Reward Learning through Ranking Mean Squared Error
作者: Chaitanya Kharyal, Calarina Muslimani, Matthew E. Taylor
分类: cs.LG, cs.AI
发布日期: 2026-01-14
💡 一句话要点
提出R4方法,通过排序均方误差学习奖励函数,提升机器人强化学习效率。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 奖励学习 强化学习 排序学习 均方误差 机器人控制
📋 核心要点
- 现有强化学习奖励函数设计依赖人工,成本高昂且易出错,限制了其在现实世界的应用。
- R4方法通过排序均方误差(rMSE)损失,将人类评分转化为序数目标,学习奖励函数。
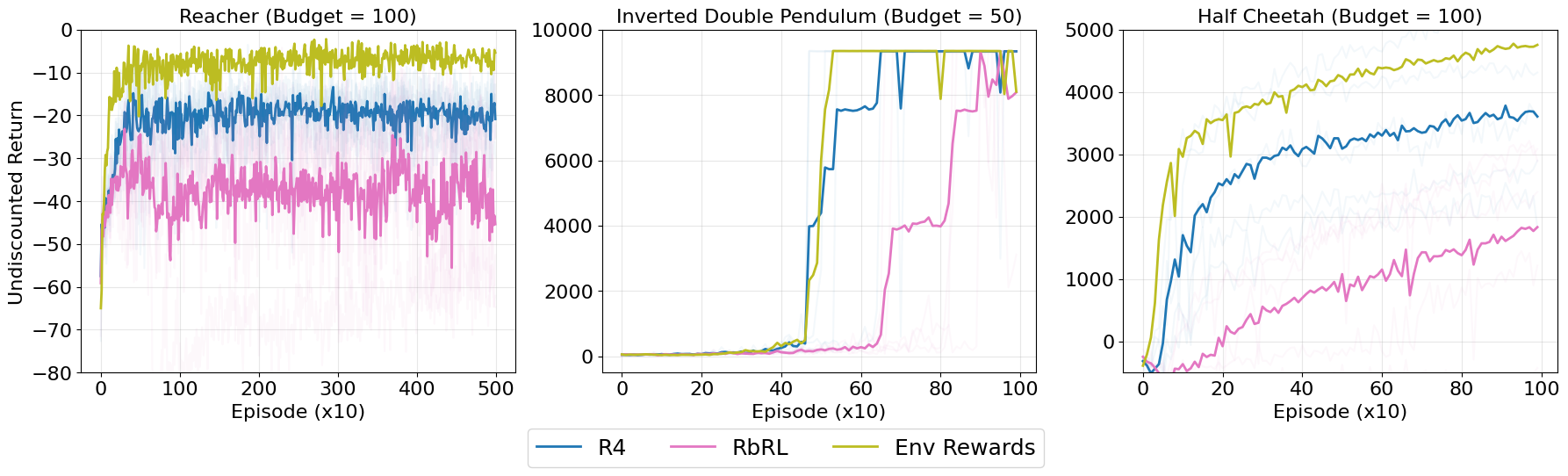
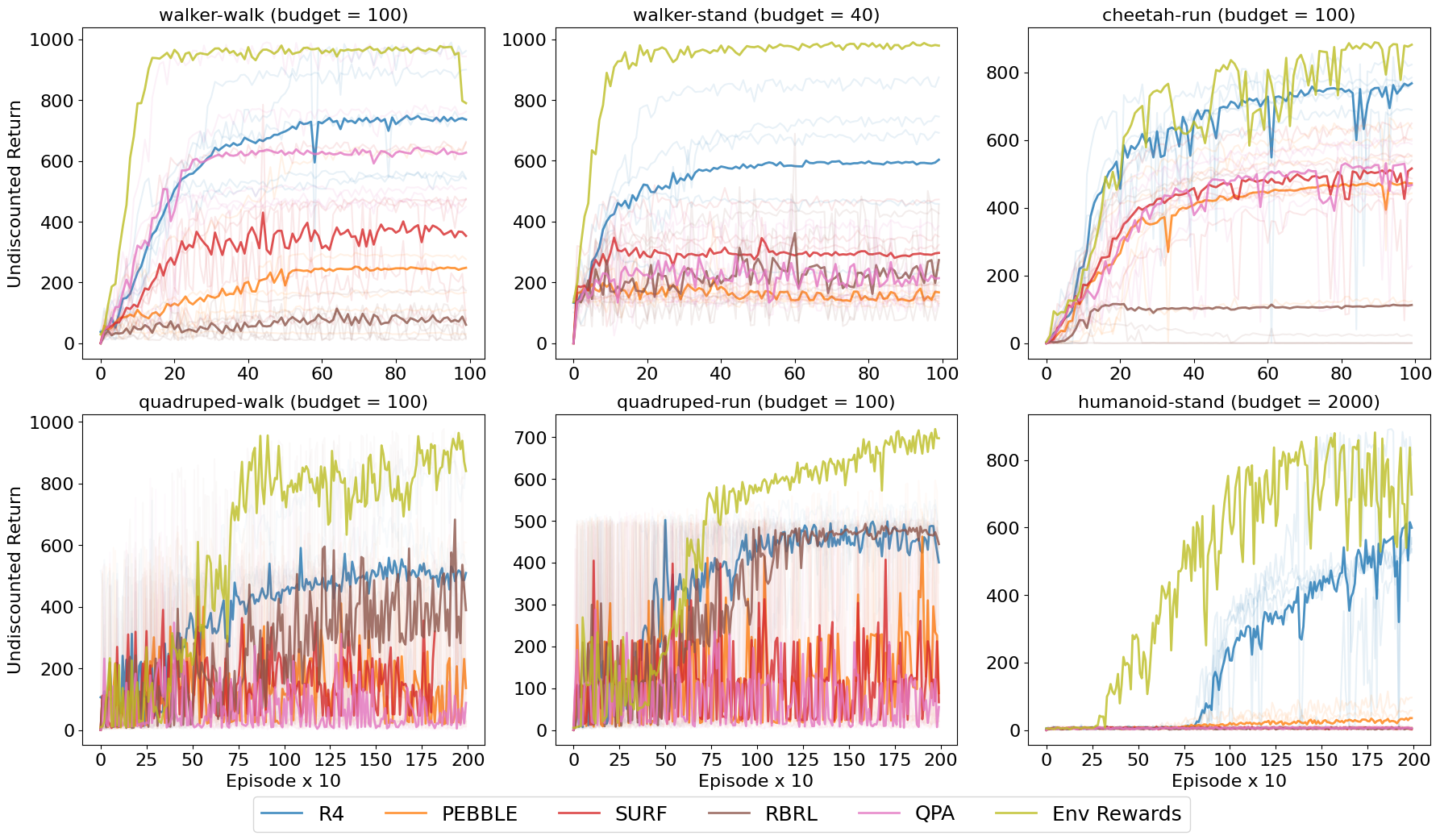
- 实验表明,R4在机器人运动任务上优于现有方法,且所需人类反馈更少,效率更高。
📝 摘要(中文)
奖励函数设计是强化学习应用于实际问题的瓶颈。奖励学习提供了一种替代方案,即从人类反馈中推断奖励函数,而非手动指定。本文提出了一种新的基于评分的强化学习方法,称为用于强化学习的排序回报回归(R4)。R4的核心是采用一种新的排序均方误差(rMSE)损失,它将教师提供的评分视为序数目标。该方法从轨迹-评分对的数据集中学习,其中每个轨迹都标有离散评分(例如,“差”、“中性”、“好”)。在每个训练步骤中,我们采样一组轨迹,预测它们的回报,并使用可微分排序算子(软排序)对它们进行排序。然后,我们优化所得的软排序与教师评分之间的均方误差损失。与之前的基于评分的方法不同,R4提供了形式化的保证:在温和的假设下,其解集是可证明的最小且完整的。通过模拟人类反馈,我们证明了R4在OpenAI Gym和DeepMind Control Suite的机器人运动基准测试中,始终与现有的基于评分和偏好的强化学习方法相匹配或优于它们,同时需要显著更少的反馈。
🔬 方法详解
问题定义:现有强化学习方法在实际应用中面临奖励函数设计的难题。手动设计奖励函数耗时费力,且难以保证奖励函数能够引导智能体学习到期望的行为。基于偏好的奖励学习方法需要大量的成对比较数据,认知负担重。基于评分的奖励学习方法虽然减轻了认知负担,但缺乏理论保证,且性能有待提升。
核心思路:R4的核心思路是将人类提供的评分视为序数目标,并设计一种排序均方误差(rMSE)损失函数,直接优化预测回报的排序与人类评分的排序之间的差异。通过这种方式,R4能够有效地利用人类提供的评分信息,学习到高质量的奖励函数。
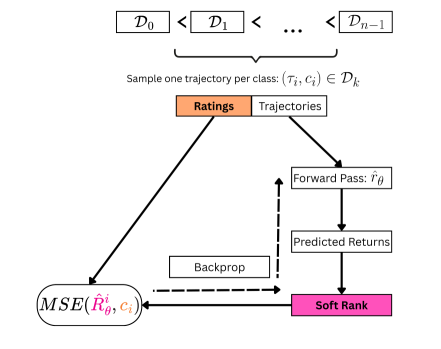
技术框架:R4方法包含以下主要步骤:1) 从环境中采样一组轨迹;2) 使用奖励函数预测每个轨迹的回报;3) 使用可微分排序算子(soft ranks)对预测的回报进行排序,得到软排序;4) 计算软排序与人类评分之间的rMSE损失;5) 使用梯度下降法优化奖励函数,使其预测的回报排序更接近人类评分的排序。
关键创新:R4的关键创新在于提出了rMSE损失函数,它能够有效地利用人类提供的序数信息,并提供形式化的保证,即其解集是可证明的最小且完整的。此外,R4使用可微分排序算子,使得整个训练过程可以端到端地进行优化。
关键设计:R4使用均方误差作为损失函数,优化预测排序与人类评分之间的差异。排序算子采用可微分的soft rank方法,保证梯度能够有效传播。奖励函数可以使用神经网络进行参数化,并通过梯度下降法进行优化。实验中,作者使用了不同的网络结构和超参数设置,并进行了详细的消融实验。
🖼️ 关键图片
📊 实验亮点
实验结果表明,R4在多个机器人运动任务上优于现有的基于评分和偏好的强化学习方法。例如,在某些任务上,R4能够以更少的反馈数据达到与现有方法相当甚至更好的性能。此外,R4还具有形式化的理论保证,证明了其解集的最小性和完整性。
🎯 应用场景
R4方法可应用于机器人控制、游戏AI、自动驾驶等领域,通过人类评分来学习奖励函数,从而实现更智能、更符合人类意图的智能体行为。该方法降低了奖励函数设计的难度,有望加速强化学习在实际问题中的应用。
📄 摘要(原文)
Reward design remains a significant bottleneck in applying reinforcement learning (RL) to real-world problems. A popular alternative is reward learning, where reward functions are inferred from human feedback rather than manually specified. Recent work has proposed learning reward functions from human feedback in the form of ratings, rather than traditional binary preferences, enabling richer and potentially less cognitively demanding supervision. Building on this paradigm, we introduce a new rating-based RL method, Ranked Return Regression for RL (R4). At its core, R4 employs a novel ranking mean squared error (rMSE) loss, which treats teacher-provided ratings as ordinal targets. Our approach learns from a dataset of trajectory-rating pairs, where each trajectory is labeled with a discrete rating (e.g., "bad," "neutral," "good"). At each training step, we sample a set of trajectories, predict their returns, and rank them using a differentiable sorting operator (soft ranks). We then optimize a mean squared error loss between the resulting soft ranks and the teacher's ratings. Unlike prior rating-based approaches, R4 offers formal guarantees: its solution set is provably minimal and complete under mild assumptions. Empirically, using simulated human feedback, we demonstrate that R4 consistently matches or outperforms existing rating and preference-based RL methods on robotic locomotion benchmarks from OpenAI Gym and the DeepMind Control Suite, while requiring significantly less feedback.