FaTRQ: Tiered Residual Quantization for LLM Vector Search in Far-Memory-Aware ANNS Systems
作者: Tianqi Zhang, Flavio Ponzina, Tajana Rosing
分类: cs.LG, cs.AR, cs.IR
发布日期: 2026-01-15
💡 一句话要点
提出FaTRQ以解决ANNS系统中的存储与延迟问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 近似最近邻搜索 分层存储 残差量化 低延迟精炼 多模态嵌入 数据检索 机器学习优化
📋 核心要点
- 现有ANNS方法在处理现代文本和多模态嵌入时,读取全精度向量的延迟成为主要瓶颈。
- FaTRQ通过引入分层存储和渐进距离估计器,消除了从慢速存储读取全向量的需求,提升了精炼效率。
- 实验结果表明,FaTRQ在存储效率上提高了2.4倍,吞吐量提升最多可达9倍,显著优于现有技术。
📝 摘要(中文)
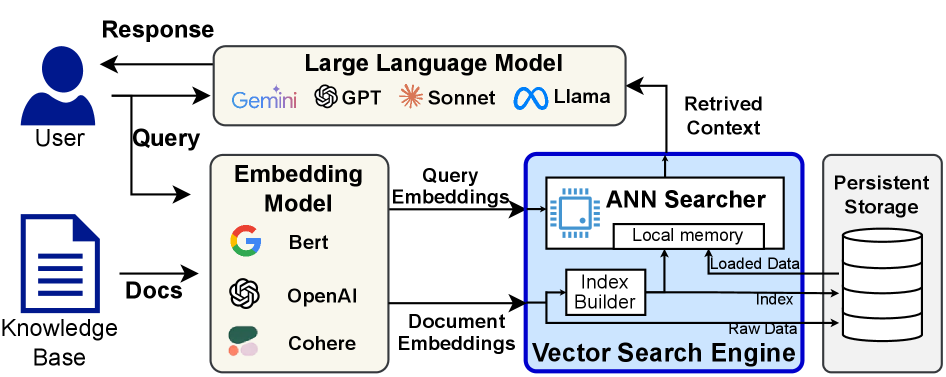
近似最近邻搜索(ANNS)是检索增强生成(RAG)中的关键技术,能够快速识别来自大规模向量数据库的相关高维嵌入。现代ANNS引擎通过预构建索引和存储压缩的向量量化表示来加速这一过程。然而,它们仍依赖于从较慢存储(如SSD)读取全精度向量的代价高昂的二次精炼阶段。为了解决这一问题,本文提出了FaTRQ,一个远存储感知的精炼系统,采用分层存储,消除了从存储中获取全向量的需求。该系统引入了一种渐进距离估计器,通过从远存储流式传输的紧凑残差来精炼粗略得分,并在候选者被证明不在前k名时提前停止精炼。我们还提出了分层残差量化,将残差编码为高效存储在远存储中的三元值。通过在CXL Type-2设备中部署定制加速器,本系统实现了低延迟的本地精炼。综合来看,FaTRQ在存储效率上提高了2.4倍,吞吐量比现有最先进的GPU ANNS系统提高了最多9倍。
🔬 方法详解
问题定义:本文旨在解决现代ANNS系统中,读取全精度向量导致的高延迟问题。现有方法依赖于从较慢存储中提取全向量,造成查询延迟显著增加。
核心思路:FaTRQ通过分层存储和渐进距离估计器来优化精炼过程,避免了不必要的全向量读取。该设计使得系统能够在候选者不在前k名时提前停止精炼,从而节省时间和资源。
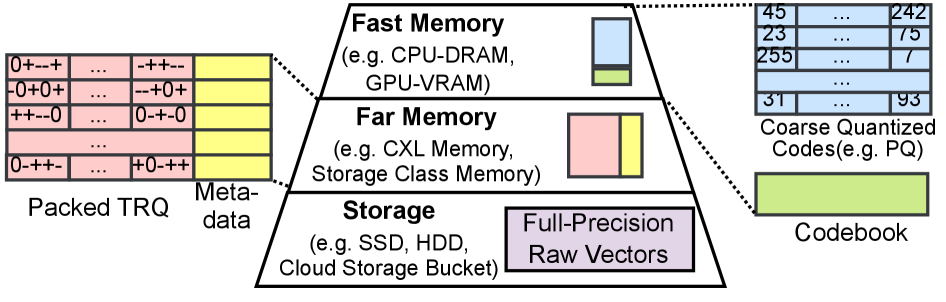
技术框架:FaTRQ的整体架构包括分层存储模块、渐进距离估计器和定制加速器。分层存储模块负责管理不同精度的向量存储,渐进距离估计器则用于实时评估候选者的相关性,定制加速器则在本地执行低延迟的精炼操作。
关键创新:FaTRQ的主要创新在于引入了分层残差量化技术,将残差编码为三元值并高效存储在远存储中。这一方法与传统的全向量读取方式形成鲜明对比,显著降低了存储需求和延迟。
关键设计:在设计中,FaTRQ采用了特定的参数设置以优化存储效率,并使用了适合的损失函数来指导残差的量化过程。网络结构方面,系统集成了高效的流式处理模块,以支持实时数据流的处理。
🖼️ 关键图片
📊 实验亮点
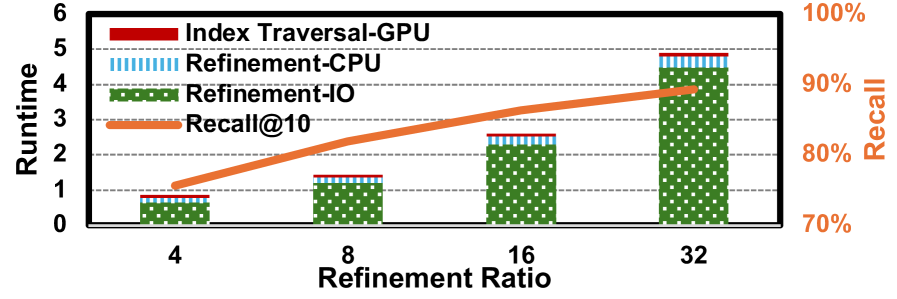
FaTRQ在实验中实现了2.4倍的存储效率提升,并在吞吐量上相比现有最先进的GPU ANNS系统提高了最多9倍。这些结果表明,FaTRQ在处理现代文本和多模态嵌入时,能够显著降低延迟并提升系统性能。
🎯 应用场景
FaTRQ的研究成果在大规模向量检索、推荐系统和智能搜索引擎等领域具有广泛的应用潜力。通过提升ANNS系统的存储效率和响应速度,该技术能够显著改善用户体验,并为实时数据处理提供支持。未来,FaTRQ有望在多模态数据处理和大规模机器学习任务中发挥重要作用。
📄 摘要(原文)
Approximate Nearest-Neighbor Search (ANNS) is a key technique in retrieval-augmented generation (RAG), enabling rapid identification of the most relevant high-dimensional embeddings from massive vector databases. Modern ANNS engines accelerate this process using prebuilt indexes and store compressed vector-quantized representations in fast memory. However, they still rely on a costly second-pass refinement stage that reads full-precision vectors from slower storage like SSDs. For modern text and multimodal embeddings, these reads now dominate the latency of the entire query. We propose FaTRQ, a far-memory-aware refinement system using tiered memory that eliminates the need to fetch full vectors from storage. It introduces a progressive distance estimator that refines coarse scores using compact residuals streamed from far memory. Refinement stops early once a candidate is provably outside the top-k. To support this, we propose tiered residual quantization, which encodes residuals as ternary values stored efficiently in far memory. A custom accelerator is deployed in a CXL Type-2 device to perform low-latency refinement locally. Together, FaTRQ improves the storage efficiency by 2.4$\times$ and improves the throughput by up to 9$ \times$ than SOTA GPU ANNS system.