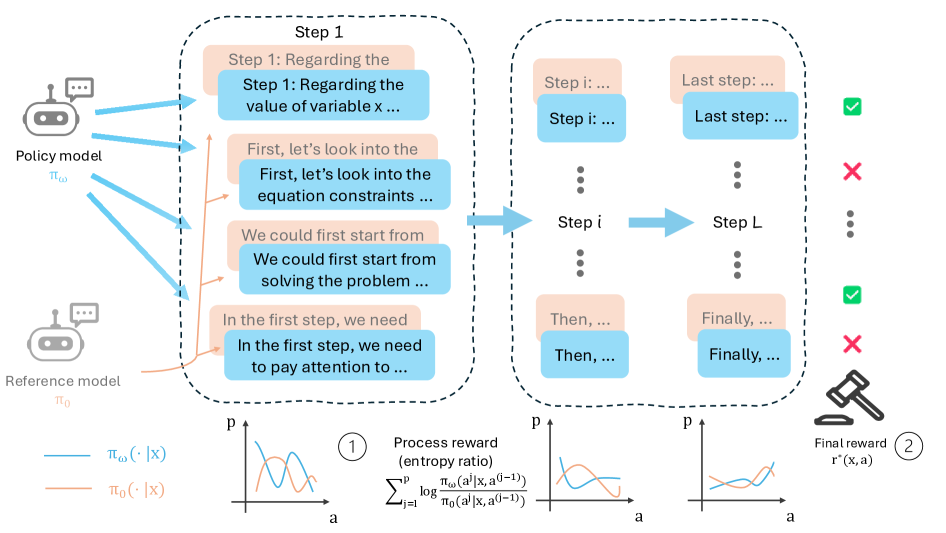
核心思路:PRL的核心思路是将熵正则化的强化学习目标分解为中间步骤,从而可以为模型的每个推理步骤分配过程奖励。这种分解使得可以将最终结果的奖励转化为对推理过程的监督信号,从而更好地指导模型在强化学习优化过程中的探索。同时,PRL在理论上等价于奖励最大化加上策略模型与参考模型之间的KL散度惩罚项,这为过程奖励的设计提供了理论依据。
技术框架:PRL的整体框架包括以下几个关键步骤:首先,将LLM的推理过程分解为多个中间步骤。然后,为每个步骤设计相应的过程奖励函数,这些奖励函数旨在鼓励模型朝着正确的推理方向前进。接下来,使用强化学习算法(例如,策略梯度算法)来优化LLM的策略,目标是最大化累积的过程奖励。在优化过程中,PRL还引入了一个KL散度惩罚项,以防止策略模型偏离参考模型过远。
关键创新:PRL最重要的创新在于将结果奖励转化为过程监督信号。与传统的只关注最终结果的奖励方法不同,PRL能够利用推理过程中的每一步信息来指导模型的学习,从而更有效地提升推理能力。此外,PRL的理论推导表明其等价于奖励最大化加上KL散度惩罚项,这为过程奖励的设计提供了理论支撑。
关键设计:PRL的关键设计包括以下几个方面:首先,过程奖励函数的设计需要根据具体的推理任务进行调整,以确保能够有效地指导模型的学习。其次,KL散度惩罚项的系数需要仔细调整,以平衡奖励最大化和策略稳定性之间的关系。此外,参考模型的选择也会影响PRL的性能,通常可以使用预训练的LLM作为参考模型。
🖼️ 关键图片
📊 实验亮点
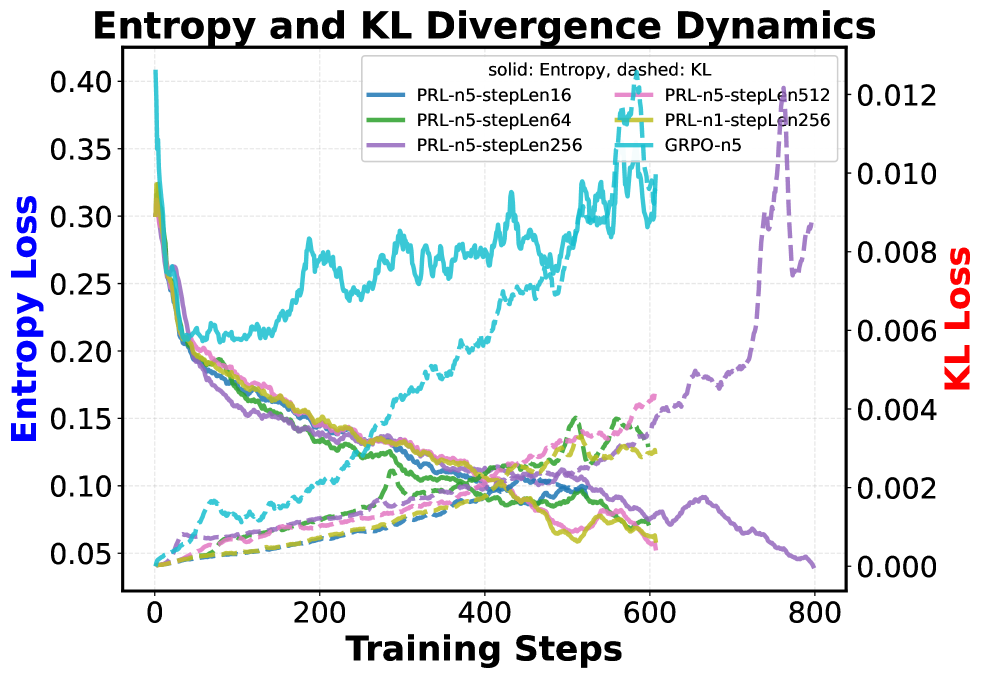
实验结果表明,PRL方法在多个推理任务上取得了显著的性能提升。例如,在某些任务上,PRL不仅提高了平均性能(average @ n),还通过提高pass @ n指标拓展了推理边界。与基线方法相比,PRL能够更有效地利用过程信息来指导模型的学习,从而获得更好的推理效果。这些实验结果验证了PRL的有效性和泛化性。
🎯 应用场景
PRL方法具有广泛的应用前景,可以应用于各种需要复杂推理能力的场景,例如问答系统、代码生成、数学问题求解等。通过提升LLM的推理能力,PRL可以帮助构建更智能、更可靠的人工智能系统,从而在教育、医疗、金融等领域发挥重要作用。未来,PRL还可以与其他技术相结合,例如知识图谱、符号推理等,进一步拓展LLM的应用范围。
📄 摘要(原文)
Improving the reasoning abilities of Large Language Models (LLMs) has been a continuous topic recently. But most relevant works are based on outcome rewards at the trajectory level, missing fine-grained supervision during the reasoning process. Other existing training frameworks that try to combine process signals together to optimize LLMs also rely heavily on tedious additional steps like MCTS, training a separate reward model, etc., doing harm to the training efficiency. Moreover, the intuition behind the process signals design lacks rigorous theoretical support, leaving the understanding of the optimization mechanism opaque. In this paper, we propose Process Reward Learning (PRL), which decomposes the entropy regularized reinforcement learning objective into intermediate steps, with rigorous process rewards that could be assigned to models accordingly. Starting from theoretical motivation, we derive the formulation of PRL that is essentially equivalent to the objective of reward maximization plus a KL-divergence penalty term between the policy model and a reference model. However, PRL could turn the outcome reward into process supervision signals, which helps better guide the exploration during RL optimization. From our experiment results, we demonstrate that PRL not only improves the average performance for LLMs' reasoning ability measured by average @ n, but also broadens the reasoning boundary by improving the pass @ n metric. Extensive experiments show the effectiveness of PRL could be verified and generalized.