$D^2Prune$: Sparsifying Large Language Models via Dual Taylor Expansion and Attention Distribution Awareness
作者: Lang Xiong, Ning Liu, Ao Ren, Yuheng Bai, Haining Fang, BinYan Zhang, Zhe Jiang, Yujuan Tan, Duo Liu
分类: cs.LG
发布日期: 2026-01-14
💡 一句话要点
提出基于双重泰勒展开和注意力分布感知的LLM稀疏化方法$D^2Prune$
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 模型剪枝 泰勒展开 注意力机制 模型压缩
📋 核心要点
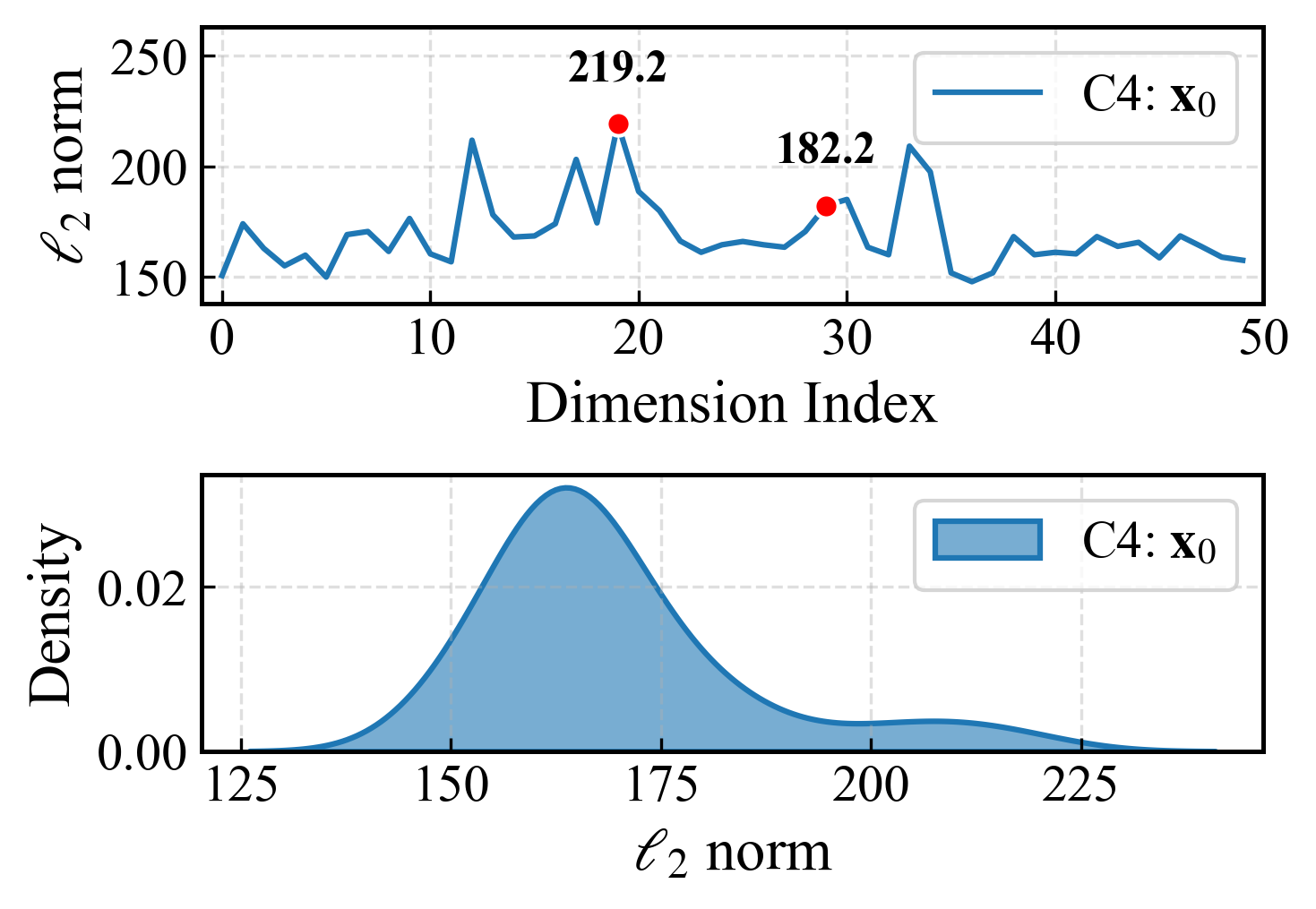
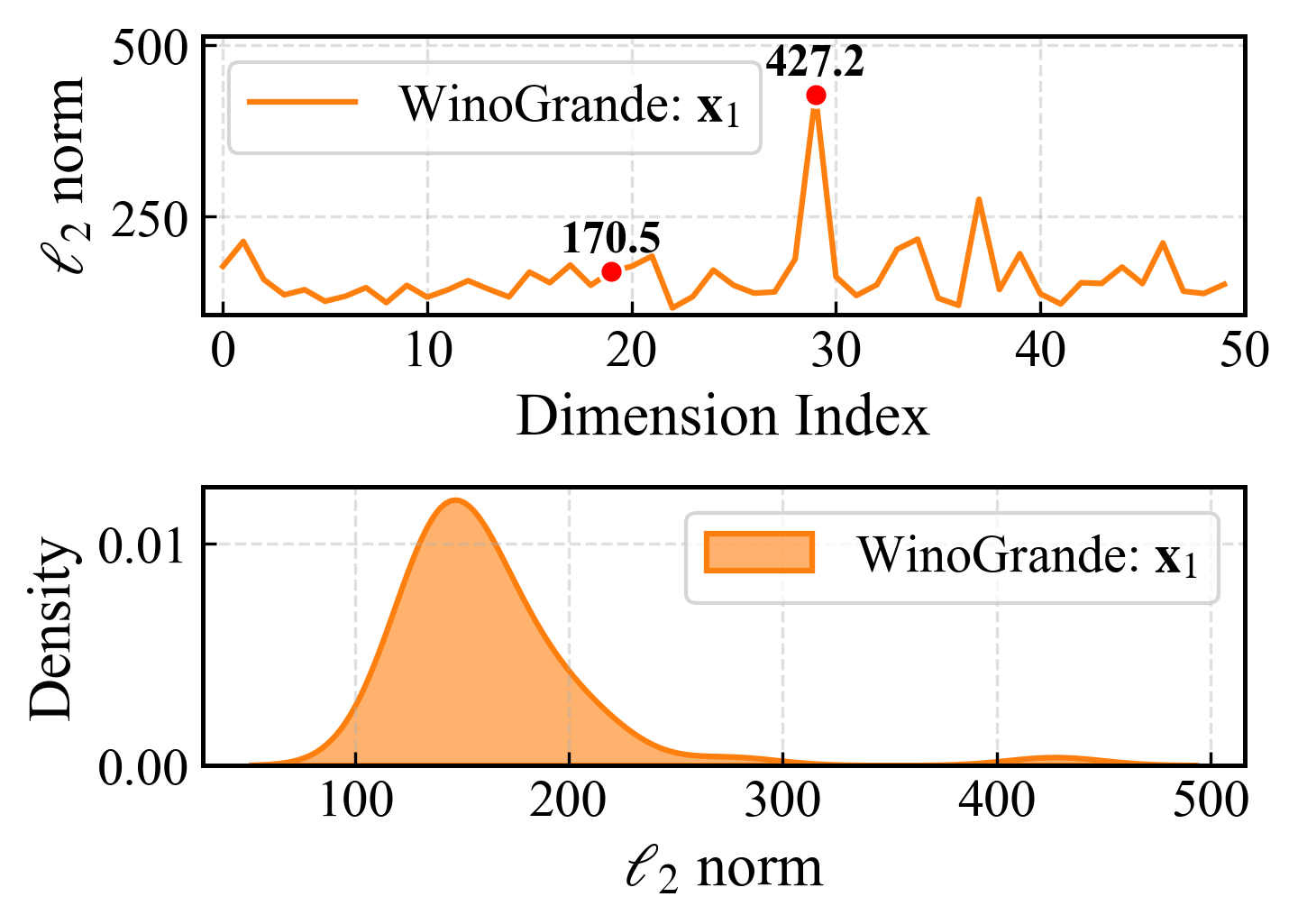
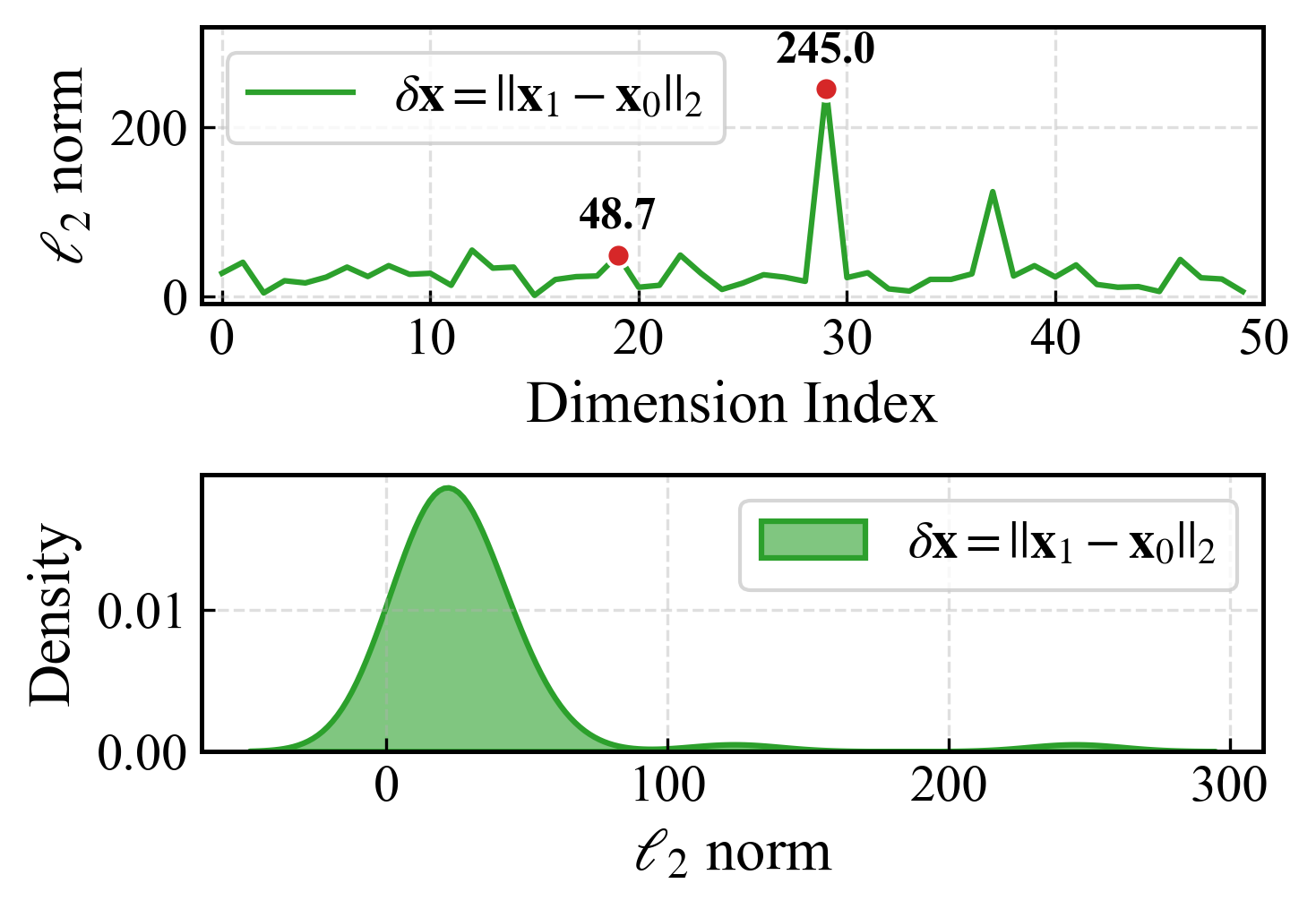
- 现有LLM剪枝方法忽略了校准数据与测试数据间激活分布的偏移,导致误差估计不准。
- $D^2Prune$通过双重泰勒展开联合建模权重和激活扰动,实现更精确的误差估计和剪枝。
- $D^2Prune$提出注意力感知的动态更新策略,保留长尾注意力模式,并在多种LLM和ViT模型上取得SOTA效果。
📝 摘要(中文)
大型语言模型(LLMs)由于其巨大的计算需求而面临着严峻的部署挑战。剪枝作为一种有前景的压缩解决方案,但现有方法存在两个关键限制:(1)它们忽略了校准数据和测试数据之间的激活分布偏移,导致不准确的误差估计;(2)它们忽略了注意力模块中激活的长尾分布特征。为了解决这些限制,本文提出了一种新的剪枝方法$D^2Prune$。首先,我们提出了一种基于双重泰勒展开的方法,该方法联合建模权重和激活扰动,以进行精确的误差估计,从而实现精确的剪枝掩码选择和权重更新,并有助于在剪枝过程中最小化误差。其次,我们提出了一种注意力感知的动态更新策略,通过联合最小化注意力分布的KL散度和重建误差来保留长尾注意力模式。大量实验表明,$D^2Prune$在各种LLM(例如,OPT-125M,LLaMA2/3和Qwen3)上始终优于SOTA方法。此外,动态注意力更新机制还可以很好地推广到基于ViT的视觉模型(如DeiT),从而在ImageNet-1K上获得更高的准确性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)剪枝过程中,现有方法由于忽略校准数据和测试数据之间激活分布的偏移以及注意力模块中激活的长尾分布特征,导致剪枝效果不佳的问题。现有方法无法准确估计剪枝带来的误差,从而影响模型的性能。
核心思路:论文的核心思路是通过双重泰勒展开同时考虑权重和激活的扰动,从而更精确地估计剪枝带来的误差。此外,针对注意力模块,采用注意力感知的动态更新策略,保留重要的长尾注意力模式,以减少剪枝对模型性能的影响。这样设计的目的是为了更全面地评估剪枝对模型的影响,并有针对性地进行优化。
技术框架:$D^2Prune$方法主要包含两个核心模块:1) 基于双重泰勒展开的剪枝掩码选择和权重更新模块,该模块利用双重泰勒展开精确估计剪枝误差,并选择合适的剪枝掩码和更新权重;2) 注意力感知的动态更新模块,该模块通过最小化注意力分布的KL散度和重建误差,动态更新注意力权重,保留长尾注意力模式。整体流程是先利用双重泰勒展开进行初步剪枝,然后通过注意力感知的动态更新进一步优化模型。
关键创新:该方法最重要的技术创新点在于双重泰勒展开的应用和注意力感知的动态更新策略。双重泰勒展开能够更准确地估计剪枝误差,而注意力感知的动态更新策略能够有效地保留注意力模块中的重要信息。与现有方法相比,该方法更全面地考虑了剪枝对模型的影响,并有针对性地进行了优化。
关键设计:在双重泰勒展开中,需要计算权重和激活的一阶和二阶导数,并选择合适的步长进行权重更新。在注意力感知的动态更新中,需要选择合适的KL散度系数和重建误差系数,以平衡注意力分布的保留和模型性能的优化。具体的损失函数包括权重扰动和激活扰动带来的损失,以及注意力分布KL散度损失和重建误差损失。
🖼️ 关键图片
📊 实验亮点
$D^2Prune$在OPT-125M、LLaMA2/3和Qwen3等多种LLM上均优于SOTA方法。此外,该方法在ViT-based视觉模型DeiT上也能取得优异的ImageNet-1K分类精度,表明其具有良好的泛化能力。具体性能提升数据未知,但摘要强调了“consistently outperforms SOTA methods”和“superior accuracy”。
🎯 应用场景
该研究成果可广泛应用于各种大型语言模型的压缩和部署,尤其是在资源受限的边缘设备上。通过降低模型的大小和计算复杂度,可以显著提高LLM在移动设备、嵌入式系统等场景下的可用性,加速人工智能技术的普及。
📄 摘要(原文)
Large language models (LLMs) face significant deployment challenges due to their massive computational demands. % While pruning offers a promising compression solution, existing methods suffer from two critical limitations: (1) They neglect activation distribution shifts between calibration data and test data, resulting in inaccurate error estimations; (2) They overlook the long-tail distribution characteristics of activations in the attention module. To address these limitations, this paper proposes a novel pruning method, $D^2Prune$. First, we propose a dual Taylor expansion-based method that jointly models weight and activation perturbations for precise error estimation, leading to precise pruning mask selection and weight updating and facilitating error minimization during pruning. % Second, we propose an attention-aware dynamic update strategy that preserves the long-tail attention pattern by jointly minimizing the KL divergence of attention distributions and the reconstruction error. Extensive experiments show that $D^2Prune$ consistently outperforms SOTA methods across various LLMs (e.g., OPT-125M, LLaMA2/3, and Qwen3). Moreover, the dynamic attention update mechanism also generalizes well to ViT-based vision models like DeiT, achieving superior accuracy on ImageNet-1K.