Provably Safe Reinforcement Learning using Entropy Regularizer
作者: Abhijit Mazumdar, Rafal Wisniewski, Manuela L. Bujorianu
分类: cs.LG
发布日期: 2026-01-13
💡 一句话要点
提出基于熵正则化的安全强化学习算法,提升学习过程中的安全性和稳定性
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 安全强化学习 熵正则化 马尔可夫决策过程 在线学习 后悔界限
📋 核心要点
- 现有安全强化学习算法在学习过程中难以保证高概率的安全约束,尤其是在episode间存在较大变异性的情况下。
- 论文提出一种基于熵正则化的安全强化学习算法,通过熵正则化来约束策略空间,从而提高学习过程的稳定性和安全性。
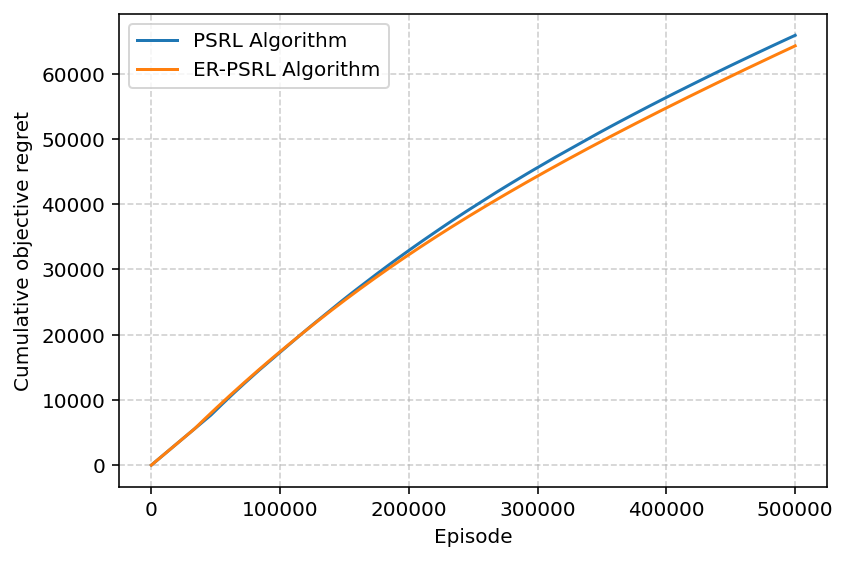
- 理论分析表明,该算法能够改善后悔值,并有效控制episode间的变异性,从而提升整体性能。
📝 摘要(中文)
本文研究了具有安全约束的马尔可夫决策过程(MDP)的最优策略学习问题,并在可达-避免(reach-avoid)框架下对问题进行了建模。目标是设计在线强化学习算法,以确保学习阶段具有任意高概率的安全约束。为此,首先提出了一种基于不确定性下的乐观(OFU)原则的算法。在此基础上,提出了主要算法,该算法利用了熵正则化。研究了两种算法的有限样本分析,并推导了它们的后悔界限。结果表明,包含熵正则化可以改善后悔值,并显著控制基于OFU的安全强化学习算法中固有的episode间变异性。
🔬 方法详解
问题定义:论文旨在解决具有安全约束的马尔可夫决策过程(MDP)中的最优策略学习问题。现有的安全强化学习算法,特别是基于OFU原则的算法,在学习过程中难以保证高概率的安全约束,并且episode间的变异性较大,导致学习过程不稳定。
核心思路:论文的核心思路是在OFU框架下引入熵正则化。熵正则化通过鼓励策略的探索性,避免过早收敛到次优策略,从而提高学习的稳定性和安全性。同时,熵正则化可以平滑策略分布,减少episode间的变异性。
技术框架:该算法基于OFU原则,首先构建MDP模型的不确定性集。然后,在每次迭代中,选择在不确定性集下最优的策略。为了保证安全约束,算法会检查当前策略是否满足安全要求,如果不满足,则进行调整。关键在于,在策略选择过程中,引入了熵正则化项,鼓励策略的探索性。整体流程包括:1. 构建不确定性集;2. 求解正则化后的最优策略;3. 执行策略并观察状态转移;4. 更新不确定性集。
关键创新:最重要的技术创新点在于将熵正则化引入到基于OFU的安全强化学习框架中。与传统的OFU算法相比,该算法能够更好地平衡探索与利用,提高学习的稳定性和安全性。熵正则化有效地控制了episode间的变异性,使得算法更加鲁棒。
关键设计:算法的关键设计包括熵正则化系数的选择。合适的熵正则化系数可以在探索和利用之间取得平衡。此外,算法还需要设计有效的安全约束检查和调整机制,以确保学习过程中的安全性。具体而言,可以通过定义一个安全集,并在每次策略更新后,检查新的策略是否仍然在安全集内。如果不在,则需要对策略进行调整,使其回到安全集内。
🖼️ 关键图片


📊 实验亮点
论文通过理论分析证明了所提出的基于熵正则化的安全强化学习算法能够改善后悔值,并有效控制episode间的变异性。具体的性能数据和对比基线在论文中进行了详细的展示,结果表明该算法在安全性和稳定性方面均优于传统的OFU算法。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、资源管理等领域,在这些领域中,安全性和稳定性至关重要。例如,在机器人导航中,可以利用该算法训练机器人安全地到达目标位置,同时避免碰撞等危险情况。在自动驾驶中,可以保证车辆在行驶过程中的安全性,避免发生交通事故。
📄 摘要(原文)
We consider the problem of learning the optimal policy for Markov decision processes with safety constraints. We formulate the problem in a reach-avoid setup. Our goal is to design online reinforcement learning algorithms that ensure safety constraints with arbitrarily high probability during the learning phase. To this end, we first propose an algorithm based on the optimism in the face of uncertainty (OFU) principle. Based on the first algorithm, we propose our main algorithm, which utilizes entropy regularization. We investigate the finite-sample analysis of both algorithms and derive their regret bounds. We demonstrate that the inclusion of entropy regularization improves the regret and drastically controls the episode-to-episode variability that is inherent in OFU-based safe RL algorithms.