Model-Agnostic Solutions for Deep Reinforcement Learning in Non-Ergodic Contexts
作者: Bert Verbruggen, Arne Vanhoyweghen, Vincent Ginis
分类: cs.LG
发布日期: 2026-01-13
💡 一句话要点
提出时间依赖的深度强化学习方法,解决非遍历环境中策略次优问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 深度强化学习 非遍历环境 时间依赖性 价值函数估计 贝尔曼方程
📋 核心要点
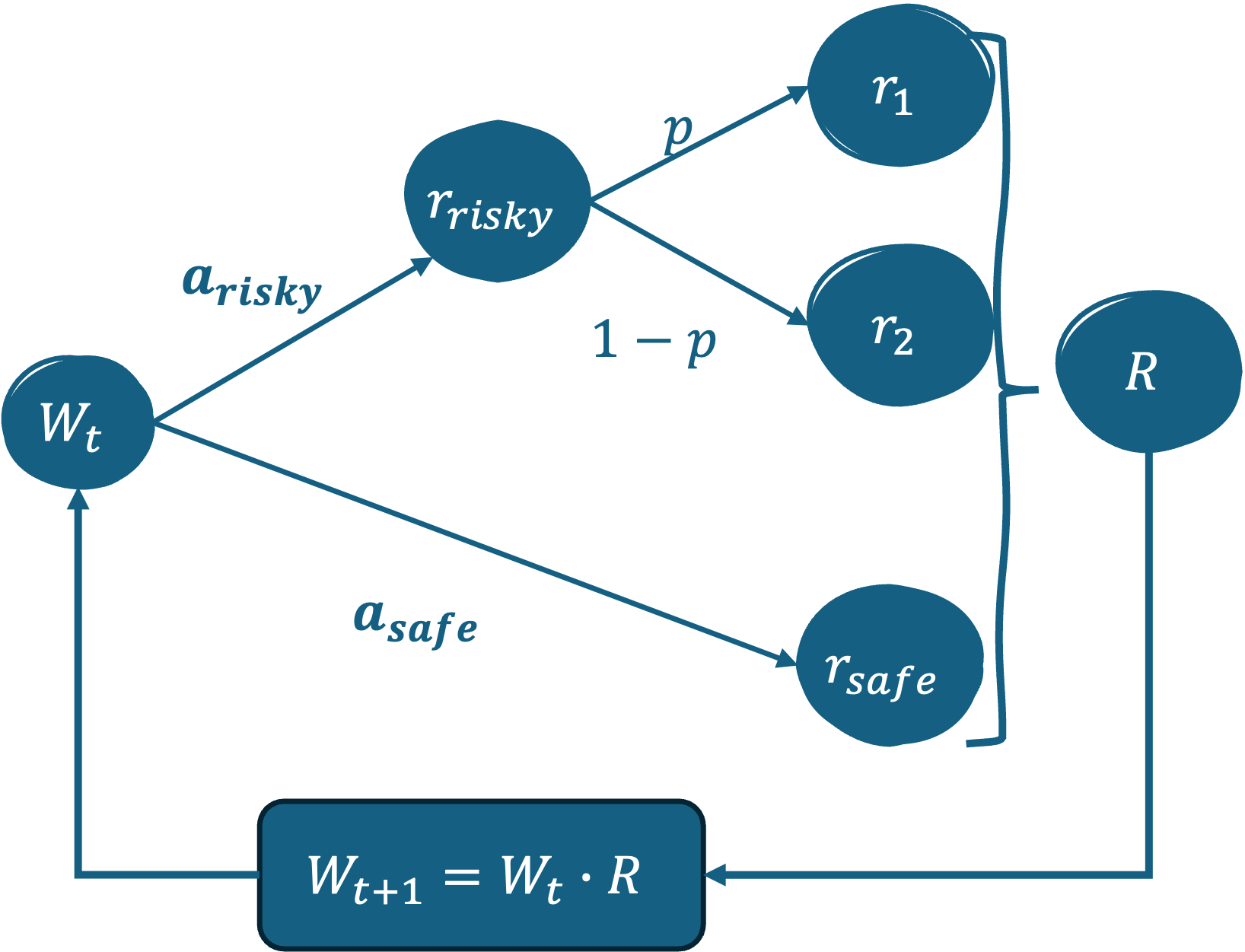
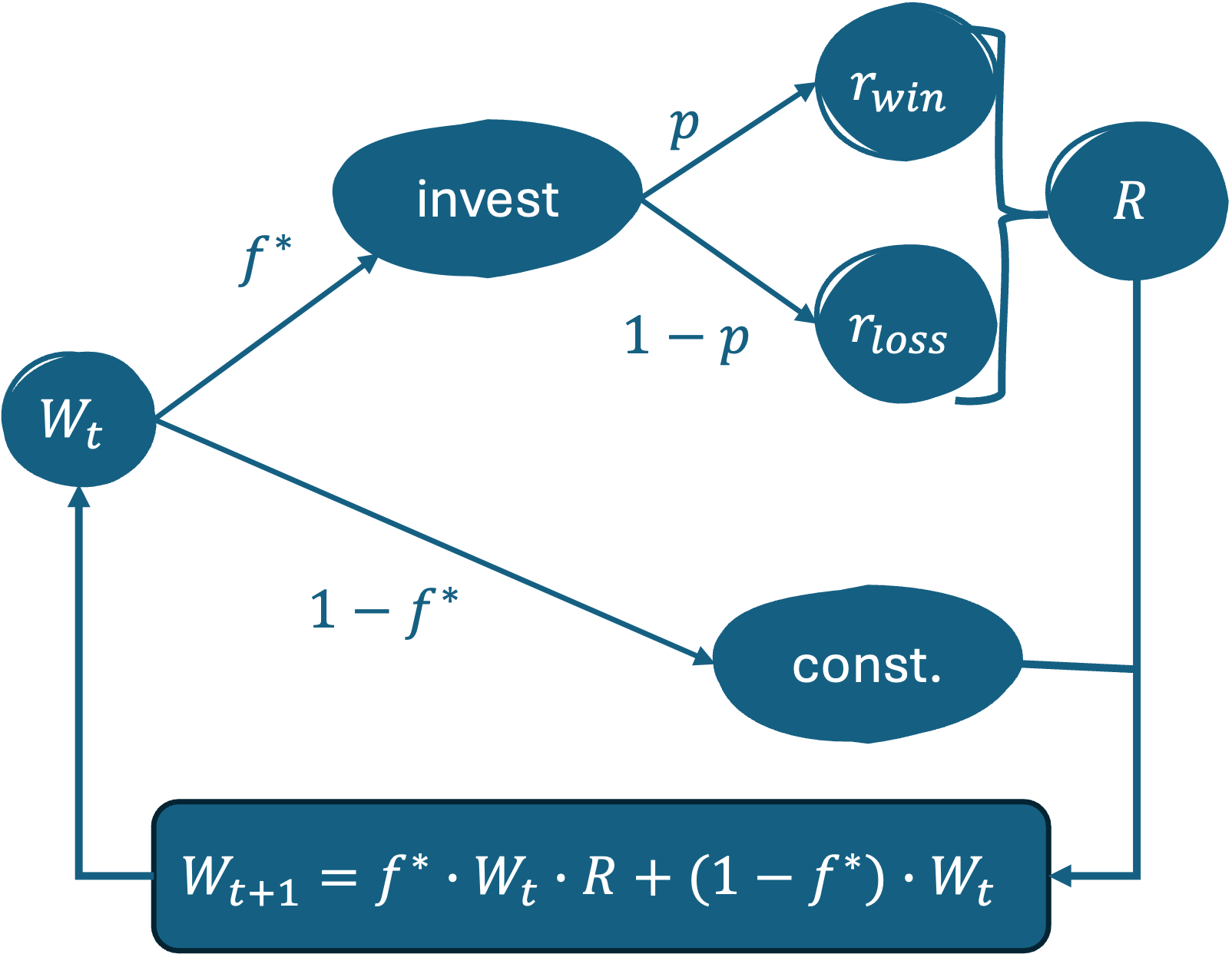
- 传统强化学习在非遍历环境中失效,因为其基于期望值的贝尔曼方程无法反映个体轨迹的时间平均增长。
- 该论文提出将时间依赖性显式地引入深度强化学习,使智能体能够学习与内在增长率一致的价值函数。
- 实验表明,引入时间依赖性的深度强化学习方法能够在非遍历环境中学习到更优的策略,而无需修改环境反馈。
📝 摘要(中文)
强化学习(RL)是机器学习中重要的优化框架。虽然RL智能体可以收敛到最优解,但“最优性”的定义取决于环境的统计特性。贝尔曼方程是大多数RL算法的核心,它基于未来奖励的期望值进行公式化。然而,当遍历性被打破时,长期结果取决于特定的轨迹,而不是整体平均值。在这种情况下,整体平均值与个体智能体经历的时间平均增长不同,期望值公式会产生系统性的次优策略。先前的研究表明,传统的RL架构无法在非遍历环境中恢复真正的最优解。本文将此分析扩展到深度RL实现,并表明它们在非遍历动态下也会产生次优策略。将显式的时间依赖性引入学习过程可以纠正此限制。通过允许网络的功能逼近包含时间信息,智能体可以估计与过程的内在增长率一致的价值函数。这种改进不需要改变环境反馈,例如奖励转换或修改目标函数,而是自然地来自智能体对时间轨迹的暴露。本文的研究结果有助于不断增长的关于非遍历系统强化学习方法的研究。
🔬 方法详解
问题定义:论文旨在解决深度强化学习(DRL)在非遍历环境中表现次优的问题。传统的DRL算法依赖于贝尔曼方程,该方程基于未来奖励的期望值。在遍历环境中,期望值能够很好地代表长期平均性能。然而,在非遍历环境中,个体智能体经历的实际时间平均增长与期望值不同,导致DRL算法收敛到次优策略。现有方法的痛点在于无法区分不同的时间轨迹,从而无法准确估计价值函数。
核心思路:论文的核心思路是将时间依赖性显式地引入DRL算法。通过让智能体感知当前的时间步,它可以学习到与特定时间轨迹相关的价值函数,从而更好地适应非遍历环境。这种方法的核心在于,价值函数不再仅仅是状态的函数,而是状态和时间的函数。
技术框架:该论文没有提出全新的DRL框架,而是在现有的DRL算法(如DQN、Actor-Critic等)的基础上进行改进。具体来说,就是在网络的输入中增加一个表示时间的变量。整体流程与标准的DRL算法相同,包括:1. 智能体与环境交互,收集经验数据;2. 使用经验数据更新价值函数或策略;3. 重复上述步骤,直到收敛。
关键创新:最重要的技术创新点在于将时间信息融入到价值函数的估计中。与现有方法相比,该方法不需要修改环境反馈(如奖励函数),而是通过改变智能体的学习方式来适应非遍历环境。这使得该方法具有更强的通用性和适用性。
关键设计:关键的设计在于如何将时间信息编码到网络输入中。一种简单的方法是将当前的时间步作为一个标量输入添加到状态向量中。另一种方法是使用周期性的时间编码(如正弦函数)来表示时间,这样可以更好地捕捉时间上的周期性变化。损失函数和网络结构与原始的DRL算法保持一致,无需修改。
🖼️ 关键图片

📊 实验亮点
论文通过实验验证了所提出的时间依赖DRL方法在非遍历环境中的有效性。实验结果表明,与传统的DRL算法相比,该方法能够学习到更优的策略,并取得更高的累积奖励。具体的性能提升幅度取决于具体的环境和任务,但总体上都优于基线方法。重要的是,该方法无需修改环境反馈,即可实现性能提升。
🎯 应用场景
该研究成果可应用于各种非遍历环境下的强化学习任务,例如金融交易、资源管理、个性化推荐等。在这些场景中,环境的动态特性会随着时间发生变化,传统的强化学习方法难以取得良好的效果。通过引入时间依赖性,可以提高智能体在这些复杂环境中的学习能力和决策水平,从而带来实际的经济和社会价值。
📄 摘要(原文)
Reinforcement Learning (RL) remains a central optimisation framework in machine learning. Although RL agents can converge to optimal solutions, the definition of ``optimality'' depends on the environment's statistical properties. The Bellman equation, central to most RL algorithms, is formulated in terms of expected values of future rewards. However, when ergodicity is broken, long-term outcomes depend on the specific trajectory rather than on the ensemble average. In such settings, the ensemble average diverges from the time-average growth experienced by individual agents, with expected-value formulations yielding systematically suboptimal policies. Prior studies demonstrated that traditional RL architectures fail to recover the true optimum in non-ergodic environments. We extend this analysis to deep RL implementations and show that these, too, produce suboptimal policies under non-ergodic dynamics. Introducing explicit time dependence into the learning process can correct this limitation. By allowing the network's function approximation to incorporate temporal information, the agent can estimate value functions consistent with the process's intrinsic growth rate. This improvement does not require altering the environmental feedback, such as reward transformations or modified objective functions, but arises naturally from the agent's exposure to temporal trajectories. Our results contribute to the growing body of research on reinforcement learning methods for non-ergodic systems.