Understanding and Preserving Safety in Fine-Tuned LLMs
作者: Jiawen Zhang, Yangfan Hu, Kejia Chen, Lipeng He, Jiachen Ma, Jian Lou, Dan Li, Jian Liu, Xiaohu Yang, Ruoxi Jia
分类: cs.LG, cs.AI
发布日期: 2026-01-15
💡 一句话要点
提出SPF安全保持微调方法,解决LLM微调中安全性和效用性冲突问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 微调 安全性 梯度修正 低秩子空间
📋 核心要点
- 现有LLM微调方法在提升下游任务性能的同时,往往会牺牲模型的安全性,容易受到越狱攻击。
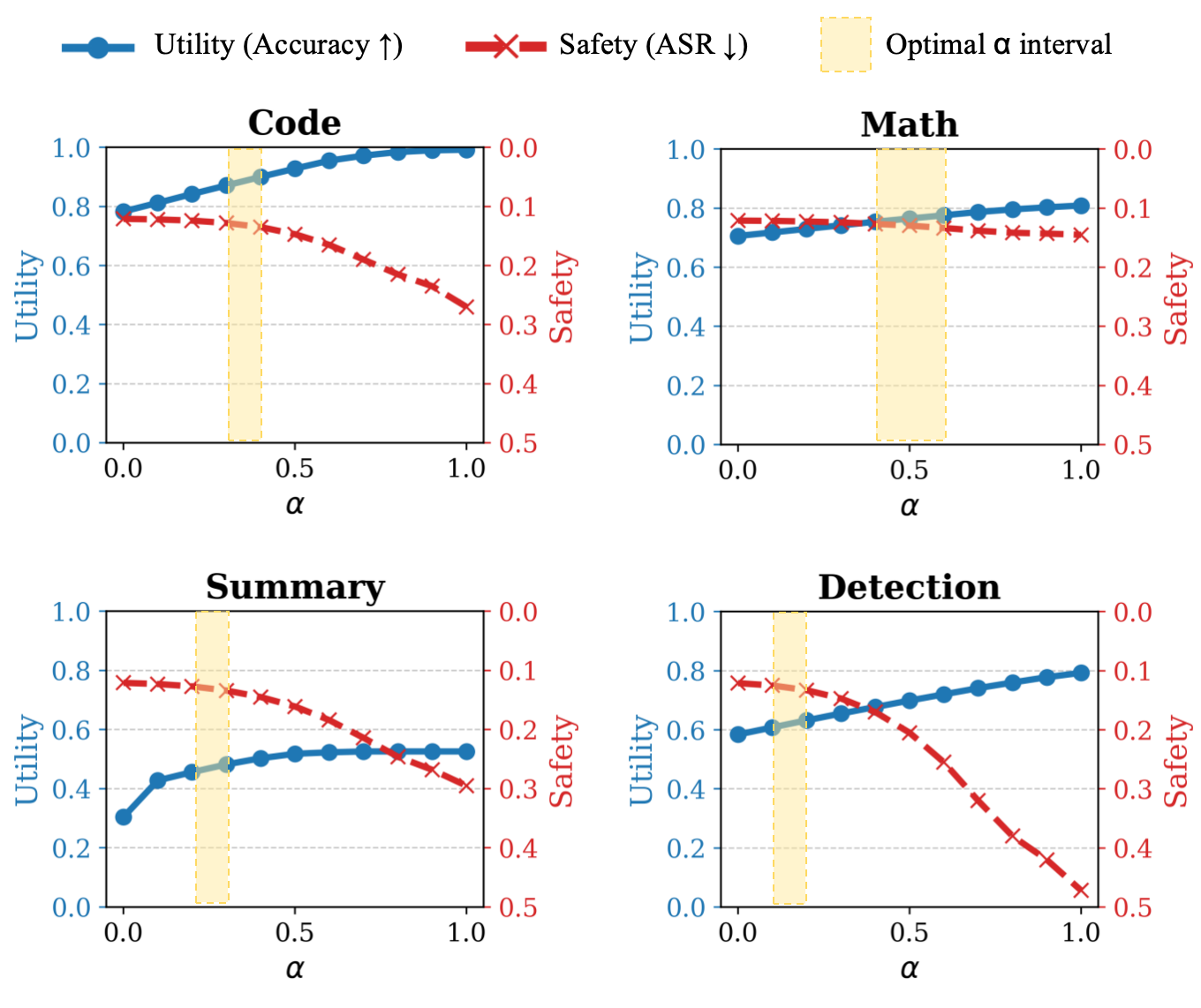
- 论文提出安全保持微调(SPF)方法,通过移除与低秩安全子空间冲突的梯度分量,显式地保留安全性。
- 实验表明,SPF在保持下游任务性能的同时,能够有效抵抗越狱攻击,恢复预训练模型的安全对齐。
📝 摘要(中文)
微调是将大型语言模型(LLM)应用于下游任务的关键功能。然而,即使微调数据完全无害,微调也可能显著降低安全对齐,例如,大幅增加对越狱攻击的敏感性。尽管在微调阶段的防御工作越来越受到关注,但现有方法仍然面临着持续存在的安全-效用困境:强调安全性会损害任务性能,而优先考虑效用通常需要深度微调,这不可避免地导致安全性的急剧下降。本文通过揭示安全对齐LLM中安全导向梯度和效用导向梯度之间的几何交互,来解决这一困境。通过系统的实证分析,我们发现了三个关键见解:(I)安全梯度位于低秩子空间中,而效用梯度跨越更广泛的高维空间;(II)这些子空间通常负相关,导致微调期间的方向冲突;(III)可以从单个样本中有效地估计主导安全方向。基于这些新颖的见解,我们提出了一种安全保持微调(SPF)方法,该方法显式地移除与低秩安全子空间冲突的梯度分量。从理论上讲,我们证明了SPF保证了效用收敛,同时限制了安全漂移。在实验上,即使在对抗性微调场景下,SPF也能始终如一地保持下游任务性能,并恢复几乎所有预训练的安全对齐。此外,SPF对深度微调和动态越狱攻击表现出强大的抵抗力。总之,我们的发现为始终对齐的LLM微调提供了新的机制理解和实践指导。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)微调方法在追求下游任务性能时,往往会降低模型的安全性,使其更容易受到对抗性攻击(如越狱攻击)。这种安全性和效用性之间的权衡是当前方法面临的主要痛点。即使使用无害的数据进行微调,也可能导致模型安全对齐的显著退化。
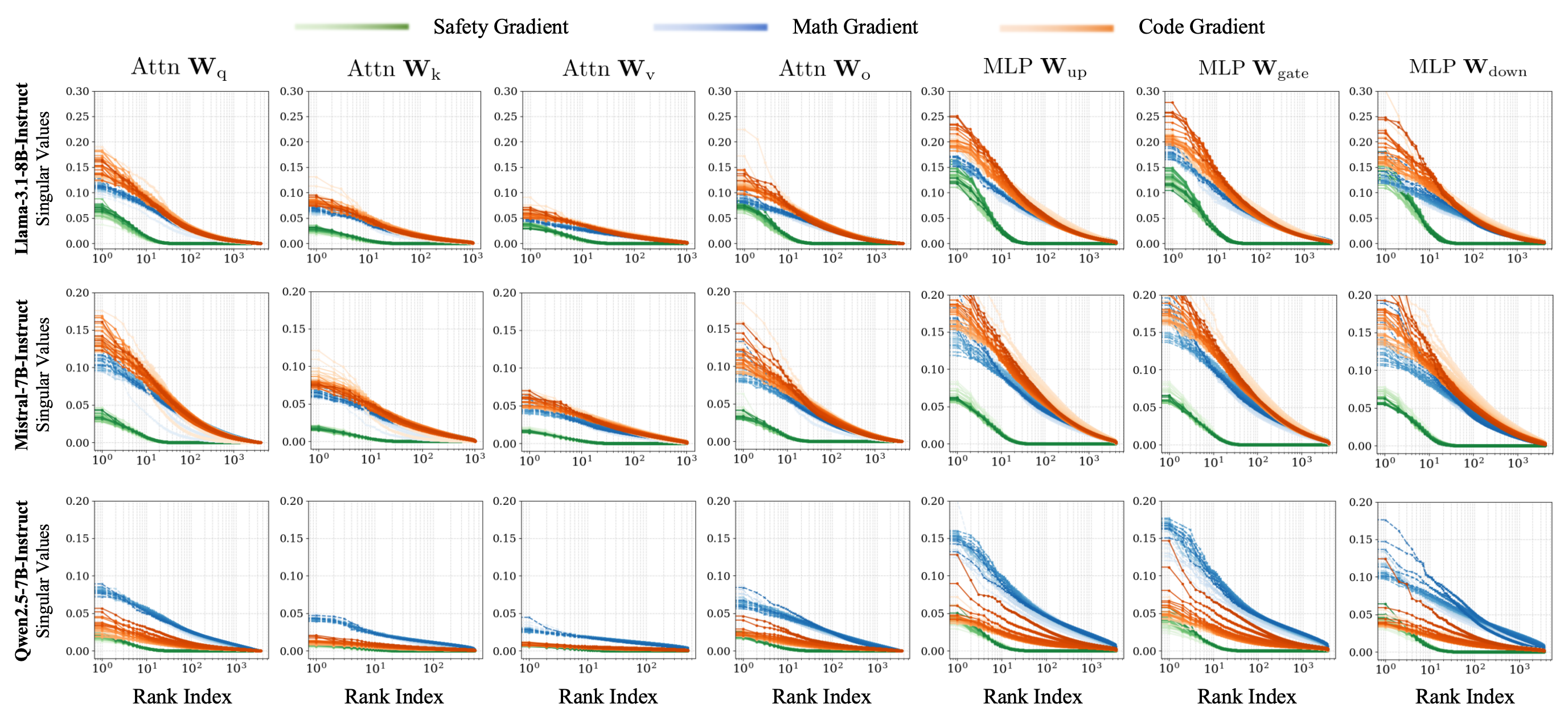
核心思路:论文的核心思路是观察到安全相关的梯度位于一个低秩子空间中,而效用相关的梯度则分布在更广阔的高维空间中。通过识别并移除微调过程中与安全子空间冲突的梯度分量,可以在不显著影响效用的前提下,有效地保留模型的安全性。这种方法基于对安全和效用梯度几何关系的深刻理解。
技术框架:SPF(Safety-Preserving Fine-tuning)方法的整体框架如下:1. 安全子空间估计:使用少量样本估计LLM的安全子空间。2. 梯度分解:在微调过程中,将梯度分解为与安全子空间平行和垂直的两个分量。3. 梯度修正:移除与安全子空间冲突的梯度分量,只保留与安全子空间正交的分量用于更新模型参数。4. 模型更新:使用修正后的梯度更新模型参数。
关键创新:该方法最重要的创新点在于发现了安全梯度位于低秩子空间这一现象,并利用这一特性来设计安全保持的微调策略。与现有方法相比,SPF不需要额外的安全数据或复杂的对抗训练,而是通过简单的梯度修正来实现安全性和效用性的平衡。
关键设计:关键设计包括:1. 低秩安全子空间的有效估计:论文提出了一种从单个样本中有效估计主导安全方向的方法。2. 梯度冲突的量化与消除:通过计算梯度与安全子空间之间的投影,精确地移除冲突的梯度分量。3. 轻量级实现:SPF方法计算复杂度低,易于集成到现有的微调流程中。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SPF方法在保持下游任务性能的同时,能够显著提高LLM的安全性,使其对越狱攻击的抵抗能力接近预训练模型。即使在对抗性微调场景下,SPF也能有效恢复模型的安全对齐。此外,SPF对深度微调和动态越狱攻击表现出强大的鲁棒性,证明了其在实际应用中的价值。
🎯 应用场景
该研究成果可广泛应用于各种需要对LLM进行微调的场景,例如智能客服、内容生成、教育辅导等。通过SPF方法,可以在保证模型在特定任务上表现良好的同时,有效防止模型生成有害、不安全或不符合伦理规范的内容,从而提高LLM在实际应用中的可靠性和安全性。
📄 摘要(原文)
Fine-tuning is an essential and pervasive functionality for applying large language models (LLMs) to downstream tasks. However, it has the potential to substantially degrade safety alignment, e.g., by greatly increasing susceptibility to jailbreak attacks, even when the fine-tuning data is entirely harmless. Despite garnering growing attention in defense efforts during the fine-tuning stage, existing methods struggle with a persistent safety-utility dilemma: emphasizing safety compromises task performance, whereas prioritizing utility typically requires deep fine-tuning that inevitably leads to steep safety declination. In this work, we address this dilemma by shedding new light on the geometric interaction between safety- and utility-oriented gradients in safety-aligned LLMs. Through systematic empirical analysis, we uncover three key insights: (I) safety gradients lie in a low-rank subspace, while utility gradients span a broader high-dimensional space; (II) these subspaces are often negatively correlated, causing directional conflicts during fine-tuning; and (III) the dominant safety direction can be efficiently estimated from a single sample. Building upon these novel insights, we propose safety-preserving fine-tuning (SPF), a lightweight approach that explicitly removes gradient components conflicting with the low-rank safety subspace. Theoretically, we show that SPF guarantees utility convergence while bounding safety drift. Empirically, SPF consistently maintains downstream task performance and recovers nearly all pre-trained safety alignment, even under adversarial fine-tuning scenarios. Furthermore, SPF exhibits robust resistance to both deep fine-tuning and dynamic jailbreak attacks. Together, our findings provide new mechanistic understanding and practical guidance toward always-aligned LLM fine-tuning.