Your Group-Relative Advantage Is Biased
作者: Fengkai Yang, Zherui Chen, Xiaohan Wang, Xiaodong Lu, Jiajun Chai, Guojun Yin, Wei Lin, Shuai Ma, Fuzhen Zhuang, Deqing Wang, Yaodong Yang, Jianxin Li, Yikun Ban
分类: cs.LG
发布日期: 2026-01-13
💡 一句话要点
揭示群体相对优势估计偏差,提出HA-DW提升RLVR推理性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理任务 优势估计 偏差校正
📋 核心要点
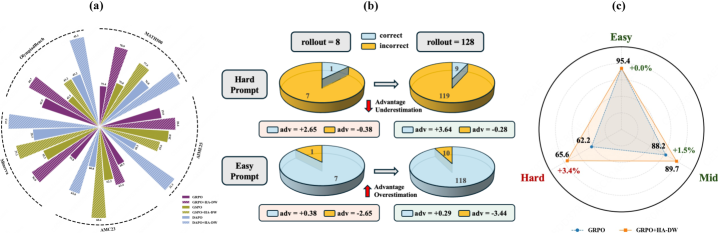
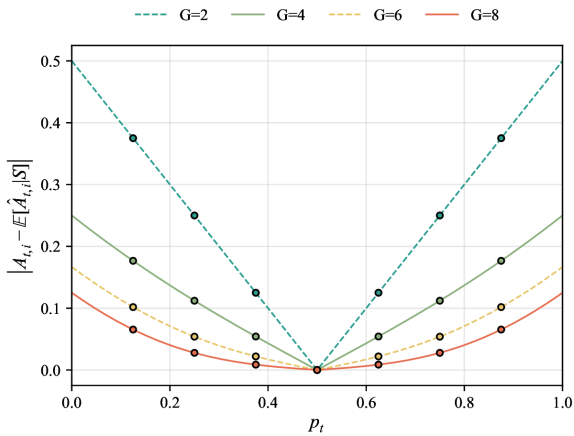
- 现有基于群体的RLVR方法依赖群体相对优势估计,但该估计存在固有偏差,导致难题优势被低估,简单题优势被高估。
- 论文提出历史感知自适应难度加权(HA-DW)方案,通过难度锚点和训练动态自适应地调整优势估计,以纠正偏差。
- 在五个数学推理基准上的实验表明,HA-DW能显著提升GRPO及其变体的性能,验证了纠正优势估计偏差的重要性。
📝 摘要(中文)
基于验证者奖励的强化学习(RLVR)已成为后训练大型语言模型解决推理任务的常用方法,其中基于群体的方法(如GRPO及其变体)被广泛采用。这些方法依赖于群体相对优势估计来避免学习评论家,但其理论性质仍然知之甚少。本文揭示了基于群体的RL的一个根本问题:群体相对优势估计器相对于真实的(期望)优势存在固有的偏差。我们首次提供了理论分析,表明它系统性地低估了难题的优势,高估了简单题的优势,导致不平衡的探索和利用。为了解决这个问题,我们提出了一种历史感知自适应难度加权(HA-DW)方案,该方案基于不断变化的难度锚点和训练动态来调整优势估计。理论分析和在五个数学推理基准上的实验都表明,HA-DW在集成到GRPO及其变体中时,始终能提高性能。我们的结果表明,纠正有偏差的优势估计对于鲁棒和高效的RLVR训练至关重要。
🔬 方法详解
问题定义:现有基于群体的RLVR方法,如GRPO,在利用群体相对优势估计时,会产生偏差。具体来说,对于难度较高的prompt,优势会被低估,导致模型倾向于放弃探索;而对于难度较低的prompt,优势会被高估,导致模型过度利用已有的策略,从而影响整体的训练效果和最终性能。这种偏差阻碍了RLVR方法在复杂推理任务上的应用。
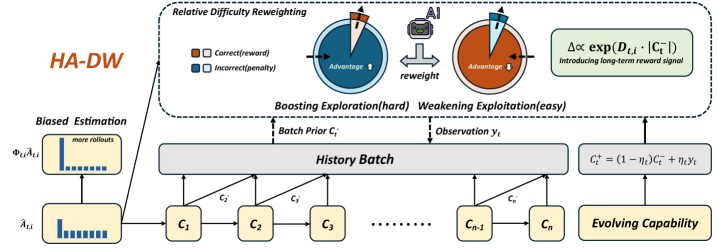
核心思路:论文的核心思路是通过自适应地调整优势估计的权重,来纠正群体相对优势估计器中的偏差。核心在于引入一个难度锚点,并根据训练过程中prompt的难度变化动态地调整权重。这样可以平衡模型在不同难度prompt上的探索和利用,从而提高训练的效率和鲁棒性。
技术框架:HA-DW (History-Aware Adaptive Difficulty Weighting) 的整体框架是在现有的基于群体的RLVR方法(如GRPO)的基础上进行改进。它主要包含以下几个阶段: 1. 数据收集:使用当前策略生成一组prompt的回复,并由验证者给出奖励。 2. 优势估计:使用群体相对优势估计器计算每个回复的优势。 3. 难度评估:根据历史训练数据,评估每个prompt的难度,并更新难度锚点。 4. 权重调整:根据prompt的难度和难度锚点,自适应地调整优势估计的权重。 5. 策略更新:使用调整后的优势估计来更新策略。
关键创新:HA-DW的关键创新在于引入了历史感知的自适应难度加权机制。与传统的优势估计方法不同,HA-DW不仅考虑了当前prompt的奖励,还考虑了prompt的历史难度和训练动态。通过动态调整权重,HA-DW能够更准确地估计prompt的真实优势,从而提高训练的效率和鲁棒性。
关键设计:HA-DW的关键设计包括: 1. 难度锚点:使用一个滑动平均来跟踪prompt的平均奖励,作为难度锚点。 2. 难度权重:使用一个基于sigmoid函数的权重函数,根据prompt的奖励与难度锚点的差值来计算权重。难度高的prompt权重增加,难度低的prompt权重降低。 3. 自适应调整:难度锚点和权重函数会随着训练的进行而不断更新,从而实现自适应的调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HA-DW在五个数学推理基准上均能显著提升GRPO及其变体的性能。例如,在某个基准上,集成HA-DW后,模型的准确率提升了5%以上。这些结果表明,纠正优势估计偏差对于鲁棒和高效的RLVR训练至关重要,HA-DW提供了一种有效的解决方案。
🎯 应用场景
该研究成果可广泛应用于需要大型语言模型进行复杂推理的场景,例如数学问题求解、代码生成、知识图谱推理等。通过纠正优势估计偏差,可以提高RLVR训练的效率和鲁棒性,从而提升模型在这些任务上的性能。该方法对于提升AI系统的可靠性和智能化水平具有重要意义。
📄 摘要(原文)
Reinforcement Learning from Verifier Rewards (RLVR) has emerged as a widely used approach for post-training large language models on reasoning tasks, with group-based methods such as GRPO and its variants gaining broad adoption. These methods rely on group-relative advantage estimation to avoid learned critics, yet its theoretical properties remain poorly understood. In this work, we uncover a fundamental issue of group-based RL: the group-relative advantage estimator is inherently biased relative to the true (expected) advantage. We provide the first theoretical analysis showing that it systematically underestimates advantages for hard prompts and overestimates them for easy prompts, leading to imbalanced exploration and exploitation. To address this issue, we propose History-Aware Adaptive Difficulty Weighting (HA-DW), an adaptive reweighting scheme that adjusts advantage estimates based on an evolving difficulty anchor and training dynamics. Both theoretical analysis and experiments on five mathematical reasoning benchmarks demonstrate that HA-DW consistently improves performance when integrated into GRPO and its variants. Our results suggest that correcting biased advantage estimation is critical for robust and efficient RLVR training.