Late Breaking Results: Quamba-SE: Soft-edge Quantizer for Activations in State Space Models
作者: Yizhi Chen, Ahmed Hemani
分类: cs.LG, cs.AI, cs.AR
发布日期: 2026-01-14
备注: Accepted to DATE Late Breaking Results 2026, Verona, Italy
💡 一句话要点
Quamba-SE:用于状态空间模型激活量化的软边缘量化器
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 激活量化 软边缘量化 模型压缩 Mamba 零样本学习 INT8量化
📋 核心要点
- 现有激活量化方法在状态空间模型中存在信息损失,尤其是在处理异常值时,硬裁剪会降低模型性能。
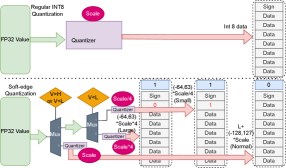
- Quamba-SE通过引入软边缘量化,使用自适应尺度来处理不同范围的激活值,从而保留异常值信息并提高整体精度。
- 实验结果表明,Quamba-SE在Mamba-130M模型上,针对多个零样本基准测试,性能优于现有Quamba量化方法。
📝 摘要(中文)
我们提出了Quamba-SE,一种用于状态空间模型(SSM)激活量化的软边缘量化器。与现有方法不同,Quamba-SE使用标准的INT8操作,并采用三种自适应尺度:高精度用于小数值,标准尺度用于正常值,低精度用于异常值。这保留了异常值信息,而不是进行硬裁剪,同时保持了其他值的精度。我们在Mamba-130M上,针对6个零样本基准进行了评估。结果表明,Quamba-SE始终优于Quamba,在单个基准上实现了高达+2.68%的提升,在6个数据集的平均准确率上实现了高达+0.83%的提升。
🔬 方法详解
问题定义:论文旨在解决状态空间模型(SSM)中激活量化时,由于硬裁剪导致的异常值信息丢失问题。现有的量化方法通常采用统一的量化尺度,对于超出范围的激活值进行硬裁剪,这会严重影响模型的性能,尤其是在处理长尾分布的数据时。
核心思路:Quamba-SE的核心思路是引入软边缘量化,即不采用硬裁剪,而是使用不同的量化尺度来处理不同范围的激活值。具体来说,对于小数值,使用高精度量化;对于正常值,使用标准尺度量化;对于异常值,使用低精度量化。这样既可以保留异常值的信息,又可以保证其他值的精度。
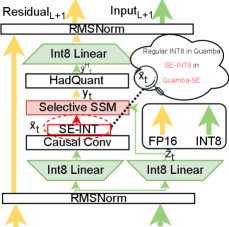
技术框架:Quamba-SE的整体框架是在现有的状态空间模型(如Mamba)中,将激活函数的输出进行量化时,替换为Quamba-SE量化器。该量化器包含三个自适应尺度,分别对应于不同的激活值范围。具体流程为:首先,将激活值输入到Quamba-SE量化器中;然后,根据激活值的大小,选择对应的量化尺度;最后,对激活值进行量化。
关键创新:Quamba-SE的关键创新在于提出了软边缘量化的概念,并将其应用于状态空间模型的激活量化中。与传统的硬裁剪量化方法相比,Quamba-SE能够更好地保留异常值的信息,从而提高模型的性能。此外,Quamba-SE还采用了自适应尺度,可以根据激活值的分布动态调整量化尺度,进一步提高了量化的精度。
关键设计:Quamba-SE的关键设计在于三个自适应尺度的选择和调整。这些尺度需要根据具体的激活值分布进行调整,以达到最佳的量化效果。论文中可能使用了某种策略(具体细节未知)来自动调整这些尺度。此外,损失函数的设计也可能需要考虑软边缘量化的特点,以避免过度惩罚异常值。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Quamba-SE在Mamba-130M模型上,针对6个零样本基准测试,性能优于现有的Quamba量化方法。在单个基准上,Quamba-SE实现了高达+2.68%的提升,在6个数据集的平均准确率上实现了高达+0.83%的提升。这些结果表明,Quamba-SE能够有效地保留异常值信息,并提高模型的整体性能。
🎯 应用场景
Quamba-SE具有广泛的应用前景,可以应用于各种需要进行模型压缩和加速的状态空间模型中,例如Mamba、RWKV等。该方法可以降低模型的存储空间和计算复杂度,使其更容易部署在资源受限的设备上,例如移动设备和嵌入式系统。此外,Quamba-SE还可以应用于自然语言处理、计算机视觉等领域,提高相关任务的性能。
📄 摘要(原文)
We propose Quamba-SE, a soft-edge quantizer for State Space Model (SSM) activation quantization. Unlike existing methods, using standard INT8 operation, Quamba-SE employs three adaptive scales: high-precision for small values, standard scale for normal values, and low-precision for outliers. This preserves outlier information instead of hard clipping, while maintaining precision for other values. We evaluate on Mamba- 130M across 6 zero-shot benchmarks. Results show that Quamba- SE consistently outperforms Quamba, achieving up to +2.68% on individual benchmarks and up to +0.83% improvement in the average accuracy of 6 datasets.