Distribution-Aligned Sequence Distillation for Superior Long-CoT Reasoning
作者: Shaotian Yan, Kaiyuan Liu, Chen Shen, Bing Wang, Sinan Fan, Jun Zhang, Yue Wu, Zheng Wang, Jieping Ye
分类: cs.LG, cs.CL
发布日期: 2026-01-14
备注: Project Page: https://github.com/D2I-ai/dasd-thinking
💡 一句话要点
提出分布对齐序列蒸馏(DASD),提升轻量级模型在长链推理任务上的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 序列蒸馏 分布对齐 长链推理 知识迁移 轻量级模型
📋 核心要点
- 现有序列级蒸馏方法侧重于SFT数据过滤,忽略了学生模型学习教师完整输出分布的核心目标。
- 论文提出分布对齐序列蒸馏(DASD),通过增强师生交互来解决教师分布表示不足、分布不匹配和暴露偏差等问题。
- DASD-4B-Thinking仅使用448K训练样本,在数学、科学推理和代码生成任务上达到SOTA,优于同等规模模型。
📝 摘要(中文)
本报告介绍了一种轻量级但功能强大的全开源推理模型DASD-4B-Thinking。它在数学、科学推理和代码生成等具有挑战性的基准测试中,在同等规模的开源模型中实现了SOTA性能,甚至优于一些更大的模型。我们首先批判性地重新审视社区中广泛采用的蒸馏范式:在教师生成的响应上进行SFT,也称为序列级蒸馏。尽管最近一系列遵循该方案的工作已经证明了显著的效率和强大的经验性能,但它们主要基于SFT的视角。因此,这些方法主要侧重于为SFT数据过滤设计启发式规则,而很大程度上忽略了蒸馏本身的核心原则——使学生模型学习教师的完整输出分布,从而继承其泛化能力。具体而言,我们确定了当前实践中的三个关键限制:i) 教师序列级分布的表示不足;ii) 教师输出分布与学生的学习能力不匹配;iii) 由教师强制训练与自回归推理引起的暴露偏差。总而言之,这些缺点反映了在整个蒸馏过程中显式师生交互的系统性缺失,导致蒸馏的本质未被充分利用。为了解决这些问题,我们提出了几项方法创新,共同构成了一个增强的序列级蒸馏训练流程。值得注意的是,DASD-4B-Thinking仅使用448K个训练样本就获得了具有竞争力的结果,比大多数现有开源工作使用的样本少一个数量级。为了支持社区研究,我们公开发布了我们的模型和训练数据集。
🔬 方法详解
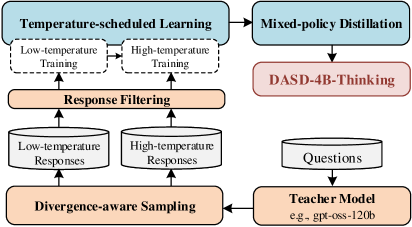
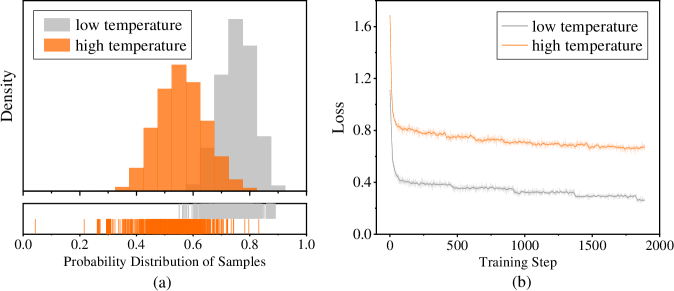
问题定义:现有序列级蒸馏方法在长链推理任务中存在不足,主要体现在三个方面:一是教师模型序列级分布的表示不充分,学生模型难以学习到教师模型的完整推理过程;二是教师模型的输出分布与学生模型的学习能力不匹配,导致学生模型无法有效模仿教师模型的行为;三是教师强制训练与自回归推理之间存在暴露偏差,影响学生模型的泛化能力。这些问题导致学生模型无法充分利用教师模型的知识,限制了其推理性能的提升。
核心思路:论文的核心思路是通过分布对齐来增强序列级蒸馏的效果。具体来说,论文旨在解决教师模型输出分布表示不足、师生模型分布不匹配以及暴露偏差等问题,从而使学生模型能够更好地学习教师模型的推理能力。通过显式地建模和对齐师生模型的分布,可以提高学生模型的泛化能力和推理性能。
技术框架:DASD方法包含以下几个主要模块:首先,对教师模型的输出进行更全面的表示,例如通过引入额外的特征或使用更复杂的模型结构。其次,设计一种分布对齐损失函数,用于衡量师生模型输出分布之间的差异,并引导学生模型学习教师模型的分布。第三,采用一种自适应的训练策略,以减少暴露偏差的影响,例如通过在训练过程中引入噪声或使用对抗训练。整体流程包括数据准备、教师模型推理、学生模型训练和评估等步骤。
关键创新:论文的关键创新在于提出了分布对齐序列蒸馏(DASD)方法,该方法通过显式地建模和对齐师生模型的输出分布,解决了现有序列级蒸馏方法中存在的教师分布表示不足、分布不匹配和暴露偏差等问题。与现有方法相比,DASD方法更加注重师生模型之间的交互,能够更有效地利用教师模型的知识,提高学生模型的推理性能。
关键设计:论文的关键设计包括:1) 使用KL散度或Wasserstein距离等方法来衡量师生模型输出分布之间的差异,并将其作为损失函数的一部分;2) 引入对抗训练或噪声注入等技术来减少暴露偏差的影响;3) 设计一种自适应的训练策略,根据学生模型的学习进度动态调整损失函数的权重或训练参数;4) 采用一种更有效的序列表示方法,例如使用Transformer或LSTM等模型来捕捉序列中的长期依赖关系。
🖼️ 关键图片

📊 实验亮点
DASD-4B-Thinking模型仅使用448K训练样本,在数学、科学推理和代码生成等任务上取得了SOTA性能,超越了同等规模的开源模型,甚至优于一些更大的模型。这表明该方法在提高模型推理能力方面具有显著优势,并且能够以较少的训练数据获得良好的性能。
🎯 应用场景
该研究成果可应用于各种需要长链推理能力的场景,例如数学问题求解、科学推理、代码生成等。通过蒸馏技术,可以将大型模型的知识迁移到轻量级模型中,使其能够在资源受限的环境中部署和应用。此外,该方法还可以用于提高现有模型的推理性能和泛化能力。
📄 摘要(原文)
In this report, we introduce DASD-4B-Thinking, a lightweight yet highly capable, fully open-source reasoning model. It achieves SOTA performance among open-source models of comparable scale across challenging benchmarks in mathematics, scientific reasoning, and code generation -- even outperforming several larger models. We begin by critically reexamining a widely adopted distillation paradigm in the community: SFT on teacher-generated responses, also known as sequence-level distillation. Although a series of recent works following this scheme have demonstrated remarkable efficiency and strong empirical performance, they are primarily grounded in the SFT perspective. Consequently, these approaches focus predominantly on designing heuristic rules for SFT data filtering, while largely overlooking the core principle of distillation itself -- enabling the student model to learn the teacher's full output distribution so as to inherit its generalization capability. Specifically, we identify three critical limitations in current practice: i) Inadequate representation of the teacher's sequence-level distribution; ii) Misalignment between the teacher's output distribution and the student's learning capacity; and iii) Exposure bias arising from teacher-forced training versus autoregressive inference. In summary, these shortcomings reflect a systemic absence of explicit teacher-student interaction throughout the distillation process, leaving the essence of distillation underexploited. To address these issues, we propose several methodological innovations that collectively form an enhanced sequence-level distillation training pipeline. Remarkably, DASD-4B-Thinking obtains competitive results using only 448K training samples -- an order of magnitude fewer than those employed by most existing open-source efforts. To support community research, we publicly release our models and the training dataset.