LOOKAT: Lookup-Optimized Key-Attention for Memory-Efficient Transformers
作者: Aryan Karmore
分类: cs.LG, cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出LOOKAT,通过查找优化的键注意力机制实现Transformer的内存高效压缩。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Transformer KV缓存压缩 乘积量化 注意力机制 边缘计算 语言模型 向量数据库
📋 核心要点
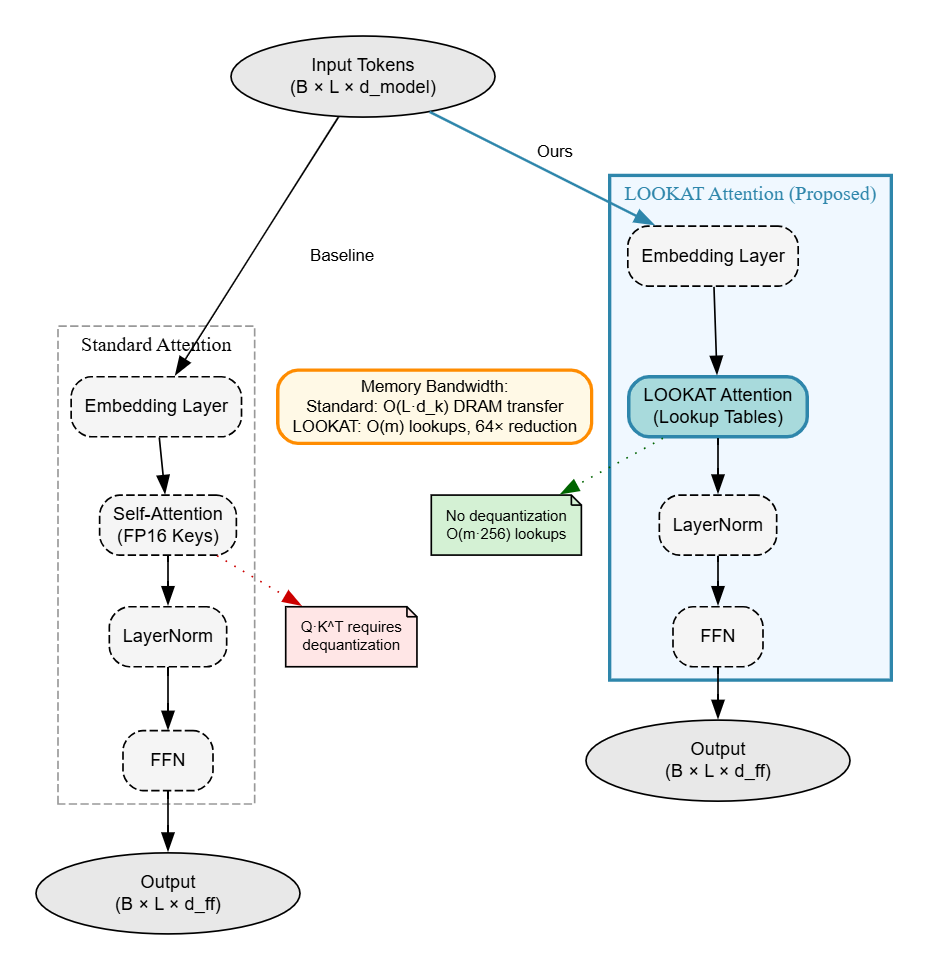
- 现有KV缓存压缩方法在注意力计算时需解量化,导致带宽瓶颈,限制了边缘设备部署。
- LOOKAT利用向量数据库的压缩技术,通过乘积量化和查找表将注意力计算转化为计算密集型。
- 实验表明,LOOKAT在保持高保真度下实现了显著的压缩率,且无需训练或修改架构。
📝 摘要(中文)
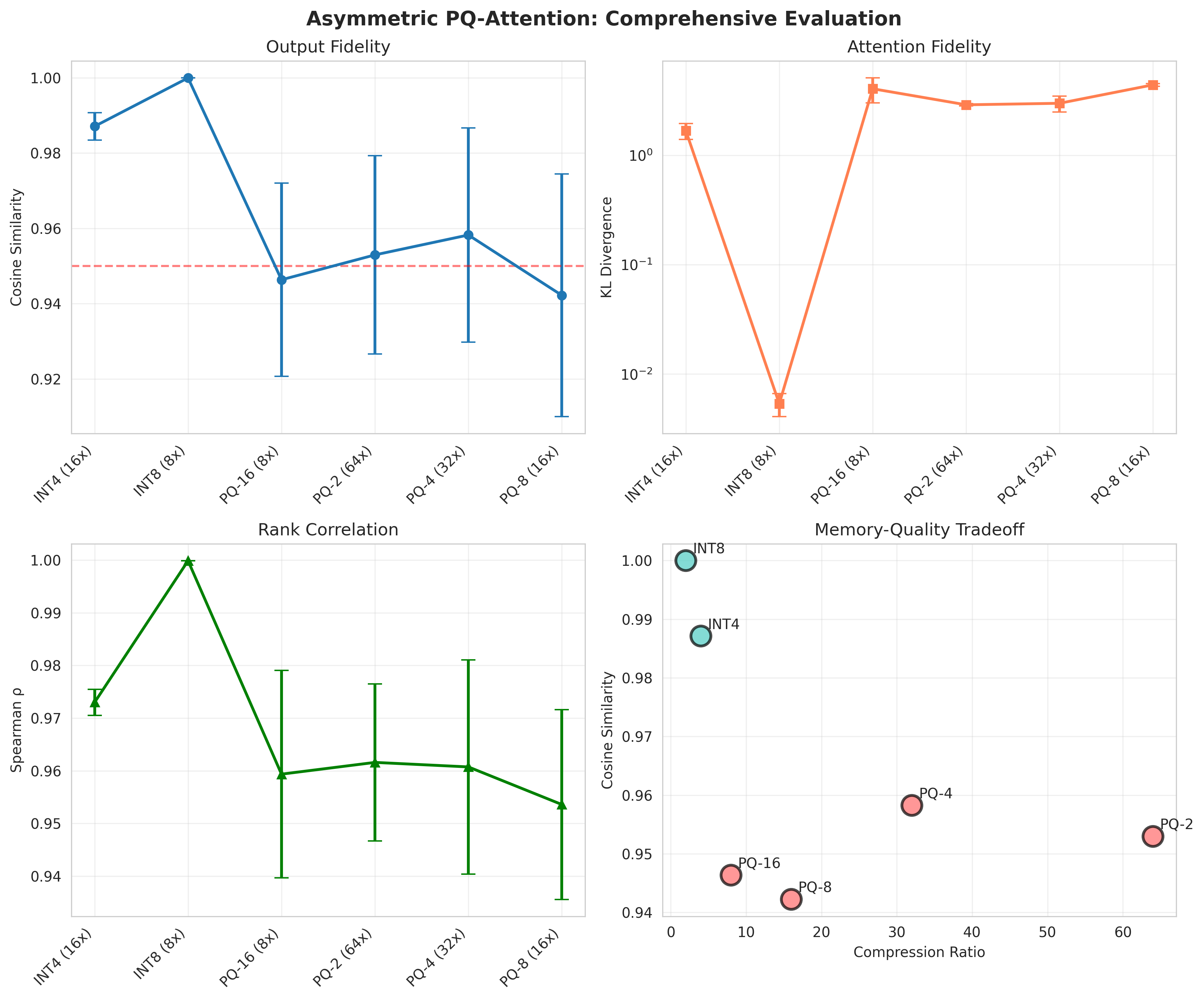
为了在边缘设备上部署大型语言模型,压缩KV缓存是必要步骤。现有的量化方法压缩了存储,但未能降低带宽,因为注意力计算需要将键从INT4/INT8解量化为FP16才能使用。我们观察到注意力评分在数学上等同于内积相似性搜索,因此可以应用向量数据库中的一些压缩技术来更好地压缩KV缓存。我们提出了LOOKAT,它通过将键向量分解为子空间、学习码本并通过查找表计算注意力表,从而将乘积量化和非对称距离计算应用于Transformer架构。这使得注意力计算从内存密集型转变为计算密集型。在GPT-2上测试时,LOOKAT在95.7%的输出保真度下实现了64倍压缩,在95.0%的保真度下实现了32倍压缩。LOOKAT无需架构更改或训练,同时保持秩相关性ρ>0.95。理论分析证实,秩相关性会随着O(dk/mK)而降低,并且保证在长达1024个token的序列长度上有效。
🔬 方法详解
问题定义:现有Transformer模型在边缘设备部署时,KV缓存占用大量内存,且现有压缩方法无法有效降低注意力计算所需的带宽,因为需要将压缩后的键向量解量化为高精度浮点数才能进行计算。这限制了大型语言模型在资源受限设备上的应用。
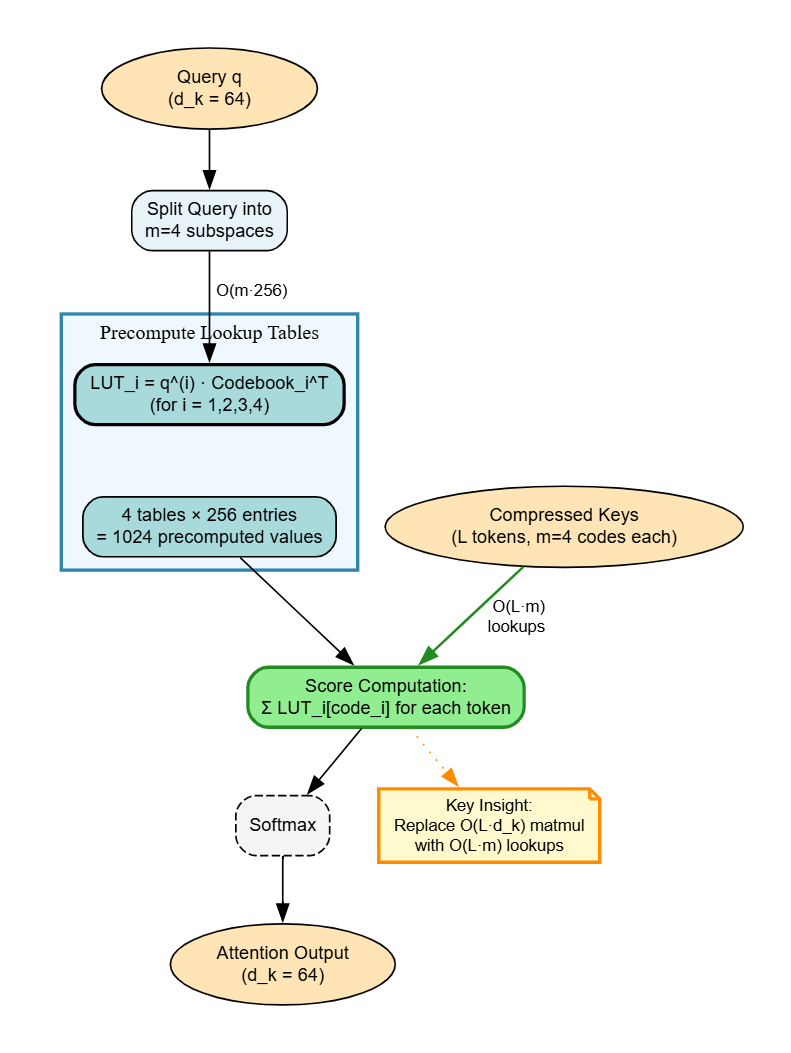
核心思路:论文的核心思路是将注意力计算等价于内积相似性搜索,并借鉴向量数据库中的压缩技术,特别是乘积量化(Product Quantization)和非对称距离计算(Asymmetric Distance Computation),来压缩KV缓存。通过将键向量分解为多个子空间,并为每个子空间学习码本,从而实现高效的压缩和相似度计算。
技术框架:LOOKAT方法主要包含以下几个阶段:1) 键向量分解:将键向量分解为多个子向量,每个子向量对应一个子空间。2) 码本学习:为每个子空间学习一个码本,码本中的每个码字代表该子空间中的一个聚类中心。3) 键向量量化:将每个键向量的子向量量化到其对应子空间的最近码字。4) 注意力表构建:使用量化后的键向量和值向量构建注意力查找表。5) 注意力计算:通过查找表进行注意力计算,避免了高精度浮点数运算。
关键创新:LOOKAT的关键创新在于将向量数据库的压缩技术应用于Transformer的注意力机制,实现了在不损失过多精度的情况下,显著降低KV缓存的内存占用和带宽需求。与传统的量化方法相比,LOOKAT避免了解量化步骤,直接在压缩域进行注意力计算,从而提高了效率。
关键设计:LOOKAT的关键设计包括:1) 子空间数量的选择:子空间数量决定了压缩率和精度之间的权衡。2) 码本大小的选择:码本大小影响量化误差。3) 非对称距离计算:使用非对称距离计算来近似原始的内积相似度,以减少计算复杂度。4) 查找表的设计:查找表存储了量化后的键向量和值向量之间的注意力权重,用于加速注意力计算。
🖼️ 关键图片
📊 实验亮点
LOOKAT在GPT-2模型上实现了显著的压缩效果,在95.7%的输出保真度下实现了64倍压缩,在95.0%的保真度下实现了32倍压缩。同时,LOOKAT保持了较高的秩相关性(ρ>0.95),表明其能够较好地保留原始注意力机制的排序能力。该方法无需架构更改或训练,易于集成到现有的Transformer模型中。
🎯 应用场景
LOOKAT技术可应用于边缘设备上大型语言模型的部署,例如智能手机、物联网设备和嵌入式系统。通过降低内存占用和带宽需求,LOOKAT使得这些设备能够运行更复杂的AI模型,从而实现更智能的本地化服务,例如离线翻译、语音识别和图像处理。此外,该技术还可以应用于云计算环境,以降低服务器的内存成本和提高推理效率。
📄 摘要(原文)
Compressing the KV cache is a required step to deploy large language models on edge devices. Current quantization methods compress storage but fail to reduce bandwidth as attention calculation requires dequantizing keys from INT4/INT8 to FP16 before use. We observe that attention scoring is mathematically equivalent to the inner product similarity search and we can apply some compression techniques from vector databases to compress KV-cache better. We propose LOOKAT, which applies product quantization and asymmetric distance computation, to transformer architecture by decomposing key vectors into subspaces, learning codebooks and computing attention tables via lookup tables. This transforms attention from memory-bound to compute-bound. LOOKAT achieves 64 $\times$ compression at 95.7\% output fidelity and 32 $\times$ compression at 95.0\% fidelity when tested on GPT-2. LOOKAT requires no architecture changes or training while maintaining rank correlation $ρ> 0.95$. Theoretical analysis confirms that rank correlation degrades as $O(d_k/mK)$, with guarantees validated across sequence lengths up to 1024 tokens.