SRT: Accelerating Reinforcement Learning via Speculative Rollout with Tree-Structured Cache
作者: Chi-Chih Chang, Siqi Zhu, Zhichen Zeng, Haibin Lin, Jiaxuan You, Mohamed S. Abdelfattah, Ziheng Jiang, Xuehai Qian
分类: cs.LG
发布日期: 2026-01-14
💡 一句话要点
SRT:通过树状缓存的推测性Rollout加速强化学习,提升语言模型训练效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 语言模型 推测性解码 树状缓存 在线学习
📋 核心要点
- 现有强化学习方法在语言模型训练中rollout效率较低,成为性能瓶颈,需要更高效的探索策略。
- SRT利用prompt的rollout相似性,构建树状缓存存储历史生成结果,作为草稿模型加速推测解码。
- SRT集成到PPO等标准流程,通过在线更新缓存和run-ahead生成,显著降低延迟,加速训练过程。
📝 摘要(中文)
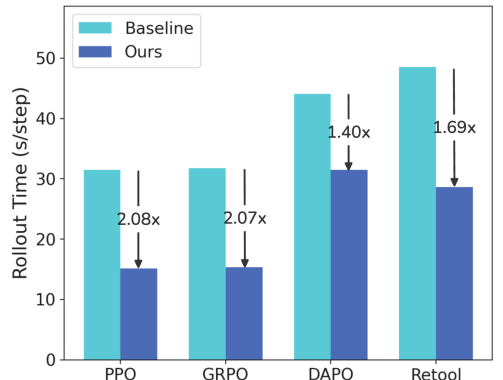
本文提出了一种名为“带树状缓存的推测性Rollout”(SRT)的简单、无模型的强化学习方法,用于加速语言模型的在线策略强化学习,且不牺牲分布正确性。SRT通过在每个prompt的树状缓存中存储先前生成的延续,来利用同一prompt在不同训练步骤中rollout的经验相似性。在生成过程中,当前策略使用该树作为草稿模型来执行推测性解码。为了保持缓存的新鲜度并提高草稿模型的质量,SRT从正在进行的rollout中在线更新树,并在空闲GPU时主动执行run-ahead生成。集成到标准强化学习流程(例如,PPO、GRPO和DAPO)和多轮设置中,SRT始终如一地减少生成和步长延迟,并降低每个token的推理成本,在rollout期间实现了高达2.08倍的实际加速。
🔬 方法详解
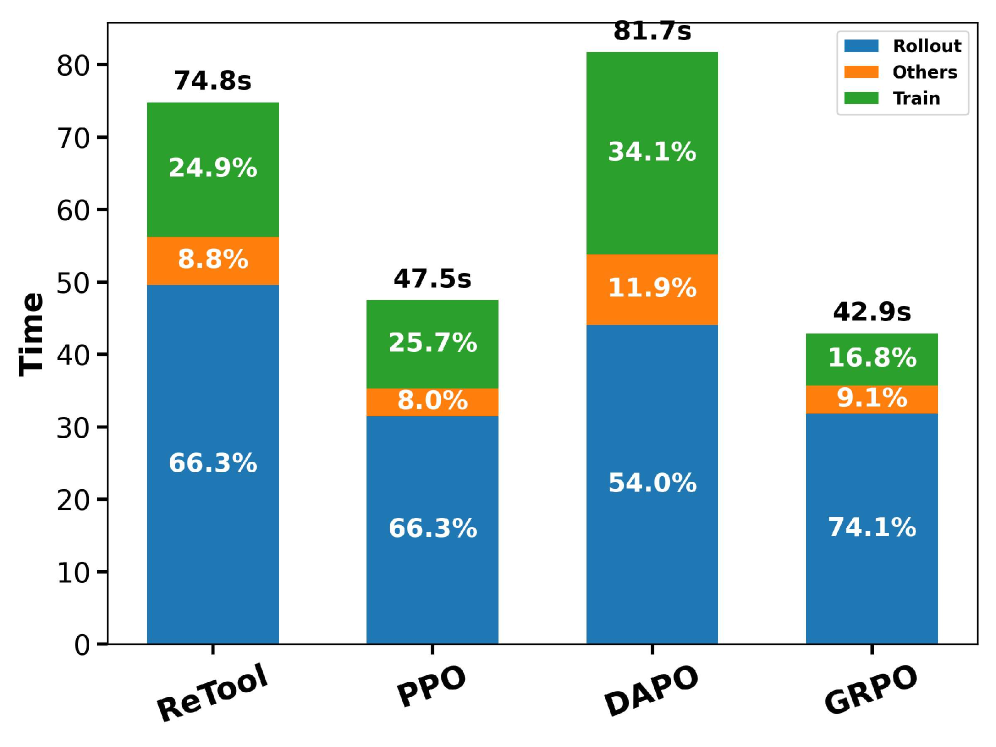
问题定义:在语言模型的强化学习训练中,rollout过程通常需要大量的计算资源和时间,特别是对于复杂的任务和长序列生成。现有的强化学习方法在rollout阶段效率较低,成为训练的瓶颈。如何加速rollout过程,降低计算成本,同时保证训练的稳定性和性能,是一个关键问题。
核心思路:SRT的核心思路是利用在强化学习训练过程中,对于相同的prompt,不同训练步骤的rollout具有经验相似性。通过缓存先前生成的延续,并将其组织成树状结构,可以有效地利用这些相似性来加速rollout过程。在生成过程中,使用缓存的树状结构作为草稿模型,进行推测性解码,从而减少实际的策略评估次数。
技术框架:SRT的整体框架包括以下几个主要模块:1) 树状缓存构建:为每个prompt维护一个树状缓存,用于存储先前生成的延续。2) 推测性解码:在生成过程中,使用树状缓存作为草稿模型,进行推测性解码。3) 在线更新:从正在进行的rollout中在线更新树状缓存,保持缓存的新鲜度。4) Run-ahead生成:在GPU空闲时,主动执行run-ahead生成,提前探索可能的延续,并更新缓存。SRT可以集成到现有的强化学习流程中,例如PPO、GRPO和DAPO。
关键创新:SRT的关键创新在于使用树状缓存来存储和利用rollout的经验相似性,并将其应用于推测性解码。与传统的推测性解码方法不同,SRT的草稿模型是基于实际的rollout数据构建的,而不是通过额外的模型训练得到的。这种方法可以更有效地利用历史数据,提高草稿模型的质量,从而加速rollout过程。
关键设计:SRT的关键设计包括:1) 树状缓存的结构:树的每个节点存储一个token,边表示token之间的转移概率。2) 推测性解码的策略:使用树状缓存作为草稿模型,生成多个候选延续,并使用当前策略进行评估和选择。3) 在线更新的策略:定期从正在进行的rollout中采样,更新树状缓存。4) Run-ahead生成的策略:在GPU空闲时,随机选择prompt,并使用当前策略生成新的延续,更新树状缓存。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SRT可以显著加速强化学习的rollout过程。在集成到PPO、GRPO和DAPO等标准强化学习流程后,SRT始终如一地减少生成和步长延迟,并降低每个token的推理成本,在rollout期间实现了高达2.08倍的实际加速。这些结果表明,SRT是一种有效的加速强化学习的方法,可以显著提高语言模型的训练效率。
🎯 应用场景
SRT具有广泛的应用前景,可以应用于各种需要语言模型进行强化学习的任务中,例如对话生成、文本摘要、机器翻译等。通过加速rollout过程,SRT可以显著降低训练成本,提高训练效率,从而加速这些任务的开发和部署。此外,SRT还可以应用于在线学习场景,例如智能客服、聊天机器人等,通过实时更新缓存,提高生成质量和响应速度。
📄 摘要(原文)
We present Speculative Rollout with Tree-Structured Cache (SRT), a simple, model-free approach to accelerate on-policy reinforcement learning (RL) for language models without sacrificing distributional correctness. SRT exploits the empirical similarity of rollouts for the same prompt across training steps by storing previously generated continuations in a per-prompt tree-structured cache. During generation, the current policy uses this tree as the draft model for performing speculative decoding. To keep the cache fresh and improve draft model quality, SRT updates trees online from ongoing rollouts and proactively performs run-ahead generation during idle GPU bubbles. Integrated into standard RL pipelines (\textit{e.g.}, PPO, GRPO and DAPO) and multi-turn settings, SRT consistently reduces generation and step latency and lowers per-token inference cost, achieving up to 2.08x wall-clock time speedup during rollout.