Multilingual-To-Multimodal (M2M): Unlocking New Languages with Monolingual Text
作者: Piyush Singh Pasi
分类: cs.LG
发布日期: 2026-01-15
备注: EACL 2026 Findings accepted. Initial Draft of Camera-ready
🔗 代码/项目: GITHUB | HUGGINGFACE
💡 一句话要点
提出METAL,利用单语文本解锁多语言到多模态的零样本迁移能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言学习 多模态学习 零样本迁移 跨语言检索 文本图像检索
📋 核心要点
- 多模态模型在非英语语种上性能不佳,主要原因是缺乏足够的多语言多模态数据。
- METAL方法利用少量线性层,将多语言文本嵌入对齐到多模态空间,实现零样本迁移。
- 实验表明,METAL在跨语言图像-文本检索上取得了显著的零样本迁移效果,并可推广到其他任务。
📝 摘要(中文)
多模态模型在英语上表现出色,这得益于丰富的图像-文本和音频-文本数据,但由于多语言多模态资源的限制,其在其他语言上的性能急剧下降。现有的解决方案严重依赖机器翻译,而多语言文本建模的进展尚未得到充分利用。我们提出METAL,一种轻量级的对齐方法,它仅使用英语文本学习几个线性层,将多语言文本嵌入映射到多模态空间。尽管其简单性,METAL在英语上匹配了基线的性能(Recall@10为94.9%),并在XTD文本到图像检索上实现了强大的零样本迁移(在11种语言上平均Recall@10为89.5%,其中10种是未见过的)。定性的t-SNE可视化表明,多语言嵌入与多模态表示紧密对齐,而权重分析表明,该转换重塑了嵌入几何形状,而不是执行简单的旋转。除了图像-文本检索,METAL还推广到音频-文本检索和跨语言文本到图像生成。我们发布了代码和检查点,以及多语言评估数据集,以促进进一步的研究。
🔬 方法详解
问题定义:论文旨在解决多语言多模态学习中,由于非英语语种数据匮乏导致模型性能下降的问题。现有方法通常依赖机器翻译,但翻译质量会影响最终效果,且忽略了多语言文本建模的潜力。因此,如何在缺乏多语言多模态数据的情况下,实现多语言到多模态的有效迁移是一个关键挑战。
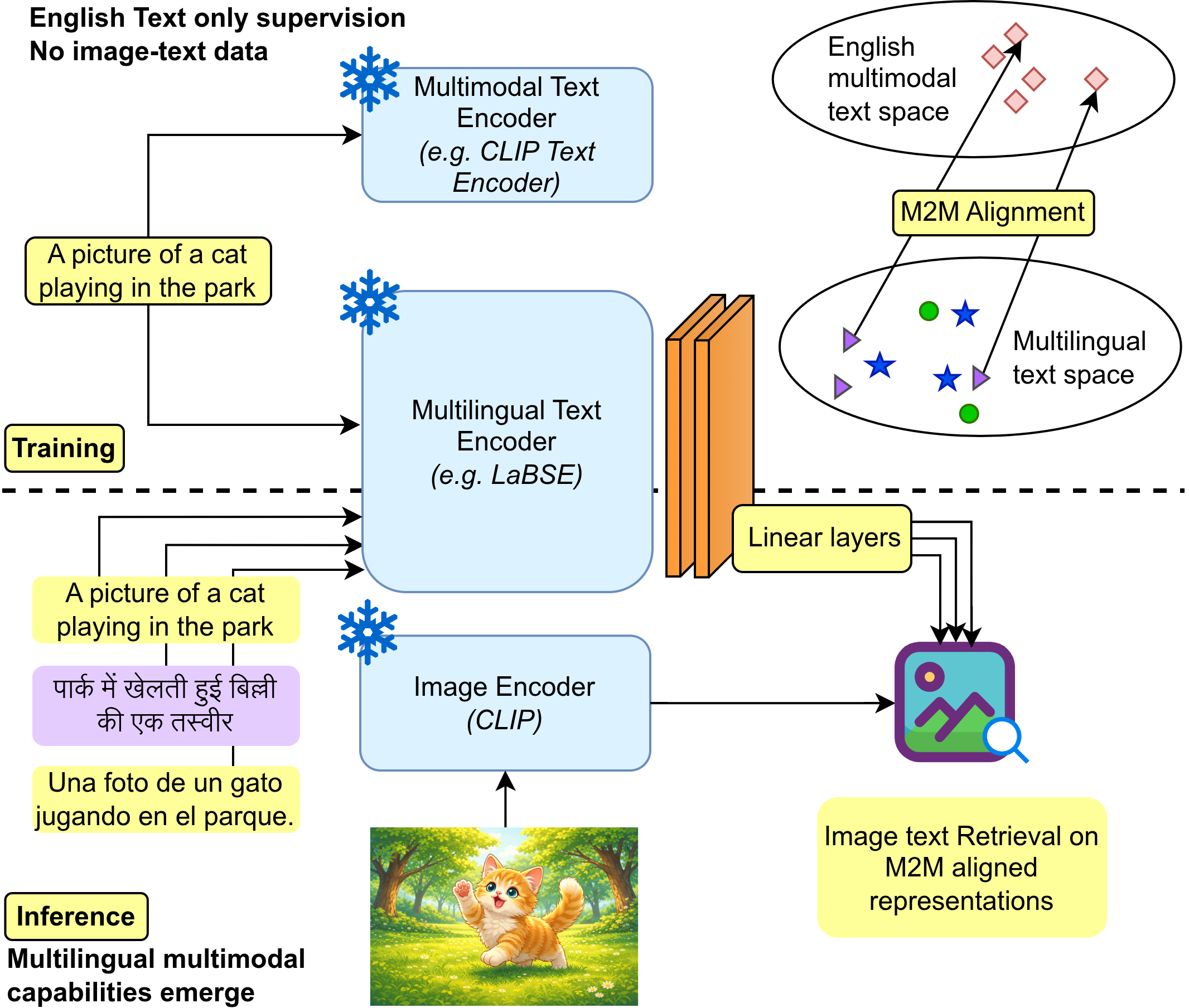
核心思路:论文的核心思路是利用英语的多模态数据作为桥梁,学习一个轻量级的映射,将多语言文本嵌入空间对齐到英语的多模态空间。这样,即使没有目标语言的多模态数据,也能实现零样本的多模态任务。这种方法避免了对机器翻译的依赖,并充分利用了多语言文本嵌入的语义信息。
技术框架:METAL方法的整体框架包括以下几个步骤:1) 使用预训练的多语言文本模型(如mBERT, XLM-R)提取多语言文本的嵌入表示。2) 使用英语文本及其对应的多模态数据(图像或音频)训练一个线性映射,将英语文本嵌入映射到多模态空间。3) 将训练好的线性映射应用于其他语言的文本嵌入,从而将这些嵌入也映射到多模态空间。4) 在多模态空间中,可以进行跨语言的检索、生成等任务。
关键创新:METAL的关键创新在于其轻量级的对齐方法。它只学习几个线性层,避免了复杂的非线性变换,从而降低了过拟合的风险,并提高了泛化能力。此外,METAL直接在嵌入空间进行对齐,避免了对原始文本或多模态数据的修改,从而保持了数据的原始语义信息。
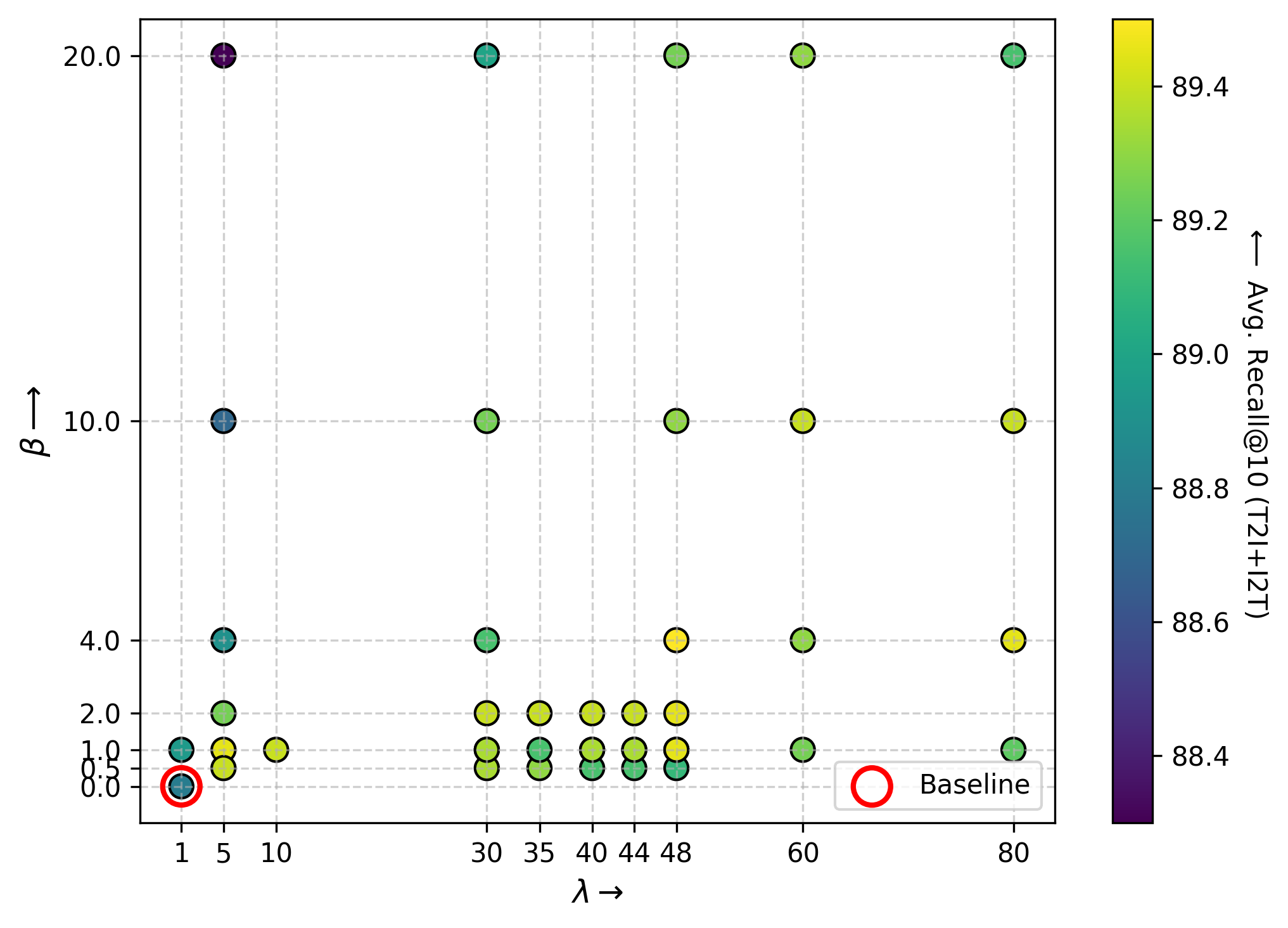
关键设计:METAL的关键设计包括:1) 使用预训练的多语言文本模型,以获得高质量的文本嵌入。2) 使用简单的线性层作为映射函数,以降低模型的复杂度。3) 使用余弦相似度作为损失函数,以衡量文本嵌入和多模态表示之间的相似度。4) 通过实验选择合适的线性层数量和学习率等超参数。
🖼️ 关键图片
📊 实验亮点
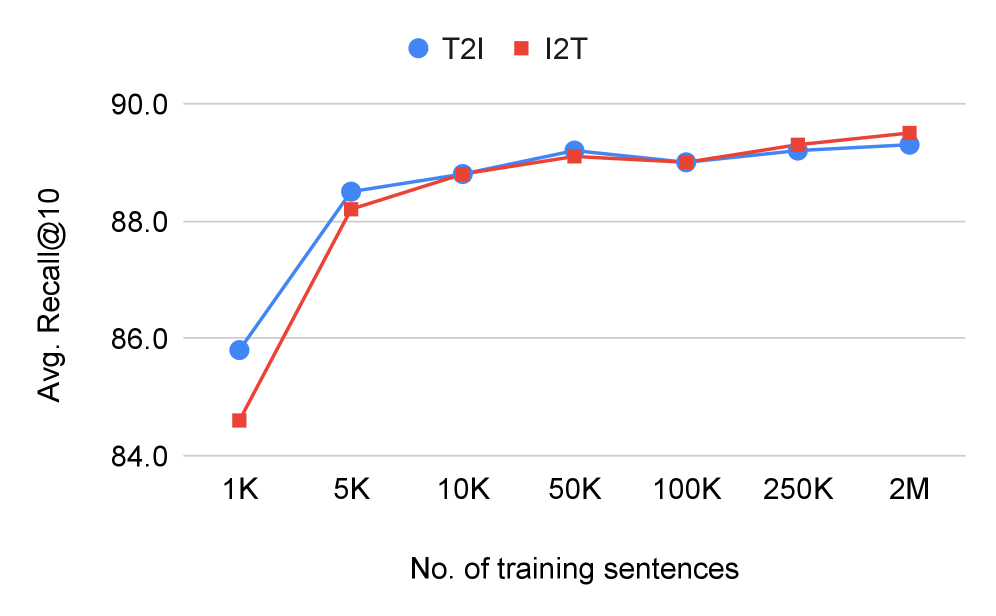
METAL在XTD文本到图像检索任务上取得了显著的零样本迁移效果,在11种语言上平均Recall@10达到89.5%,其中10种是未见过的语言。在英语上,METAL的性能与基线模型相当(Recall@10为94.9%)。此外,定性分析表明,METAL能够有效地将多语言嵌入与多模态表示对齐。
🎯 应用场景
该研究成果可广泛应用于跨语言信息检索、多语言图像/音频描述生成、以及多语言教育等领域。例如,用户可以使用任何语言的文本来搜索图像或音频,或者生成其他语言的图像/音频描述。该技术有助于打破语言障碍,促进全球范围内的信息共享和文化交流。
📄 摘要(原文)
Multimodal models excel in English, supported by abundant image-text and audio-text data, but performance drops sharply for other languages due to limited multilingual multimodal resources. Existing solutions rely heavily on machine translation, while advances in multilingual text modeling remain underutilized. We introduce METAL, a lightweight alignment method that learns only a few linear layers using English text alone to map multilingual text embeddings into a multimodal space. Despite its simplicity, METAL matches baseline performance in English (94.9 percent Recall at 10) and achieves strong zero-shot transfer (89.5 percent Recall at 10 averaged across 11 languages, 10 unseen) on XTD text-to-image retrieval. Qualitative t-SNE visualizations show that multilingual embeddings align tightly with multimodal representations, while weight analysis reveals that the transformation reshapes embedding geometry rather than performing trivial rotations. Beyond image-text retrieval, METAL generalizes to audio-text retrieval and cross-lingual text-to-image generation. We release code and checkpoints at https://github.com/m2m-codebase/M2M , as well as multilingual evaluation datasets including MSCOCO Multilingual 30K (https://huggingface.co/datasets/piyushsinghpasi/mscoco-multilingual-30k ), AudioCaps Multilingual (https://huggingface.co/datasets/piyushsinghpasi/audiocaps-multilingual ), and Clotho Multilingual (https://huggingface.co/datasets/piyushsinghpasi/clotho-multilingual ), to facilitate further research.