CAFEDistill: Learning Personalized and Dynamic Models through Federated Early-Exit Network Distillation
作者: Boyi Liu, Zimu Zhou, Yongxin Tong
分类: cs.LG
发布日期: 2026-01-15
备注: 12 pages, conference
💡 一句话要点
提出CAFEDistill,通过联邦早期退出网络蒸馏学习个性化动态模型。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 个性化联邦学习 早期退出网络 知识蒸馏 模型压缩 自适应推理
📋 核心要点
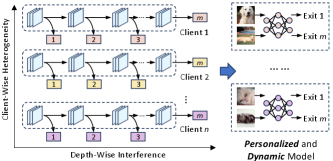
- 现有PFL方法生成的静态模型无法适应推理需求变化的环境,准确性和效率之间存在固定权衡。
- CAFEDistill通过冲突感知的联邦退出蒸馏,联合解决客户端异构性和深度干扰问题,扩展PFL到早期退出网络。
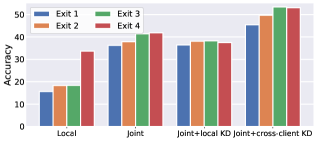
- 实验表明,CAFEDistill优于现有技术,实现了更高的准确性,并将推理成本降低了30.79%-46.86%。
📝 摘要(中文)
个性化联邦学习(PFL)支持在分散的异构数据上进行协同模型训练,同时根据每个客户端的独特分布进行定制。然而,现有的PFL方法产生的是静态模型,在准确性和效率之间存在固定的权衡,限制了它们在推理需求随环境和资源可用性变化的环境中的适用性。早期退出网络(EENs)通过附加中间分类器提供自适应推理。然而,由于客户端异构性和由冲突的退出目标引起的深度干扰,将它们集成到PFL中具有挑战性。先前的研究未能同时解决这两个冲突,导致次优性能。在本文中,我们提出了CAFEDistill,一个冲突感知的联邦退出蒸馏框架,它共同解决这些冲突并将PFL扩展到早期退出网络。通过渐进的、深度优先的学生协调机制,CAFEDistill减轻了浅层和深层退出之间的干扰,同时允许跨客户端的有效个性化知识转移。此外,它通过客户端解耦公式减少了通信开销。广泛的评估表明,CAFEDistill优于现有技术,实现了更高的准确性,并将推理成本降低了30.79%-46.86%。
🔬 方法详解
问题定义:现有的个性化联邦学习(PFL)方法通常生成静态模型,这些模型在准确性和效率之间存在固定的权衡。在推理需求随环境和资源可用性变化的应用场景中,这种静态模型无法提供最佳性能。此外,将早期退出网络(EENs)集成到PFL中面临客户端数据异构性和深度方向的干扰问题,即浅层和深层退出之间的目标冲突。
核心思路:CAFEDistill的核心思路是通过冲突感知的联邦退出蒸馏,同时解决客户端数据异构性和深度方向的干扰问题。它利用早期退出网络的自适应推理能力,并结合联邦学习的个性化建模能力,使得每个客户端都能根据自身的数据分布和推理需求,动态地选择合适的退出层进行推理,从而在准确性和效率之间取得更好的平衡。
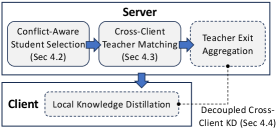
技术框架:CAFEDistill框架主要包含以下几个关键模块:1) 全局教师模型:一个在服务器端维护的全局早期退出网络,用于提供知识指导。2) 客户端学生模型:每个客户端维护一个个性化的早期退出网络,通过联邦学习和知识蒸馏进行训练。3) 深度优先的学生协调机制:通过渐进的方式,优先协调深层退出的知识转移,从而减轻浅层和深层退出之间的干扰。4) 客户端解耦公式:减少通信开销,提高训练效率。
关键创新:CAFEDistill的关键创新在于其冲突感知的联邦退出蒸馏方法。它通过深度优先的学生协调机制,有效地缓解了浅层和深层退出之间的干扰,使得每个客户端都能学习到个性化的早期退出策略。此外,客户端解耦公式进一步降低了通信开销,提高了训练效率。
关键设计:CAFEDistill的关键设计包括:1) 深度优先的学生协调机制:采用渐进式的知识蒸馏策略,从深层退出开始,逐步向浅层退出进行知识转移。2) 冲突感知损失函数:设计损失函数时,考虑了客户端数据异构性和深度方向的干扰,从而更好地平衡不同退出层之间的目标。3) 客户端解耦公式:通过将客户端的更新解耦,减少了通信开销,提高了训练效率。
🖼️ 关键图片
📊 实验亮点
CAFEDistill在多个数据集上进行了广泛的评估,实验结果表明,CAFEDistill在准确性方面优于现有的PFL方法,并且能够将推理成本降低30.79%-46.86%。这些结果验证了CAFEDistill在个性化联邦学习和早期退出网络结合方面的有效性。
🎯 应用场景
CAFEDistill适用于资源受限且推理需求动态变化的边缘计算场景,例如移动设备上的图像识别、自动驾驶中的目标检测、以及物联网设备上的传感器数据分析。该方法能够根据设备资源和任务需求,自适应地选择合适的模型复杂度,从而在保证精度的前提下,降低计算和通信开销,具有重要的实际应用价值。
📄 摘要(原文)
Personalized Federated Learning (PFL) enables collaboratively model training on decentralized, heterogeneous data while tailoring them to each client's unique distribution. However, existing PFL methods produce static models with a fixed tradeoff between accuracy and efficiency, limiting their applicability in environments where inference requirements vary with contexts and resource availability. Early-exit networks (EENs) offer adaptive inference by attaching intermediate classifiers. Yet integrating them into PFL is challenging due to client-wise heterogeneity and depth-wise interference arising from conflicting exit objectives. Prior studies fail to resolve both conflicts simultaneously, leading to suboptimal performance. In this paper, we propose CAFEDistill, a Conflict-Aware Federated Exit Distillation framework that jointly addresses these conflicts and extends PFL to early-exit networks. Through a progressive, depth-prioritized student coordination mechanism, CAFEDistill mitigates interference among shallow and deep exits while allowing effective personalized knowledge transfer across clients. Furthermore, it reduces communication overhead via a client-decoupled formulation. Extensive evaluations show that CAFEDistill outperforms the state-of-the-arts, achieving higher accuracy and reducing inference costs by 30.79%-46.86%.