Hidden States as Early Signals: Step-level Trace Evaluation and Pruning for Efficient Test-Time Scaling
作者: Zhixiang Liang, Beichen Huang, Zheng Wang, Minjia Zhang
分类: cs.LG
发布日期: 2026-01-14
🔗 代码/项目: GITHUB
💡 一句话要点
提出STEP框架,利用隐状态评估和剪枝加速LLM测试时推理并提升精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理加速 轨迹剪枝 隐状态 GPU内存优化
📋 核心要点
- 现有基于相似性和置信度的轨迹剪枝方法无法准确评估轨迹质量,导致推理效率提升有限。
- STEP框架利用隐状态评估推理步骤质量,动态剪枝低质量轨迹,从而降低计算开销和延迟。
- 实验表明,STEP在降低端到端推理延迟的同时,还能提升推理精度,具有显著的性能优势。
📝 摘要(中文)
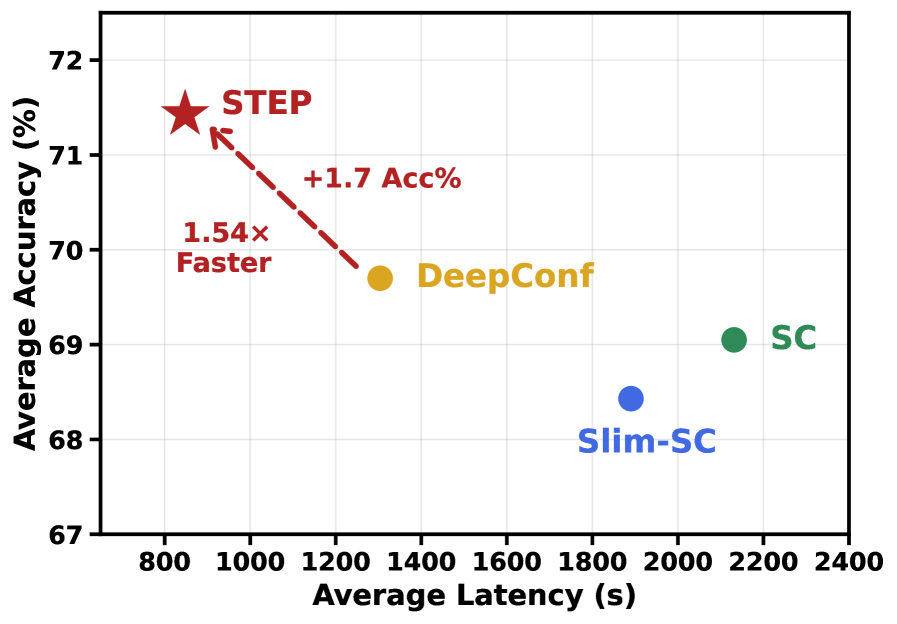
大型语言模型(LLMs)可以通过生成多个推理轨迹,在测试时扩展推理能力。然而,冗长的推理轨迹与多重抽样的结合带来了巨大的计算开销和高延迟。先前加速这一过程的工作依赖于基于相似性或置信度的剪枝,但这些信号并不能可靠地指示轨迹质量。为了解决这些限制,我们提出了STEP:步级轨迹评估和剪枝,这是一个新颖的剪枝框架,它使用隐状态评估推理步骤,并在生成过程中动态地剪枝没有希望的轨迹。我们训练了一个轻量级的步级评分器来估计轨迹质量,并设计了一个GPU内存感知的剪枝策略,该策略在GPU内存被KV缓存饱和时触发剪枝,以减少端到端延迟。在具有挑战性的推理基准上的实验表明,与自洽性相比,STEP平均降低了45%-70%的端到端推理延迟,同时也提高了推理精度。我们的代码已在https://github.com/Supercomputing-System-AI-Lab/STEP发布。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在测试时通过生成多条推理轨迹来提升性能时,计算开销过大和端到端延迟过高的问题。现有的基于相似性或置信度的剪枝方法无法准确评估轨迹质量,导致剪枝效果不佳,无法有效降低计算成本。
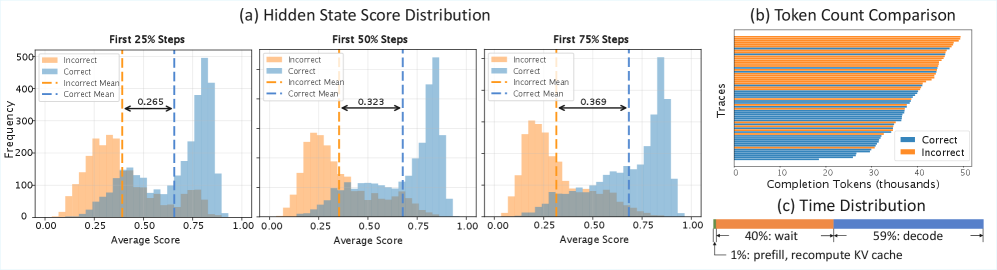
核心思路:论文的核心思路是利用LLM在每一步推理过程中产生的隐状态来评估该步骤的质量,进而预测整个轨迹的潜在价值。通过训练一个轻量级的步级评分器,根据隐状态对每一步进行打分,并动态地剪枝那些被认为不太可能产生正确答案的轨迹。
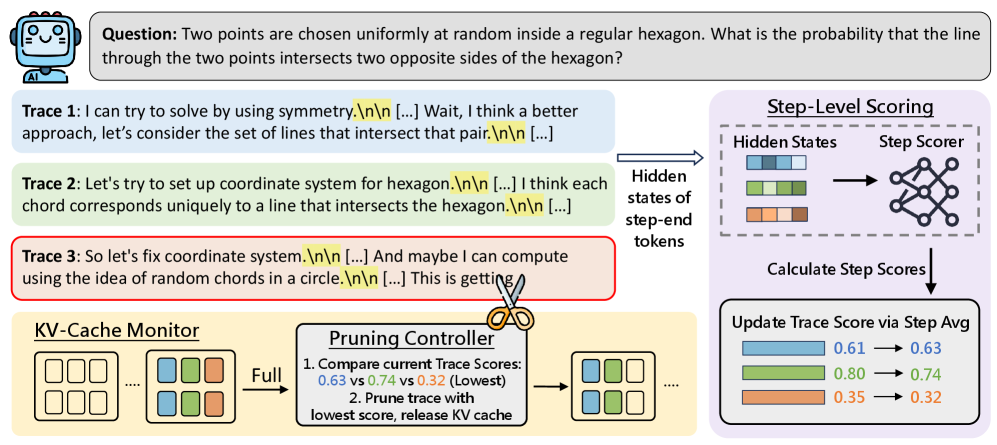
技术框架:STEP框架包含以下主要模块:1) 步级评分器:一个轻量级的神经网络,输入为LLM在每一步推理中产生的隐状态,输出为该步骤的质量评分。2) 轨迹评估:根据步级评分器的输出,对整个轨迹的质量进行评估。3) 动态剪枝:根据轨迹评估结果,动态地剪枝那些被认为不太可能产生正确答案的轨迹。4) GPU内存感知剪枝策略:监控GPU内存使用情况,当KV缓存接近饱和时,触发剪枝操作,以避免OOM错误并降低延迟。
关键创新:STEP的关键创新在于利用隐状态作为评估轨迹质量的信号。与传统的基于相似性或置信度的剪枝方法相比,隐状态能够更直接地反映LLM在推理过程中的内部状态,从而更准确地评估轨迹的潜在价值。此外,GPU内存感知剪枝策略能够有效地避免OOM错误,并进一步降低端到端延迟。
关键设计:步级评分器可以使用简单的MLP网络,输入为隐状态,输出为标量评分。损失函数可以使用交叉熵损失,目标是预测该步骤是否导向最终的正确答案。GPU内存感知剪枝策略需要设置一个内存阈值,当KV缓存使用量超过该阈值时,触发剪枝操作。剪枝比例可以根据实际情况进行调整,以平衡计算成本和推理精度。
🖼️ 关键图片
📊 实验亮点
实验结果表明,STEP在多个具有挑战性的推理基准上,与自洽性方法相比,平均降低了45%-70%的端到端推理延迟,同时还提高了推理精度。这表明STEP能够有效地降低计算成本,并提升LLM的推理性能。
🎯 应用场景
STEP框架可应用于各种需要LLM进行复杂推理的场景,例如问答系统、代码生成、数学问题求解等。通过降低推理延迟和计算成本,STEP可以使LLM在资源受限的环境中更高效地运行,并加速LLM在实际应用中的部署。
📄 摘要(原文)
Large Language Models (LLMs) can enhance reasoning capabilities through test-time scaling by generating multiple traces. However, the combination of lengthy reasoning traces with multiple sampling introduces substantial computation and high end-to-end latency. Prior work on accelerating this process has relied on similarity-based or confidence-based pruning, but these signals do not reliably indicate trace quality. To address these limitations, we propose STEP: Step-level Trace Evaluation and Pruning, a novel pruning framework that evaluates reasoning steps using hidden states and dynamically prunes unpromising traces during generation. We train a lightweight step scorer to estimate trace quality, and design a GPU memory-aware pruning strategy that triggers pruning as the GPU memory is saturated by KV cache to reduce end-to-end latency. Experiments across challenging reasoning benchmarks demonstrate that STEP reduces end-to-end inference latency by 45%-70% on average compared to self-consistency while also improving reasoning accuracy. Our code is released at: https://github.com/Supercomputing-System-AI-Lab/STEP