Sparse-RL: Breaking the Memory Wall in LLM Reinforcement Learning via Stable Sparse Rollouts
作者: Sijia Luo, Xiaokang Zhang, Yuxuan Hu, Bohan Zhang, Ke Wang, Jinbo Su, Mengshu Sun, Lei Liang, Jing Zhang
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-01-15
💡 一句话要点
Sparse-RL:通过稳定稀疏Rollout打破LLM强化学习中的内存墙
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 稀疏训练 KV缓存压缩 策略优化
📋 核心要点
- LLM强化学习中,长时程rollout带来的KV缓存内存开销是训练瓶颈,现有KV压缩方法直接应用于RL训练会造成策略不匹配,导致性能下降。
- Sparse-RL通过稀疏rollout实现稳定RL训练,核心思想是解决密集旧策略、稀疏采样器策略和学习器策略之间的策略不匹配问题。
- Sparse-RL通过稀疏感知拒绝采样和基于重要性的重加权来纠正压缩引起的信息丢失,实验表明降低了rollout开销,同时保持了性能,并提高了模型鲁棒性。
📝 摘要(中文)
强化学习(RL)对于激发大型语言模型(LLM)中复杂的推理能力至关重要。然而,在长时程rollout期间存储Key-Value(KV)缓存所带来的巨大内存开销构成了一个关键瓶颈,通常会限制在有限硬件上的高效训练。虽然现有的KV压缩技术为推理提供了补救措施,但直接将它们应用于RL训练会导致严重的策略不匹配,从而导致灾难性的性能崩溃。为了解决这个问题,我们引入了Sparse-RL,它支持在稀疏rollout下进行稳定的RL训练。我们表明,不稳定性源于密集旧策略、稀疏采样器策略和学习器策略之间根本的策略不匹配。为了缓解这个问题,Sparse-RL结合了稀疏感知拒绝采样和基于重要性的重加权,以纠正由压缩引起的信息丢失所带来的离策略偏差。实验结果表明,与密集基线相比,Sparse-RL降低了rollout开销,同时保持了性能。此外,Sparse-RL固有地实现了稀疏感知训练,从而显著提高了模型在稀疏推理部署期间的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)强化学习训练过程中,由于长时程rollout产生的巨大Key-Value (KV) 缓存内存开销问题。现有方法,如直接应用KV压缩技术,虽然能降低内存占用,但会导致策略不匹配,进而引起性能崩溃。这种策略不匹配体现在密集型的旧策略、稀疏型的采样策略以及学习策略三者之间。
核心思路:论文的核心思路是通过引入Sparse-RL框架,在稀疏rollout的条件下实现稳定的强化学习训练。Sparse-RL的核心在于解决由于KV缓存压缩导致的策略不匹配问题,从而保证在降低内存开销的同时,维持甚至提升模型性能。
技术框架:Sparse-RL框架主要包含以下几个关键模块:1) 稀疏采样器:用于生成稀疏的rollout轨迹,降低内存占用;2) 稀疏感知拒绝采样:用于缓解由于稀疏采样引入的偏差;3) 基于重要性的重加权:进一步校正离策略偏差,确保学习的稳定性。整体流程是,首先通过稀疏采样器生成rollout数据,然后利用稀疏感知拒绝采样和重要性重加权对数据进行修正,最后使用修正后的数据进行策略学习。
关键创新:Sparse-RL的关键创新在于其针对稀疏rollout场景下的策略不匹配问题,提出了稀疏感知拒绝采样和基于重要性的重加权两种技术。这两种技术能够有效地缓解由于KV缓存压缩和稀疏采样带来的信息损失和偏差,从而保证了在稀疏rollout条件下RL训练的稳定性。
关键设计:在稀疏感知拒绝采样中,需要设计合适的拒绝采样策略,以保证采样后的数据分布尽可能接近原始分布。在基于重要性的重加权中,需要精确估计重要性权重,以校正离策略偏差。具体的参数设置和损失函数设计需要根据具体的任务和模型进行调整,以达到最佳的性能。
🖼️ 关键图片
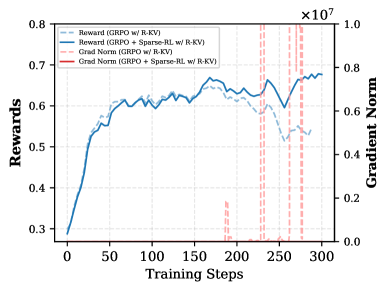
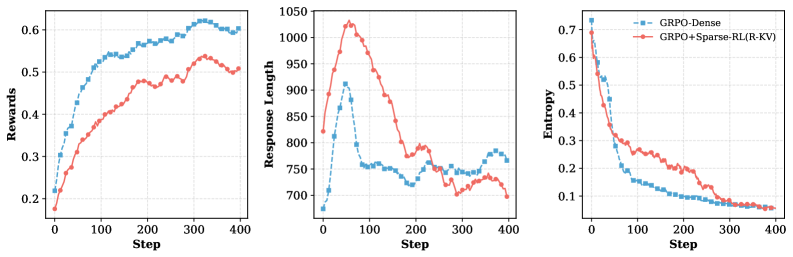
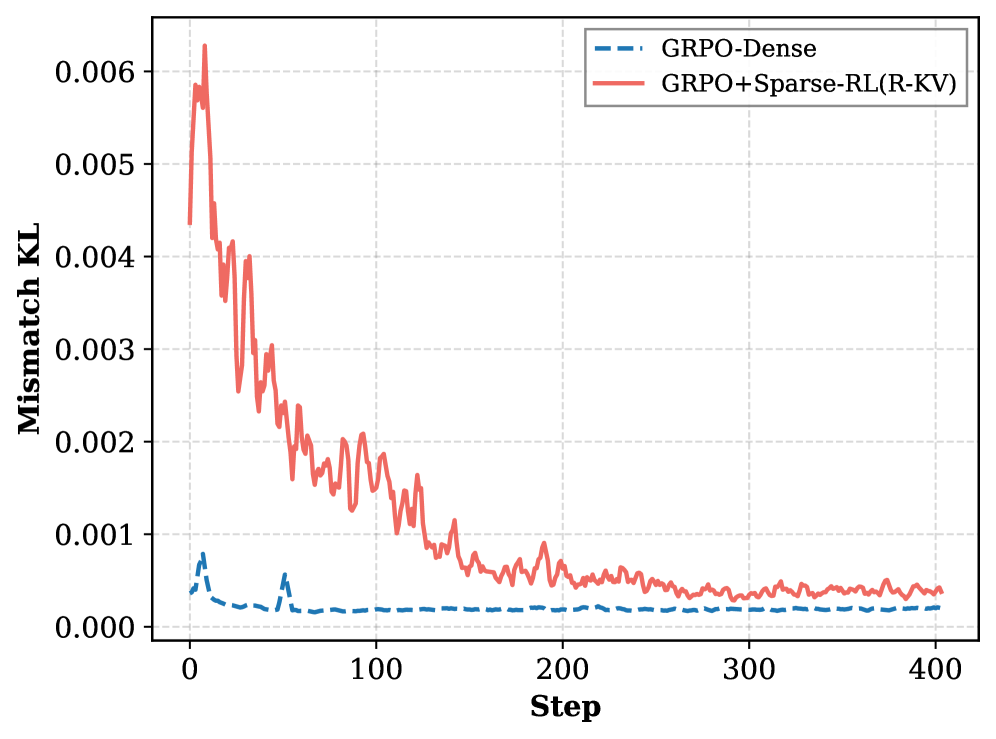
📊 实验亮点
Sparse-RL在降低rollout开销的同时,能够保持甚至提升模型性能。实验结果表明,Sparse-RL相较于密集基线,显著降低了内存占用,同时在多个任务上取得了与密集训练相当甚至更好的性能。此外,Sparse-RL还提高了模型在稀疏推理部署中的鲁棒性,验证了其在实际应用中的价值。
🎯 应用场景
Sparse-RL具有广泛的应用前景,尤其是在资源受限的场景下训练大型语言模型。例如,可以在边缘设备或低成本服务器上进行LLM的强化学习训练,加速LLM在机器人控制、对话系统、游戏AI等领域的部署和应用。此外,Sparse-RL的稀疏感知训练特性可以提高模型在稀疏推理环境下的鲁棒性,使其更适应实际应用场景。
📄 摘要(原文)
Reinforcement Learning (RL) has become essential for eliciting complex reasoning capabilities in Large Language Models (LLMs). However, the substantial memory overhead of storing Key-Value (KV) caches during long-horizon rollouts acts as a critical bottleneck, often prohibiting efficient training on limited hardware. While existing KV compression techniques offer a remedy for inference, directly applying them to RL training induces a severe policy mismatch, leading to catastrophic performance collapse. To address this, we introduce Sparse-RL empowers stable RL training under sparse rollouts. We show that instability arises from a fundamental policy mismatch among the dense old policy, the sparse sampler policy, and the learner policy. To mitigate this issue, Sparse-RL incorporates Sparsity-Aware Rejection Sampling and Importance-based Reweighting to correct the off-policy bias introduced by compression-induced information loss. Experimental results show that Sparse-RL reduces rollout overhead compared to dense baselines while preserving the performance. Furthermore, Sparse-RL inherently implements sparsity-aware training, significantly enhancing model robustness during sparse inference deployment.