SimMerge: Learning to Select Merge Operators from Similarity Signals
作者: Oliver Bolton, Aakanksha, Arash Ahmadian, Sara Hooker, Marzieh Fadaee, Beyza Ermis
分类: cs.LG, cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出SimMerge以优化大语言模型合并过程
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型合并 大语言模型 相似性信号 性能预测 多任务学习
📋 核心要点
- 现有的模型合并方法在选择合并操作符和合并顺序时,往往需要进行昂贵的合并评估搜索,效率低下。
- 本文提出SimMerge,一种基于任务无关相似性信号的预测合并选择方法,能够高效选择最佳合并操作符和模型子集。
- 实验结果显示,SimMerge在7B参数的2-way合并中表现优于标准方法,并且能够推广到更大规模的模型合并,且无需重新训练。
📝 摘要(中文)
模型合并使多个大型语言模型(LLMs)能够合并为一个单一模型,同时保持性能。这在LLM开发中是一个有价值的工具,提供了多任务训练的竞争替代方案。然而,规模化合并面临挑战,成功的合并需要选择合适的合并操作符、模型和合并顺序。本文提出了一种预测合并选择方法SimMerge,通过计算模型之间的相似性信号,选择最佳合并,消除了昂贵的合并评估循环。实验表明,SimMerge在7B参数的2-way合并中超越了标准合并操作性能,并且在111B参数的多路合并中无需重新训练即可推广。我们还提出了一种支持动态添加新任务、模型和操作符的带赌博算法变体。
🔬 方法详解
问题定义:本文旨在解决在大规模模型合并中,如何高效选择合并操作符和合并顺序的问题。现有方法通常需要进行多次合并评估,成本高昂且效率低下。
核心思路:SimMerge通过计算模型之间的相似性信号,利用少量未标记的探针计算功能和结构特征,从而预测给定2-way合并的性能。这种方法避免了昂贵的合并评估循环。
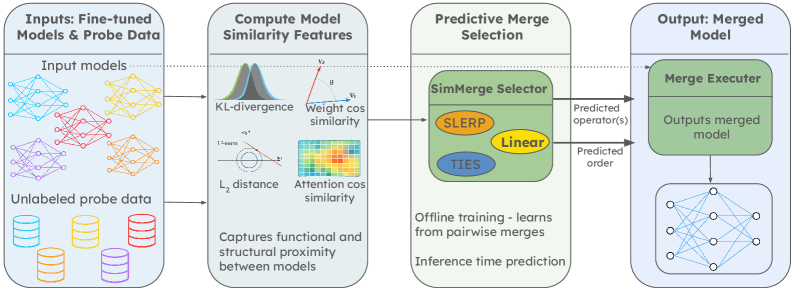
技术框架:SimMerge的整体架构包括三个主要模块:相似性信号计算模块、性能预测模块和合并选择模块。相似性信号模块负责从模型中提取特征,性能预测模块基于这些特征预测合并效果,合并选择模块则根据预测结果选择最佳的合并操作符和模型子集。
关键创新:SimMerge的核心创新在于其利用任务无关的相似性信号进行合并选择,这一方法显著降低了合并过程中的计算成本,并且能够在不同规模的模型合并中保持良好的性能。
关键设计:在设计中,SimMerge使用了一组功能和结构特征来进行性能预测,具体的参数设置和损失函数设计尚未详细披露,可能涉及标准的回归分析方法。
🖼️ 关键图片
📊 实验亮点
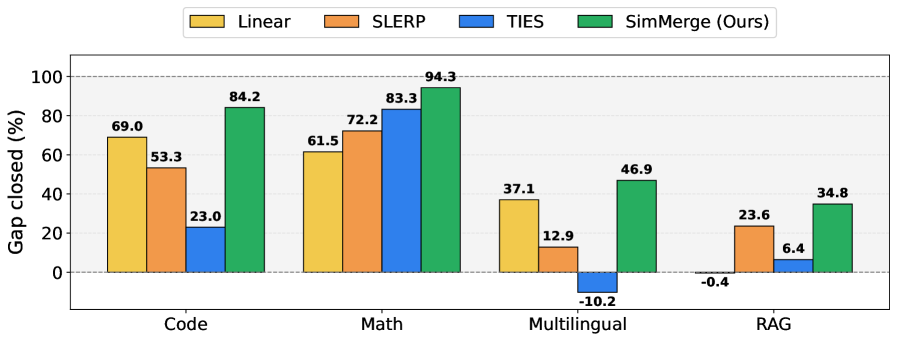
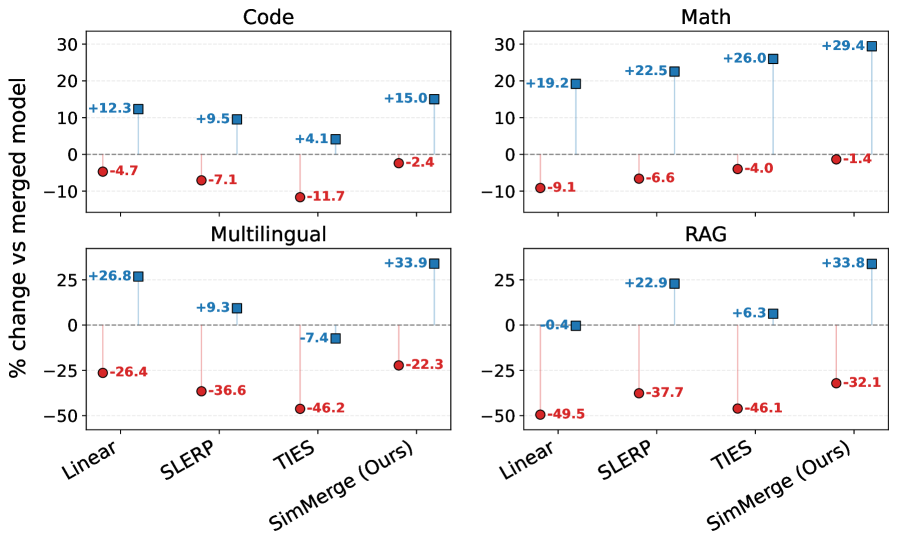
实验结果表明,SimMerge在7B参数的2-way合并中超越了标准合并操作的性能,且在111B参数的多路合并中无需重新训练即可实现良好的效果。这一成果展示了SimMerge在模型合并效率和效果上的显著提升。
🎯 应用场景
SimMerge的研究成果具有广泛的应用潜力,尤其在需要合并多个大型语言模型的场景中,如自然语言处理、对话系统和多任务学习等领域。其高效的合并选择方法能够帮助研究人员在有限的计算资源下实现更优的模型性能,推动模型的快速迭代与应用。
📄 摘要(原文)
Model merging enables multiple large language models (LLMs) to be combined into a single model while preserving performance. This makes it a valuable tool in LLM development, offering a competitive alternative to multi-task training. However, merging can be difficult at scale, as successful merging requires choosing the right merge operator, selecting the right models, and merging them in the right order. This often leads researchers to run expensive merge-and-evaluate searches to select the best merge. In this work, we provide an alternative by introducing \simmerge{}, \emph{a predictive merge-selection method} that selects the best merge using inexpensive, task-agnostic similarity signals between models. From a small set of unlabeled probes, we compute functional and structural features and use them to predict the performance of a given 2-way merge. Using these predictions, \simmerge{} selects the best merge operator, the subset of models to merge, and the merge order, eliminating the expensive merge-and-evaluate loop. We demonstrate that we surpass standard merge-operator performance on 2-way merges of 7B-parameter LLMs, and that \simmerge{} generalizes to multi-way merges and 111B-parameter LLM merges without retraining. Additionally, we present a bandit variant that supports adding new tasks, models, and operators on the fly. Our results suggest that learning how to merge is a practical route to scalable model composition when checkpoint catalogs are large and evaluation budgets are tight.